Previously, I established my bespoke $\mu$P+Muon scheme for llama2 & mamba2.
Now, we arrive at the actual part of the work I care about – optimizing H-Nets across widths.
What could go wrong?
LR Modulation#
H-Net’s convoluted $\lambda^s = \sqrt{N^\text{GPT}\frac{\prod^S_{i=s}N^i}{\prod^S_{i=0}N^i}\frac{D^S}{D^s}}$ rule is just the application of 2 heuristics:
- $\eta\propto\frac{1}{\sqrt{D}}$
- Each hierarchy has a different model dim $D^s$.
- $\eta\propto\sqrt{\text{batch size}}$
- Each hierarchy of a H-Net consumes a fraction $\frac{\prod^S_{i=s}N^i}{\prod^S_{i=0}N^i}$ of the bytes
- $N^\text{GPT}$ is a constant, used in the paper to compare runs with the same bytes per batch. If LR is sweeped, it doesn’t matter.
For my purposes, I remove the $\frac{D^S}{D^s}$ component, as the $\mu$P setup accounts for it.
New modules#
In addition to the mamba2/transformer/lm blocks, H-Nets have the following extra parameters:
- routing $W_q$ and $W_k$
residual_proj$W_\texttt{res}$ (and bias, but let’s ignore it)pad_dimension(iff $d_s>d_{s-1}$)
Presumably, (1,2) will be trained with Muon, and (3) will be trained with adam.
Pad dim#
Goombalab does zero init for padding.
Initially, I thought this was bad, as it would violate $||\mathbf h_\ell||_2 = \Theta(\sqrt{d_s})$ on the inputs to deeper hierarchies. But, because the padded input $x_\texttt{pad}$ is only directly used by layers with prenorm, no weight matrix will encounter that violation.
If you did want to match $x_\texttt{pad}$ anyway, you would init pad_dimension as $\sigma\propto 1$. But I think there is little justification for doing so, and it is reasonable to assume the convention that has held since Spacebyte is not significantly detrimental.
In the future, it may be worth switching their cat/slice approach to explicit dim projections between hierarchies. But I am currently unwilling to modify H-Net’s architecture, so I simply treat it as an adam bias and carry on.
Routing module#
Both $W_q$ and $W_k$ are initialized as the identity matrix.
This logically makes sense – the routing mechanism is a comparison of pairwise $\texttt{cossim}(q_t,k_{t-1})$, so a reasonable place to start is to set $q = k = x$ and compare $x_t\leftrightarrow x_{t-1}$ directly.
[Sidenote] Why learn Wₖ?#
A natural question arises: if identity $q$/$k$ are reasonable choices at init, do we even need learnable $W_q$/$W_k$ at all?
Interestingly, there is a prior work from the computer vision space, ToMe, that uses a similar cosine similarity metric between tokens. In that work, they reuse $k$ from each attention layer to determine token selection per layer, and demonstrate that learned $k$ beats using raw $x$ significantly:

So, I can be reasonably confident that,
- pairwise cosine similarity is a good metric for 1D
- at least one learnable matrix is beneficial for selection.
It’s still reasonable to ask if you do need separate $W_q$ and $W_k$. I think the special case of learnable $W_k$ & identity $W_q$ should be no less expressive than H-Net’s original approach. But I leave modification of their architecture to future endevors.
Incidentally, $||\mathbf I_d||_* = 1 = \Theta(\sqrt{\frac{n_\ell}{n_{\ell-1}}})$, so $W_q,W_k$ satisfies the spectral condition with no effort on our part.
It’s possible adding a small amount of orthogonal noise to $W_q,W_k$ at init could improve performance, but I am not willing to test this.
P grads#
Traditional H-Net defines (for a hierarchy level $s$),
$$\begin{align*} \text{cossim}(a,b) &= \frac{a\cdot b}{||a||_2||b||_2} \\ p_t &= \frac{1-\text{cossim}(W_qx_{t-1},W_kx_t)}{2} \end{align*} $$And we’d like to make $\Delta p_t = \mathcal O(1)$ w.r.t. width $D_s$.
What influences pₜ?
(I think) $p_t$’s gradient is affected by 2 things:
- ratio loss, which is a flat penalty of $(NF-\frac{N(1-F)}{N-1})/\text{seqlen}$ for selected $p_t$
- cross entropy, which contributes
- (for all $p_t$) $(2b_t-1)\langle\frac{\delta L_\text{ce}}{\delta x_\texttt{dec}},\bar z_t \rangle$, where $\bar z_t$ is output of dechunk layer
- (for select $p_t$) something like $\langle \text{EMA}^{-1}(\frac{\delta L_\text{ce}}{\delta x_\texttt{dec}}), \hat z_t-\bar z_t \rangle$, idk
Assuming that,
- With non-parametric norms, we have guaranteed $||x_t||_2 = \Theta(\sqrt{d})$.
- With the spectral condition, we have $||q_t||_2 = \Theta(\sqrt{d}) = ||k_t||_2$ as well.
- With no alignment, $q_{t-1}\cdot k_t = \Theta(\sqrt d)$.
We will have $p_t=\Theta(\frac{1}{\sqrt d})$ at init.
And because
$$ \begin{align*} ||\frac{\delta p_t}{\delta k_t}||_2 &= -\frac{1}{2}||\frac{\delta\text{cossim}(q_{t-1},k_t)}{\delta k_t}||_2 \\ &= -\frac{1}{2}||\frac{k_t-\frac{q_{t-1}\cdot k_t}{||q_{t-1}||_2^2}q_{t-1}}{||q_{t-1}||_2||k_t||_2}||_2 \\ &= \Theta(\frac{1}{\sqrt d}) \end{align*} $$We can conclude $\Delta p_t = \langle \frac{\delta p_t}{\delta q_t}, \Delta q_t \rangle = \Theta(1)$
So $\Delta p_t = \Theta(1)$ iff $q_{t-1},k_t$ remains mostly unaligned across widths.
In the median case, that is always true, since a H-Net only “works” iff ~$\frac{N-1}{N}$ of all $t$ positions have $\text{cossim}(q_{t-1},k_t)\lt 0$.
But, in the general case, that does not work, and later we will discuss why.
Residual projection#
Like pad_dimension, $W_\texttt{res}$ is zero-initialized.
Unlike pad_dimension, this is well-motivated.
From the bible:
One additional detail is that this residual connection is initialized close to 0; earlier versions of H-Net found this to be an important detail, but it may be less important when combined with additional techniques such as LR modulation.
When $W_\texttt{res} = \mathbf 0$, the main network is forced to learn to improve $x_\texttt{dec}$, suppressing easy first-step gains from encoder byte-level prediction improvements alone.
If you use default kaiming uniform init instead, the network never encounters the initial ‘hockey-stick’ ratio loss spike in favor of the main network (higher loss -> more tokens in main net)

So it should be similarly problematic to switch to a $\sigma\propto\frac{1}{\sqrt d}$ init (which both STP and our spectral approximation will use in this $\mathbb R^{d\times d}$ case)
Now, obviously, $||\mathbf 0||_* = 0$, so a zeros init $W_\texttt{res}$ cannot satisfy the spectral condition, and $||\Delta x_\texttt{dec}||_2$ might not be $\Theta(\sqrt{d_s})$.
But it will be the case that $||x_\texttt{dec}||_2=\Theta(\sqrt{d_s})$ at init, due to the main net branch, and empirically this seems OK.
Norms#
Earlier, I described my use of non-parametric norms in conventional LLMs, where it has a negligible impact on performance.
And, initially, I expected this to hold for H-Net as well, because all of its norms are contained in the Isotropic block, which is equivalent to that of a standard LLaMA architecture.
However, this similarity is actually a programmatic sleight-of-hand. RMSNorms in H-Net do not serve the same purpose as they do in standard pre/post-norm transformer blocks.
While it is true that all norm scales in an $S=0$ H-Net can be subsumed into linear layers, this claim is not true once you start adding hierarchies.
The output norm of an isotropic actually serves 3 distinct roles in a H-Net
- as a final $\text{LMHead}(\text{RMSNorm}(x))$, in the outermost decoder ($S>0$) OR main network ($S=0$)
- We could make these trainable via the $\eta_\gamma\propto\frac{1}{\sqrt{d}}$ solution I proposed much earlier, but that is not necessary.
- as the encoder’s outputs, for the conjoined purposes of
- routing module stability
- invariant of each hierarchy starting with $\Theta(1)$ inputs
- ensuring only $W_\texttt{res}$ decides how much the encoder contributes to $x_\texttt{dec}$
- to stabilize residual contribution to $x_\texttt{dec}$, in the main network (innermost $s=S-1$) OR decoder ($s\in[1,S-2]$).
Let us focus a bit on case (3).
$$ x_\texttt{dec} = y_\texttt{enc}W_\texttt{res} + \text{dechunk}(\text{M}(y_\texttt{enc}\texttt{.masked\_select(...)}) $$Both $y_\texttt{enc}$ and $M(...)$ are normalized. The dechunk EMA shrinks variance a bit on average, but not by much.
If $\text{RMS}(W_\texttt{res})$ grows, it is not possible for the outputs of the main net to grow its own RMS to match. Most likely, the main net will start painfully producing gigantic outlier coordinates to pass information out, which will destroy models in the long run.
So, if we want to avoid this, we need to either
- specifically for case (3), make the final norms of each Isotropic layer trainable
- use a linear production to map from deeper to shallow hierarchies, instead of just dim slicing.
I pick the former option. And in this case, to match the update speed of $W_\texttt{res}$, we should use $\eta_\gamma\propto 1$.
TLDR#
Our first stab at H-Net $\mu P$ adopts the following:
pad_dimension, residual bias: zeros && adam bias lr- norm scales: ones init && 0LR OR adam bias lr (only for residual contributing isotropics)
- $W_\texttt{res}$: zeros init and muon update
- $W_q,W_k$: identity init and muon update
Does it work?
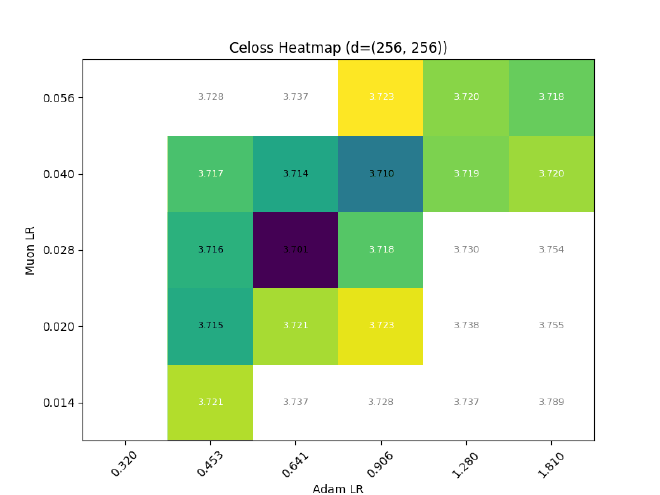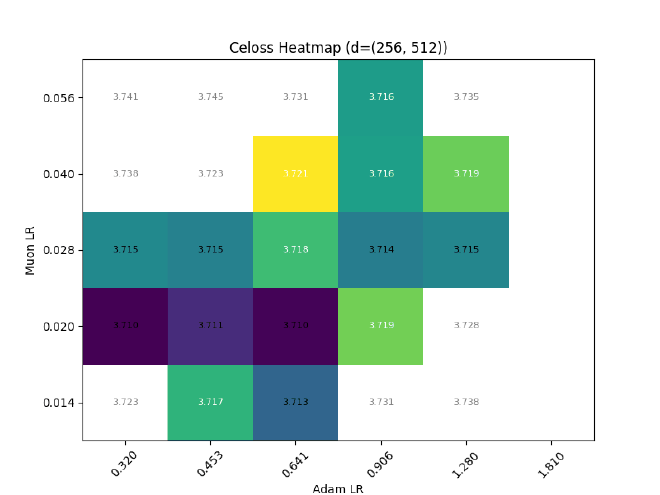
Nope. What gives?
Premise#
Let’s first establish what is desired from “muP H-Net”.
Given a H-Net of $S$ hierarchies, with model dimensions $D_0\le...\le D_{S-1}$, and fixed batch size / layer count / step count,
- I should only need to sweep global base values $[\sigma, \eta_\text{muon}, \eta_\text{adam}]$ to achieve reasonably competitive performance (bpb) for fixed base dimensions $d_0,d_1,...,d_{S-1}$
- The optimal base values should also be optimal for arbitrary $D_0...D_{S-1}$.
Sounds good? It shouldn’t. Here are a few problems:
Compression at Init#
Consider the following wrong premise:
- The encoder starts with an output RMSNorm, guaranteeing $y_\texttt{enc}\sim N(0,1)$.
- The routing module uses identity init, giving $q_t = k_t = y_\texttt{enc} \sim N(0,1)$
- At init, uncorrelated $q_{t-1},k_t$ should give $\mathbb E[\text{cossim}(q_{t-1},k_t)]\approx 0$,
- $\therefore$ the base $\sigma$ used has negligible impact on compression ratio at init.
Then, consider the following empirical plot:
The expectation in (3) works when $\sigma$ is small, causing the encoder layers to contribute minimally to $y_\texttt{enc}$ at init, making $\text{L1:L0}$ start off at approximately 1/2.
Conversely, high $\sigma$ + prefix-scan/conv1d causes more correlation out-of-the-box, bringing the starting compression ratio to a negligible value, which generally never goes back up. This dooms all high σ runs && forces HEBO to search for lower $\sigma$ solutions.
I only noticed this extremely late into research, so I never piloted any solutions for it. But
- it should be analytically solvable given the exact encoder dims
- it is ’naturally’ solved-by-accident with forced compression, which gives the main network exposure time
Instability at low step counts#
In an average small-scale H-Net run, it takes 500+ steps for ratio loss to stabalize close to 1.
That means, that if your $\mu P$ sweeps are done in a very short step regime (I used 1000 steps for baselines), the majority of your run’s updates will be dominated by the starting dynamics of routing stability.
The best hparams under that regime are very unrepresentative of what occurs in ‘real’ H-Nets runs (of $O(100,000)$ steps), where compression factor should be extremely stable.
So, my perspective here is:
- traditional H-Net hparam sweeping is misleading if done with $\text{steps} \lt 5000$
- Ideally, the architecture should be modified to have stable token consumption at all steps.
Infeasibility of consistent bsz#
It is not possible to make a traditional H-Net consume the same number of tokens per step. The model decides how many tokens the inner nets get to see; traditional fixed batch size mup is intractable with H-Net.
In a simple width transfer test ($D_{0,1}={256,256}\rightarrow{256,512}$), the learning trajectory of routing selection will change, which changes the tokens visible to the inner main network, which butterfly-effects the entire training run:
Now, to be clear, these aren’t “huge” instabilities. But it definitely destroys any possibility of direct hparam transfer, without accounting for the shift in routing choices w.r.t. width.
And if you’ve read my Intuitions, you’ll know that it’s wrong to try to fight compression ratio in this regard – the model deviates from target compression when it’s better for performance.
P grads (again)#
Earlier, I claimed:
So $\Delta p_t = \Theta(1)$ iff $q_{t-1},k_t$ remain mostly unaligned across widths… in most cases, they should remain unaligned as our H-Net is only “working” iff $\text{cossim}(...)<0$ for $\frac{N-1}{N}$ of $t$ positions.
But this is a self-defeating premise. Iff H-Nets are really true dynamic tokenizers, then you would expect increases in model capacity to adjust the alignment of $q_{t-1},k_t$, to enable a shift in chunk size towards what’s optimal.
So,
🙁
Proposed solutions#
I roughly see 3 ‘classes’ of solutions for the above:
- Forced compression ratio
- LR adjustments
- Pretrained encoders
Here’s how they work.
Forced compression#
Even if you empirically understand ratio loss should not be fucked with, it’s tempting to try.
Typically, sweeps over global LR parameters directly adjust the curvature of the hockey-stick at the start of a run, like this:
- lower muon LR -> slower $W_{q,k}$ updates -> longer dragged hockey stick (which is lowest first valley & highest first peak)
- higher adam LR also causes the same thing. not very sure why
So, that’s very bad for short run equivalence. What can we do?
Obvious bad approach#
A natural first question to ask is if any of this even matters. Is this instability really what’s stopping $\mu$P?
It’s quite easy to force the issue on this particular task – just hardcode compression ratio:
| |
Now, obviously, this breaks causality, and cannot ever be used in a real H-Net run.
But for research purposes, it helps to answer the question of what is crippling $\mu$Transfer.

“Yes”, in the sense that optimal LR doesn’t drift away.
“No”, because the results are fucked – loss increases with width, instead of the other way around…

More bad approaches#
I cycled through many bad ideas in pursuit of init stability. Here are some of them:
Deepseek-inspired loss free
Inspired by Deepseek, I implement the following simple alternative to routing loss:
| |
In a single test run, this both (A) made compression factor more stable and (B) provided no difference in loss:

Does it work in the general case?

No, because I clamp updates within [.1,.9] for numerical stability, and it is easy for bad runs to increase/decrease $p_t$ far beyond that.
With infinite precision, balancing should ‘work’. But:
- actual bf16 will quickly saturate and cause routing to become increasingly volatile
- you don’t actually want to do this for the aforementioned reasons of respecting H-Nets that override ratio loss
Balanced loss weight
Another obvious approach is to grow the magnitude of the routing loss grads together with the influence of celoss.
This can be achieved with a similar scheme that balances $\mathcal L_\text{ratio}$’s $\alpha$ directly, instead of adjusting routing threshold:
| |
But it does not improve results (1e17 also crashed a bit):

And, once again: this is because forcing a model to do more compression is bad
Both of them were failures, unlike the next idea:
Not wrong approach#
One basic scheme to force compression stability is to adjust the >=0.5 threshold based on previous step statistics:
| |
This has to be done with a distinction between “fake” and “real” $b_t$, to still give ratio loss / STE the same routing signals:
| |
Do that, and compression at init will become much more stable without changing behavior after the step threshold (much)
Note that, in the above runs,
- logs happen every 5 iters, so the cutoff for regressing to original H-Net is at “step”=200.
- The green line is with the diff above; the yellow line is a separate case where I move up
update_threshto be causality-breaking, to ~no change.
In any case, the intervention causes the hockey-stick to flatten out:

But, problematically, there is still a wide variation of compression in the long run:

As per usual, lower muon LR -> slower ascent of compression to target 0.2. This causes all of the runs below a certain muon LR to strongly underperform:

So, mild force compression is not enough. What’s next?
$\mu$P failure aside, the above scheme is actually really useful for solving an unrelated engineering issue: vram constraints at the start of a H-Net run.
The thresholding scheme makes the peak inner network batch size much closer to the target compression ratio, for every step other than 0.
For step 0, you can approximate a better initialization as
$$\texttt{thresh} = (1+\frac{\Phi^{-1}(1 - 1/N)}{\sqrt{d}})/2$$Where $\Phi^{-1}$ is ndtri. But this will either under/overshoot the target, depending on your encoder’s init std.
LR adjustment#
Two subideas here.
Segregated routing LR#
One reasonable problem you might expect from tying $W_q,W_k$ LR to the LR of all other matrices, is that minute improvements in learning speed to the main network in general may end up overshadowed by the router ‘adversarially’ learning to route worse for the main network.
So, having a separate LR group for them (and other routing-related parameters like $W_\texttt{res},\gamma_m$) may help to stabalize the search space for best LR of other parameters.
Of course, this doesn’t help if optimal hparams aren’t width invariant to begin with, but you could imagine this helping after that problem gets solved.
Dynamic LR modulation#
Instead of the fixed $N$-based LR modulation rule, we could dynamically adjust each hierarchy’s LR based on the active number of tokens seen.
Arguably, doing so would be more principled than the static LR modulation approach based on target compression factor.
But I don’t bother attempting this, as it’s highly unlikely this adjustment will fix anything, given the variation in batch size (with the thresh update trick) is on the order of ±10%.
Pretrained encoder#
If learning a good chunk mechanism at init is a fundamental issue, why not just use a pretrained encoder+routing?
To be specific, you would:
- load all weights above a certain hierarchy level – including $W_\text{res},W_\text{emb},W_\text{out}$ – from a pretrained H-Net checkpoint
- freeze or otherwise very gently warmup those weights for many steps (as the decoder provides strong language modelling ootb)
Sketch effort
Let’s say you want to take cartesia’s stage1_XL encoder, and use it to $\mu$P to a reasonably mid-sized LLM.
You would start by sweeping hparams with a $D=[1024,1024]$ model, which:
- copies prior work for best mamba2/transformer $\mu$P scheme
- uses the scheme above for other H-Net modules
- is warmed up with cosine-decayed threshold tracking.
- loads
stage1_XL’s weights for the enc/dec, and keeps them frozen.
Then, with those hparams, you would expand to larger $D_1$.
Does that work?

Well, no, because I used a parametric output norm, which predictably causes leftwards $\eta_\text{adam}$ drift under my setup. But this should be fixable if you replace the norm scale with a down projection instead.
And sure, some variant of that idea probably works. But this is not a desirable outcome.
The whole point of H-Net is to provide end-to-end hierarchical language modelling, and to avoid regressing towards multistage training pipelines that complicate the research process.
Nonetheless, it seems to be the simplest strategy to square the circle of wanting dynamic tokenizers & wanting $\mu$P. So I make the following repulsive recommendation to future practitioners:
Conclusions#
- End-to-end H-Nets are a poor fit for $\mu$P.
- Although ugly, separate ‘pretrained tokenizers’ will work.
Future researchers may consider investigating the following:
- Finding errors in the above text to enable $\mu$transfer with end-to-end H-Nets
- Taking inspiration from other generative modalities on how to best balance enc/dec vs main network compute
- Emailing
support@cartesia.aifor help