This weekend, I evaluated (tried) 5090 matmul performance due to a tweet.
Raw mma perf#
mmapeak is a simple tensor core benchmarking utility.
| |
It does N_LOOP_INTERNAL=8192 iterations of mma.synced.aligned.* instructions on zeros living in register memory. See here for an mxf8 @ mxf8 -> f32 example.
On a 5090, I obtain:
| A Type | B Type | Shape | 32bit acc | TFlops | Spec | Spec/MMAPeak |
|---|---|---|---|---|---|---|
| int4 | int4 | 8x8x32 | int32 | 79.3 | 1676 (?) | 0.05 |
| mxf4 | mxf4 | 16x8x64 | ✅ | 1474.2 | 1676 | 0.88 |
| nvf4 | nvf4 | 16x8x64 | ✅ | 1474.2 | 1676 | 0.88 |
| f4 | f4 | 16x8x32 | ❌ | 369.5 | 1676 (?) | 0.22 |
| f4 | f4 | 16x8x32 | ✅ | 369.6 | 1676 | 0.22 |
| f6 | f6 | 16x8x32 | ❌ | 369.4 | 838 (?) | 0.44 |
| f6 | f6 | 16x8x32 | ✅ | 369.6 | 419 (?) | 0.88 |
| mxf6 | mxf6 | 16x8x32 | ✅ | 369.7 | 419 (?) | 0.88 |
| mxf8 | mxf8 | 16x8x32 | ✅ | 737.1 | 419 | 1.76 |
| f8 | f8 | 16x8x32 | ❌ | 737.1 | 838 | 0.88 |
| f8 | f8 | 16x8x32 | ✅ | 370.0 | 419 | 0.88 |
| int8 | int8 | 16x16x16 | int32 | 745.7 | 838 | 0.89 |
| int8 | int8 | 32x8x16 | int32 | 745.8 | 838 | 0.89 |
| f16 | f16 | 16x16x16 | ❌ | 745.8 | 419 | 1.78 |
| f16 | f16 | 32x8x16 | ❌ | 745.9 | 419 | 1.78 |
| f16 | f16 | 16x16x16 | ✅ | 370.6 | 209.5 | 1.77 |
| f16 | f16 | 32x8x16 | ✅ | 370.6 | 209.5 | 1.77 |
| bf16 | bf16 | 16x16x16 | ✅ | 370.6 | 209.5 | 1.77 |
| bf16 | bf16 | 32x8x16 | ✅ | 370.6 | 209.5 | 1.77 |
| tf32 | tf32 | 16x16x8 | ✅ | 92.8 | 104.8 | 0.89 |
A few things stand out:
- int4 gemm is gone on blackwell. RIP
- unscaled f4/f6 performance is trash, idk why.
- f16/bf16/mxf8 performance is ridiculously high. Enough to drastically shift GPU prices worldwide if true.
But, if the 5090 was so powerful out-of-the-box, it would have been discovered already. So there must be some catch.
torch.matmul#
Since no one has sang prayers for the greatness of the 5090 yet, it is likely a simple matmul benchmark will show substantially worse numbers.
We can use the SemiAnalysis™️ Nvidia Matmul Benchmark for this. After running python matmul.py:
| M, N, K | bf16 torch.matmul | FP8 torch._scaled_mm (e5m2/e4m3fn) | FP8 torch._scaled_mm (e4m3) |
|---|---|---|---|
| (16384, 8192, 1280) | 224.3 TFLOPS | 448.8 TFLOPS | 443.5 TFLOPS |
| (16384, 1024, 8192) | 183.1 TFLOPS | 402.2 TFLOPS | 400.3 TFLOPS |
| (16384, 8192, 7168) | 228.1 TFLOPS | 449.6 TFLOPS | 446.5 TFLOPS |
| (16384, 3584, 8192) | 228.0 TFLOPS | 439.2 TFLOPS | 435.5 TFLOPS |
| (8192, 8192, 8192) | 220.5 TFLOPS | 443.4 TFLOPS | 441.9 TFLOPS |
These numbers are more boring. Against spec, they’re perhaps 5% better than anticipated.
Why?
Reasons for divergence#
A chasm of complexity exists between:
- a script that happens to use torch.matmul frequently
- a program which repeatedly executes matrix-multiply-add on the same tile of zeros
And so, maybe you’d wonder:
- does the script correctly track GPU kernel timings, without any CPU overhead?
- do the high level APIs ultimately make use of well-optimized matmul kernels?
- is the arithmetic intensity of typical problem sizes high enough for the 5090?
- will is the benchmark actually doing what it claims to do?
But the answer to all of those questions are probably, ‘yes’.
The real problems are different.
Distributional differences#
Going back to torch.matmul – if I simply change all tensors (and scales) to be zeros, this happens:
| Shape (M, N, K) | bf16 torch.matmul | FP8 torch._scaled_mm (e5m2/e4m3fn) | FP8 torch._scaled_mm (e4m3) |
|---|---|---|---|
| (16384, 8192, 1280) | 227.9 TFLOPS | 471.7 TFLOPS | 471.8 TFLOPS |
| (16384, 1024, 8192) | 185.6 TFLOPS | 422.0 TFLOPS | 422.1 TFLOPS |
| (16384, 8192, 7168) | 238.1 TFLOPS | 487.0 TFLOPS | 486.6 TFLOPS |
| (16384, 3584, 8192) | 236.2 TFLOPS | 473.3 TFLOPS | 473.3 TFLOPS |
| (8192, 8192, 8192) | 228.7 TFLOPS | 476.1 TFLOPS | 476.1 TFLOPS |
There, there is some change, but certainly nowhere near the gap required to obtain 370TFLOPs on bf16. So, power usage is probably not the problem.
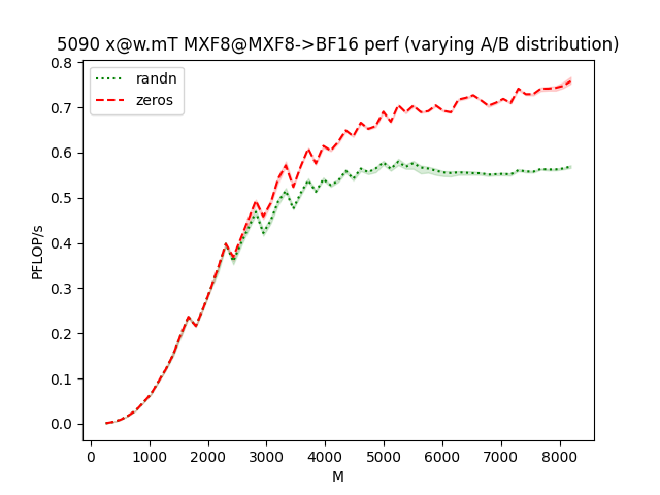
But then, if I make a simple edit to mmapeak, to change the initialization of the input problem from zeros to randn, the performance benefits of the half precision cases appear to vanish:
| |
So, what is happening? Is my LLM-powered CUDA edit wrong? Is torch.matmul bottlenecked by memory bandwidth?
Honestly, no idea. I ran out of time for the weekend. Feel free to continue investigating in lieu of me.
Software notes#
I was interested in getting the MXFP8 performance out of 5090s, so I tried the following:
Triton#
Recently, a Block Scaled Matrix Multiplication tutorial was added to triton.
If you use the version of triton pinned to torch nightly, it will fail, due to missing imports.
If you build triton from source, it will also fail, as the compiled result is compatible with sm100 only. I lost the error logs for this after my runpod instance crashed.
CublasLt#
In the latest version of CUDA, CublasLt’s block-scaled matmul routines will currently fail on sm120 devices with a CUBLAS_STATUS_NOT_SUPPORTED error.
This is why TransformerEngine recently banned non-TN fp8 GEMMs from 5090s.
Torchao#
Torchao has recently implemented an MXTensor primitive, to seamlessly support training with block-scaled floating point tensors.
It has 3 compute backends:
- emulated, which simply implements upcast + matmul
- cublas, which is broken for the aforementioned reason
- cutlass, which has sm100 hardcoded into torchao.
The lastmost point should be fixed in the future, as there is a clear cutlass example of MXFP8 GEMMs on geforce.
torch._scaled_mm#
The _scaled_mm method dispatches on the likeness of the provided scale_a/scale_b:
- scalar ->
ScalingType::TensorWise - float8 ->
ScalingType::BlockWise - fp32,
[m,1]/[1,n]shaped ->ScalingType::RowWise
Tensor-wise and Row-wise are both traditional hopper-style pure fp8 mma + dequant kernels, which means they fall into the low-performing f8 mma bucket, which means they are useless for gamers
The block-wise matmul implementation in torch uses cublas, which is broken for the aforementioned reason.
Appendix: dependencies#
For all experiments, I use a single Runpod 5090 instance, with image runpod/pytorch:2.8.0-py3.11-cuda12.8.1-cudnn-devel-ubuntu22.04.
After booting, I apt update–>install asciinema neovim cmake zlib1g-dev, and separately uv + micromamba.
Most of the time, the container’s pytorch packages are too old, and I install the following nightly packages:
| |
Where appropriate, I build pytorch with a fresh micromamba python=3.11 environment.