In torch’s FSDP/FSDP2 MixedPrecision APIs, there’s a reduce_dtype config flag:
| |
Why does it exist? Does it even matter? What do people typically use?
Common usage#
A typical application of FSDP/2 looks like this:
| |
| |
bf16/fp16, both mixed precision APIs are structured to convince a casual FSDP user to syncronize gradients in half precision as well.Does that make it a sane default? Maybe. But strangely, torchtitan, another PyTorch project, has hardcoded their reduction dtype to fp32. So maybe it doesn’t work?
…
Conversely, in pure DDP training, the situation is flipped. Most DDP trainers still apply autocast for mixed precision, instead of the obscure _MixedPrecision API that was implemented 2 years ago. Note that autocast doesn’t communicate in low precision in the absence of specific communication hooks, so most users of DDP will syncronize gradients in single precision, regardless of whether they mean to:
| |
| |
So, basically, the average PyTorch user doesn’t give a shit and will sync in whatever precision PyTorch defaults to on a specified parallelism scheme.
Is that bad?
Who even cares?#
To be clear, when discussing the role of precision in gradient reduction,
- we are not talking about the precision of the compute kernels used in the backward pass (which will be
bf16/fp16either way), - nor are we discussing the storage format used for local gradients (which matches master weights precision, which should be
fp32).
The only difference we’re talking about is an up/down cast in-between a distributed sum:
| |
When I first expressed this information to a fellow PyTorch user, his first reaction was denial that the premise should even matter:
if the stuff u r adding is alr bf16 then how does adding in fp32 works […] even if u do the addition in fp32, it wont increase any precision
Fair enough, right? Why the fuck should this even matter at all. After all,
Isn’t the sum identical?#
Intuition says that,
| |
should be true – any accuracy obtained by the higher precision sum on the right-hand-side should be eliminated by the subsequent bf16 cast.
This is generally true in the 2-sum case. Unfortunately, it’s not hard to come up with a counter-example if you allow for 3 or more elements in the sum:
| |
In general, \(A_\text{bf16} + B_\text{bf16} + C_\text{bf16} \ne (A_\text{fp32} + B_\text{fp32} + C_\text{fp32})_\text{bf16}\).
Okay, but what about reality?#
The 3-sum case is an unrealistic toy problem: with two values of very large magnitude, and one of very small scale.
$$ \sum_{r=0}^R (w_r/R) $$That is to say, the allreduce can underflow, but will never overflow. There are edge cases where torch will do some pre-scaling, but I don’t really care about them.
I’m also choosing to ignore the very real fact that allreduce && reducescatter ops are not actually implemented via ring reductions in NCCL in 2024. To my knowledge, double binary trees are used for sufficiently large allreduce ops, and more recently a variant of Bruck’s algorithm is used for reduce-scatter calls in the most recent release of NCCL. Additionally, the use of SHArP in infiniband switches produces indeterministic garbage under a scope I am ill-equipped to elaborate on.
Also, none of this paragraph applies for any serious frontier lab, because all of them use more efficient collective communications libraries, e.g. HFReduce, MSCCL++, NCCLX, etc. So, you know, I am just making unprincipled simplifications here, don’t read too hard into the assumptions or you’ll crack them like eggshells.
To model the divergence in half precision vs full precision reductions, I created a simple script to plot the variance of the difference between a hypothetical bf16 ring-reduce vs an fp32 ring-reduce:
| |
Here are the results:
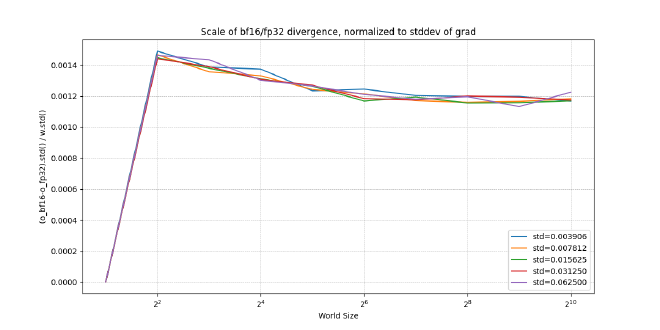
As you can see, the stddev did not increase with scale. As I was not expecting these results, and am unable to further explain them, I will put up a semantic stopsign for myself here and end the blogpost.
Conclusion#
I don’t understand why reduction precision matters.