Background#
Previously we looked at two allreduce algorithms based on ring and tree. For ring allreduce, data needs to go through all ranks during the reduce scatter phase and again through all ranks during the allgather phase. For tree allreduce, data needs to travel upward to the root node during the reduce phase and then back down during the broadcast phase, making the entire process quite lengthy.
SHARP#
To address this, Mellanox proposed SHARP, which offloads computation to the IB switch. Each node only needs to send data once, which is then reduced by the switch, and nodes receive the complete result after one more receive operation.
Figure 1 shows a fat-tree physical network topology, where green nodes represent switches and yellow nodes represent hosts.
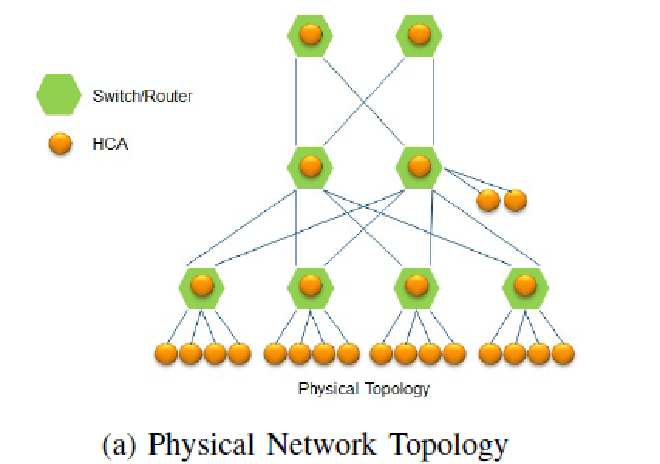
Figure 1
Figure 2 shows the SHARP tree derived from the physical network topology in Figure 1 after these host nodes execute SHARP initialization. The SHARP tree is a logical concept and doesn’t require the physical topology to be a fat-tree.
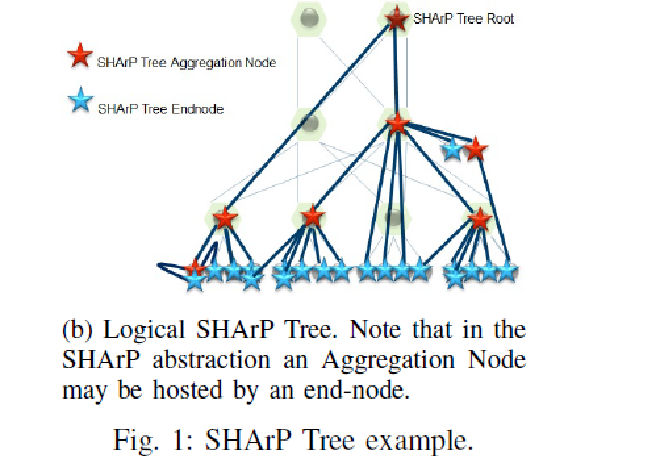
Figure 2
Notable points:
- A single switch can be part of up to 64 SHARP trees
- A SHARP tree can establish many groups, where a group is a subset created from existing hosts
- Supports concurrent execution of hundreds of collective communication APIs
Overall Process#
This article is based on 2.7.8. Similar to tree allreduce, intra-machine communication remains a chain. Using two machines as an example, data transmission follows the direction of arrows in Figure 3, and after the switch computes the complete result, it flows back in the opposite direction.
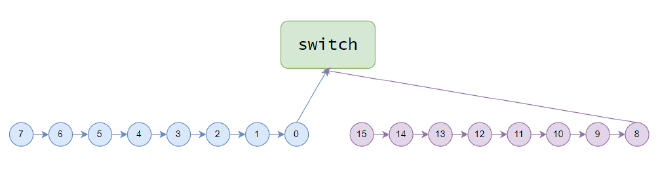
Figure 3#
Initialization#
Running IB SHARP depends on libnccl-net.so, which is open-source at https://github.com/Mellanox/nccl-rdma-sharp-plugins. This article is based on v2.0.1.
After NCCL completes bootstrap network initialization, it begins initializing the data network
ncclResult_t initNetPlugin(ncclNet_t** net, ncclCollNet_t** collnet) {
void* netPluginLib = dlopen("libnccl-net.so", RTLD_NOW | RTLD_LOCAL);
...
ncclNet_t* extNet = (ncclNet_t*) dlsym(netPluginLib, STR(NCCL_PLUGIN_SYMBOL));
if (extNet == NULL) {
INFO(NCCL_INIT|NCCL_NET, "NET/Plugin: Failed to find " STR(NCCL_PLUGIN_SYMBOL) " symbol.");
} else if (initNet(extNet) == ncclSuccess) {
*net = extNet;
ncclCollNet_t* extCollNet = (ncclCollNet_t*) dlsym(netPluginLib, STR(NCCL_COLLNET_PLUGIN_SYMBOL));
if (extCollNet == NULL) {
INFO(NCCL_INIT|NCCL_NET, "NET/Plugin: Failed to find " STR(NCCL_COLLNET_PLUGIN_SYMBOL) " symbol.");
} else if (initCollNet(extCollNet) == ncclSuccess) {
*collnet = extCollNet;
}
return ncclSuccess;
}
if (netPluginLib != NULL) dlclose(netPluginLib);
return ncclSuccess;
}
First, it dlopens libnccl-net.so, where NCCL_PLUGIN_SYMBOL is ncclNetPlugin_v3 and NCCL_COLLNET_PLUGIN_SYMBOL is ncclCollNetPlugin_v3, so it gets the symbol ncclNetPlugin_v3 for extNet and ncclCollNetPlugin_v3 for extCollNet. The relationship between extNet and extCollNet is similar to NCCL’s bootstrap network and data network relationship, where extCollNet handles actual data communication while metadata and control information are exchanged through extNet.
Then it executes extNet initialization. extNet supports multiple backends like ib and ucx. We’re using ib, so all subsequent execution is targeting ibPlugin. ibPlugin’s logic is similar to NCCL’s ncclNetIb logic - initialization (ncclIbInit) enumerates all network cards on the current machine and saves them to a global array.
Then it executes initCollNet, which is ncclSharpInit, which also executes ibPlugin initialization, but since this was already done, nothing happens here.
Graph Search#
struct ncclTopoGraph collNetGraph;
collNetGraph.id = 2;
collNetGraph.pattern = NCCL_TOPO_PATTERN_TREE;
collNetGraph.collNet = 1;
collNetGraph.crossNic = ncclParamCrossNic();
collNetGraph.minChannels = collNetGraph.maxChannels = ringGraph.nChannels;
NCCLCHECK(ncclTopoCompute(comm->topo, &collNetGraph));
The pattern is NCCL_TOPO_PATTERN_TREE, so intra-machine remains ring, but unlike NCCL_TOPO_PATTERN_SPLIT_TREE, in NCCL_TOPO_PATTERN_TREE the 0th GPU handles both network card send and receive. Assume the searched channels are as follows:
NET/0 GPU/0 GPU/1 GPU/2 GPU/3 GPU/4 GPU/5 GPU/6 GPU/7 NET/0
Channel Connection#
After graph search completes, channel connection begins, which records adjacent nodes for the current node
ncclResult_t ncclTopoPreset(struct ncclComm* comm,
struct ncclTopoGraph* treeGraph, struct ncclTopoGraph* ringGraph, struct ncclTopoGraph* collNetGraph,
struct ncclTopoRanks* topoRanks) {
int rank = comm->rank;
int localRanks = comm->localRanks;
int nChannels = comm->nChannels;
for (int c=0; c<nChannels; c++) {
struct ncclChannel* channel = comm->channels+c;
int* collNetIntra = collNetGraph->intra+c*localRanks;
for (int i=0; i<localRanks; i++) {
if (collNetIntra[i] == rank) {
int prev = (i-1+localRanks)%localRanks, next = (i+1)%localRanks;
channel->collTreeDn.up = collNetIntra[prev];
channel->collTreeDn.down[0] = collNetIntra[next];
channel->collTreeUp.down[0] = channel->collTreeDn.down[0];
channel->collTreeUp.up = channel->collTreeDn.up;
}
}
}
// Duplicate channels rings/trees
struct ncclChannel* channel0 = comm->channels;
struct ncclChannel* channel1 = channel0+nChannels;
memcpy(channel1, channel0, nChannels*sizeof(struct ncclChannel));
return ncclSuccess;
}
Assuming 10 channels were found, the first 5 channels are used for SHARP’s upward phase (direction of arrows in Figure 3), and the latter 5 channels for the downward phase (opposite direction). So each channel records two connection relationships: collTreeUp and collTreeDn. The first 5 upward channels only use collTreeUp, the latter 5 downward channels only use collTreeDn, but collTreeUp and collTreeDn are actually identical. We’ll only discuss collTreeUp going forward.
After intra-machine channel connection, it looks like Figure 4, with arrows pointing up.
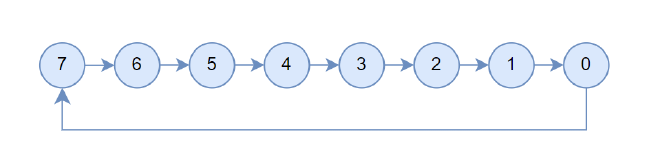
Figure 4#
Then inter-machine connection begins, which selects ranks responsible for network send/receive within machines. Taking sending as an example, this is called sendIndex, and its intra-machine connections need to be broken, as well as connections to sendIndex.
ncclResult_t ncclTopoConnectCollNet(struct ncclComm* comm, struct ncclTopoGraph* collNetGraph, int rank) {
int nranks = comm->nRanks;
int depth = nranks/comm->nNodes;
int sendIndex = collNetGraph->pattern == NCCL_TOPO_PATTERN_TREE ? 0 : 1; // send GPU index depends on topo pattern
int sendEndIndex = (sendIndex+comm->localRanks-1)%comm->localRanks;
for (int c=0; c<comm->nChannels/2; c++) {
struct ncclChannel* channel = comm->channels+c;
// Set root of collTree to id nranks
if (rank == collNetGraph->intra[sendIndex+c*comm->localRanks]) { // is master
channel->collTreeUp.up = channel->collTreeDn.up = nranks;
}
if (rank == collNetGraph->intra[sendEndIndex+c*comm->localRanks]) { // is bottom of intra-node chain
channel->collTreeUp.down[0] = channel->collTreeDn.down[0] = -1;
}
channel->collTreeUp.depth = channel->collTreeDn.depth = depth;
INFO(NCCL_GRAPH, "CollNet Channel %d rank %d up %d down %d", c, rank, channel->collTreeUp.up, channel->collTreeUp.down[0]);
}
int recvIndex = 0; // recv GPU index is always 0
int recvEndIndex = (recvIndex+comm->localRanks-1)%comm->localRanks;
for (int c=0; c<comm->nChannels/2; c++) {
struct ncclChannel* channel = comm->channels+comm->nChannels/2+c;
// Set root of collTree to id nranks
if (rank == collNetGraph->intra[recvIndex+c*comm->localRanks]) { // is master
channel->collTreeUp.up = channel->collTreeDn.up = nranks;
}
if (rank == collNetGraph->intra[recvEndIndex+c*comm->localRanks]) { // is bottom of intra-node chain
channel->collTreeUp.down[0] = channel->collTreeDn.down[0] = -1;
}
channel->collTreeUp.depth = channel->collTreeDn.depth = depth;
INFO(NCCL_GRAPH, "CollNet Channel %d rank %d up %d down %d", comm->nChannels/2+c, rank, channel->collTreeDn.up, channel->collTreeDn.down[0]);
}
return ncclSuccess;
}
Here sendIndex is selected as the first in the chain, and sendEndIndex as the last one. Since the last one connects to sendIndex, the connection between these two needs to be broken. Then iterating through upward channels, sendIndex’s up is set to nranks, sendEndIndex’s down is set to -1, and similarly for downward channels. The channels now look like Figure 5:

Figure 5#
Establishing Communication Links#
Then begins the establishment of intra-node and inter-node communication links.
if (comm->nNodes > 1 &&
ncclParamCollNetEnable() == 1 &&
collNetSupport() && collNetGraph.nChannels) {
int logicChannels = comm->nChannels/2;
int collNetSetupFail = 0;
const int recvIndex = 0; // recv GPU index is always 0
const int sendIndex = collNetGraph.pattern == NCCL_TOPO_PATTERN_TREE ? 0 : 1; // send GPU index depends on topo pattern
for (int c=0; c<logicChannels; c++) {
struct ncclChannel* channelRecv = comm->channels+logicChannels+c;
struct ncclChannel* channelSend = comm->channels+c;
NCCLCHECK(ncclTransportP2pSetup(comm, &collNetGraph, channelRecv, 1, &channelRecv->collTreeDn.up, 1, channelRecv->collTreeDn.down));
NCCLCHECK(ncclTransportP2pSetup(comm, &collNetGraph, channelSend, 1, channelSend->collTreeUp.down, 1, &channelSend->collTreeUp.up));
const int recvMaster = collNetGraph.intra[c*comm->localRanks+recvIndex];
const int sendMaster = collNetGraph.intra[c*comm->localRanks+sendIndex];
if (collNetSetup(comm, &collNetGraph, channelRecv, rank, nranks, recvMaster, sendMaster, comm->nNodes, 1) != 1)
collNetSetupFail = 1;
else if (collNetSetup(comm, &collNetGraph, channelSend, rank, nranks, sendMaster, recvMaster, comm->nNodes, 0) != 1)
collNetSetupFail = 1;
}
// Verify CollNet setup across ranks
NCCLCHECK(checkCollNetSetup(comm, rank, collNetSetupFail));
}
Taking the up channel (channelSend) as an example, it establishes intra-node connections through ncclTransportP2pSetup. Since sendIndex and sendEndIndex’s up/down are set to nranks or -1, only the connections shown by arrows in Figure 5 will be established.
Then begins the establishment of inter-node communication links. The first rank on each machine is responsible for network sending and receiving, and this rank is called the master of that node. Then Sharp communication groups are established, which only include the master of each node.
static int collNetSetup(struct ncclComm* comm, struct ncclTopoGraph* collNetGraph, struct ncclChannel* channel, int rank, int nranks, int masterRank, int masterPeer, int nMasters, int type) {
int rankInCollNet = -1;
int supported = 0;
int isMaster = (rank == masterRank) ? 1 : 0;
struct {
int collNetRank;
ncclConnect connect;
} sendrecvExchange;
// check if we can connect to collnet, whose root is the nranks-th rank
struct ncclPeerInfo *myInfo = comm->peerInfo+rank, *peerInfo = comm->peerInfo+nranks;
peerInfo->rank = nranks;
int ret = 1;
if (isMaster) {
NCCLCHECK(collNetTransport.canConnect(&ret, comm->topo, collNetGraph, myInfo, peerInfo));
}
// send master receives connect info from peer recv master
...
// select
struct ncclPeer* root = channel->peers+nranks;
struct ncclConnector* conn = (type == 1) ? &root->recv : &root->send;
struct ncclTransportComm* transportComm = (type == 1) ? &(collNetTransport.recv) : &(collNetTransport.send);
conn->transportComm = transportComm;
// setup
struct ncclConnect myConnect;
if (isMaster && ret > 0) {
NCCLCHECK(transportComm->setup(comm->topo, collNetGraph, myInfo, peerInfo, &myConnect, conn, channel->id));
}
...
}
First, let’s look at executing collNetSetup for recvMaster, where isMaster indicates whether the current node is the recvMaster; then set peerInfo, where peerInfo uses the nranks-th ncclPeerInfo in comm; then check if connection through collNet is possible via canConnect, which directly returns 1 here, indicating connection is possible.
Then execute transportComm->setup to initialize communication-related resources.
ncclResult_t collNetRecvSetup(struct ncclTopoSystem* topo, struct ncclTopoGraph* graph, struct ncclPeerInfo* myInfo, struct ncclPeerInfo* peerInfo, struct ncclConnect* connectInfo, struct ncclConnector* recv, int channelId) {
struct collNetRecvResources* resources;
NCCLCHECK(ncclCalloc(&resources, 1));
recv->transportResources = resources;
NCCLCHECK(ncclTopoGetNetDev(topo, myInfo->rank, graph, channelId, &resources->netDev));
NCCLCHECK(ncclTopoCheckGdr(topo, myInfo->busId, resources->netDev, 0, &resources->useGdr));
NCCLCHECK(ncclCudaHostCalloc(&resources->hostSendMem, 1));
resources->devHostSendMem = resources->hostSendMem;
int recvSize = offsetof(struct ncclRecvMem, buff);
for (int p=0; p<NCCL_NUM_PROTOCOLS; p++) recvSize += recv->comm->buffSizes[p];
if (resources->useGdr) {
NCCLCHECK(ncclCudaCalloc((char**)(&resources->devRecvMem), recvSize));
}
NCCLCHECK(ncclCudaHostCalloc((char**)&resources->hostRecvMem, recvSize));
resources->devHostRecvMem = resources->hostRecvMem;
NCCLCHECK(ncclIbMalloc((void**)&(resources->llData), recv->comm->buffSizes[NCCL_PROTO_LL]/2));
struct collNetRecvConnectInfo* info = (struct collNetRecvConnectInfo*) connectInfo;
NCCLCHECK(collNetListen(resources->netDev, &info->collNetHandle, &resources->netListenComm));
return ncclSuccess;
}
Allocate collNetRecvResources resources, then allocate GPU memory used by various protocols, as well as head, tail, etc. used for synchronization, and finally execute collNetListen.
The assignment here is a bit complex, let’s first look at what the resources structure becomes after executing collNetListen. collNetRecvResources is used by nccl here, and eventually netListenComm points to an ncclSharpListenComm, where the listenCommP2P in ncclSharpListenComm points to an ncclIbListenComm, which stores the network card and socket fd being used.
struct collNetRecvResources {
void* netListenComm; // ncclSharpListenComm
...
};
struct ncclSharpListenComm {
int dev;
void *listenCommP2P; // ncclIbListenComm
};
struct ncclIbListenComm {
int dev;
int fd;
};
Then let’s look at the specifics.
ncclResult_t ncclSharpListen(int dev, void* opaqueHandle, void** listenComm) {
struct ncclSharpListenComm *lComm;
ncclResult_t status;
NCCLCHECK(ncclIbMalloc((void**)&lComm, sizeof(struct ncclSharpListenComm)));
status = NCCL_PLUGIN_SYMBOL.listen(dev, opaqueHandle, &lComm->listenCommP2P);
lComm->dev = dev;
*listenComm = lComm;
return status;
}
collNetListen executes ncclSharpListen, which essentially calls the listen function of ib_plugin. Here we can see that netListenComm of collNetRecvResources is assigned to ncclSharpListenComm lComm.
ncclResult_t ncclIbListen(int dev, void* opaqueHandle, void** listenComm) {
struct ncclIbListenComm* comm;
comm = malloc(sizeof(struct ncclIbListenComm));
memset(comm, 0, sizeof(struct ncclIbListenComm));
struct ncclIbHandle* handle = (struct ncclIbHandle*) opaqueHandle;
NCCL_STATIC_ASSERT(sizeof(struct ncclIbHandle) < NCCL_NET_HANDLE_MAXSIZE, "ncclIbHandle size too large");
comm->dev = dev;
NCCLCHECK(GetSocketAddr(&(handle->connectAddr)));
NCCLCHECK(createListenSocket(&comm->fd, &handle->connectAddr));
*listenComm = comm;
return ncclSuccess;
}
The ib_plugin’s listen function essentially creates a listen socket, then saves the device number dev and socket fd to ncclIbListenComm, and lComm of ncclSharpListenComm is assigned this ncclIbListenComm. IP and port are saved to opaqueHandle, i.e., myConnect.
At this point setup is complete, let’s continue looking at collNetSetup.
static int collNetSetup(struct ncclComm* comm, struct ncclTopoGraph* collNetGraph, struct ncclChannel* channel, int rank, int nranks, int masterRank, int masterPeer, int nMasters, int type) {
...
// prepare connect handles
ncclResult_t res;
struct {
int isMaster;
ncclConnect connect;
} *allConnects = NULL;
ncclConnect *masterConnects = NULL;
NCCLCHECK(ncclCalloc(&masterConnects, nMasters));
if (type == 1) { // recv side: AllGather
// all ranks must participate
NCCLCHECK(ncclCalloc(&allConnects, nranks));
allConnects[rank].isMaster = isMaster;
memcpy(&(allConnects[rank].connect), &myConnect, sizeof(struct ncclConnect));
NCCLCHECKGOTO(bootstrapAllGather(comm->bootstrap, allConnects, sizeof(*allConnects)), res, cleanup);
// consolidate
int c = 0;
for (int r = 0; r < nranks; r++) {
if (allConnects[r].isMaster) {
memcpy(masterConnects+c, &(allConnects[r].connect), sizeof(struct ncclConnect));
if (r == rank) rankInCollNet = c;
c++;
}
}
} else { // send side : copy in connect info received from peer recv master
if (isMaster) memcpy(masterConnects+rankInCollNet, &(sendrecvExchange.connect), sizeof(struct ncclConnect));
}
// connect
if (isMaster && ret > 0) {
NCCLCHECKGOTO(transportComm->connect(masterConnects, nMasters, rankInCollNet, conn), res, cleanup);
struct ncclPeer* devRoot = channel->devPeers+nranks;
struct ncclConnector* devConn = (type == 1) ? &devRoot->recv : &devRoot->send;
CUDACHECKGOTO(cudaMemcpy(devConn, conn, sizeof(struct ncclConnector), cudaMemcpyHostToDevice), res, cleanup);
}
...
}
Then begins the exchange of master information, allocating nMaster ncclConnect *masterConnects, where nMaster is the number of nodes, then copying myConnect to the corresponding position in masterConnects, executing allgather to get ncclConnect of all ranks; then copying all master-corresponding ncclConnect from allConnects to masterConnects, and finally executing transportComm’s connect to complete the establishment of Sharp communication group.
Similarly, let’s first look at what the data structure in resources becomes after executing connect. collNetRecvComm points to an ncclSharpCollComm, where the recvComm and sendComm in ncclSharpCollComm function similarly to connecting previous and next nodes in the bootstrap network, sharpCollContext is the sharp context, and sharpCollComm is the sharp communicator.
struct collNetRecvResources {
...
void* collNetRecvComm; // ncclSharpCollComm
...
};
struct ncclSharpCollComm {
...
void* recvComm; // ncclIbRecvComm
void* sendComm; // ncclIbSendComm
...
struct sharp_coll_context* sharpCollContext;
struct sharp_coll_comm* sharpCollComm;
};
ncclResult_t collNetRecvConnect(struct ncclConnect* connectInfos, int nranks, int rank, struct ncclConnector* recv) {
// Setup device pointers
struct collNetRecvResources* resources = (struct collNetRecvResources*)recv->transportResources;
struct collNetSendConnectInfo* info = (struct collNetSendConnectInfo*)(connectInfos+rank);
resources->collNetRank = rank;
// Intermediate buffering on GPU for GPU Direct RDMA
struct ncclRecvMem* recvMem = resources->useGdr ? resources->devRecvMem : resources->devHostRecvMem;
int offset = 0;
for (int p=0; p<NCCL_NUM_PROTOCOLS; p++) {
recv->conn.buffs[p] = (p == NCCL_PROTO_LL ? resources->devHostRecvMem->buff : recvMem->buff) + offset;
offset += recv->comm->buffSizes[p];
}
recv->conn.direct |= resources->useGdr ? NCCL_DIRECT_NIC : 0;
// Head/Tail/Opcount are always on host
recv->conn.tail = &resources->devHostRecvMem->tail;
recv->conn.head = &resources->devHostSendMem->head;
// Connect to coll comm
collNetHandle_t** handlePtrs = NULL;
NCCLCHECK(ncclCalloc(&handlePtrs, nranks));
for (int i = 0; i < nranks; i++) {
struct collNetRecvConnectInfo* info = (struct collNetRecvConnectInfo*)(connectInfos+i);
handlePtrs[i] = &(info->collNetHandle);
}
ncclResult_t res;
NCCLCHECKGOTO(collNetConnect((void**)handlePtrs, nranks, rank, resources->netListenComm, &resources->collNetRecvComm), res, cleanup);
// Register buffers
NCCLCHECK(collNetRegMr(resources->collNetRecvComm, recv->conn.buffs[NCCL_PROTO_SIMPLE], recv->comm->buffSizes[NCCL_PROTO_SIMPLE],
resources->useGdr ? NCCL_PTR_CUDA : NCCL_PTR_HOST, &resources->mhandles[NCCL_PROTO_SIMPLE]));
NCCLCHECK(collNetRegMr(resources->collNetRecvComm, resources->llData, recv->comm->buffSizes[NCCL_PROTO_LL]/2,
NCCL_PTR_HOST, &resources->mhandles[NCCL_PROTO_LL]));
// Create shared info between send and recv proxies
NCCLCHECK(ncclCalloc(&(resources->reqFifo), NCCL_STEPS));
// Pass info to send side
info->reqFifo = resources->reqFifo;
info->collNetComm = resources->collNetRecvComm;
for (int p=0; p<NCCL_NUM_PROTOCOLS; p++)
info->mhandles[p] = resources->mhandles[p];
cleanup:
if (handlePtrs != NULL) free(handlePtrs);
// Close listen comm
NCCLCHECK(collNetCloseListen(resources->netListenComm));
return res;
}
First record the head, tail, buffer etc. from resource to conn, handlePtrs records each master rank’s listen ip port, then execute collNetConnect to establish the Sharp communication group.
ncclResult_t ncclSharpConnect(void* handles[], int nranks, int rank, void* listenComm, void** collComm) {
struct ncclSharpListenComm* lComm = (struct ncclSharpListenComm*)listenComm;
struct ncclSharpCollComm* cComm;
NCCLCHECK(ncclIbMalloc((void**)&cComm, sizeof(struct ncclSharpCollComm)));
NCCLCHECK(ncclIbMalloc((void**)&cComm->reqs, sizeof(struct ncclSharpRequest)*MAX_REQUESTS));
cComm->nranks = nranks;
cComm->rank = rank;
if (cComm->rank == -1) {
WARN("Could not determine my rank\n");
return ncclInternalError;
}
int next = (cComm->rank + 1) % nranks;
NCCLCHECK(NCCL_PLUGIN_SYMBOL.connect(lComm->dev, handles[next], &cComm->sendComm));
NCCLCHECK(NCCL_PLUGIN_SYMBOL.accept(lComm->listenCommP2P, &cComm->recvComm)); // From prev
struct ncclSharpInfo* allInfo;
pid_t pid = getpid();
pthread_t tid = pthread_self();
NCCLCHECK(ncclIbMalloc((void**)&allInfo, sizeof(struct ncclSharpInfo)*nranks));
allInfo[cComm->rank].hostId = gethostid();
allInfo[cComm->rank].jobId = (((uint64_t)allInfo[cComm->rank].hostId << 32) | ((pid ^ tid) ^ rand()));
NCCLCHECK(ncclSharpAllGather(cComm, allInfo, sizeof(struct ncclSharpInfo)));
// Find my local rank;
int localRank = 0;
for (int i=0; i<cComm->rank; i++) {
if (allInfo[cComm->rank].hostId == allInfo[i].hostId) {
localRank++;
}
}
uint64_t jobId = allInfo[0].jobId;
free(allInfo);
...
}
Create ncclSharpCollComm cComm, which will eventually be assigned to collNetRecvComm. Similar to bootstrap network, this will connect all master ranks head-to-tail through ib_plugin, where the connect and accept logic is identical to the previous ncclNetIb, so we won’t elaborate here. Then create ncclSharpInfo allInfo, record hostid, generate a random jobId, and execute allgather.
ncclResult_t ncclSharpConnect(void* handles[], int nranks, int rank, void* listenComm, void** collComm) {
...
struct sharp_coll_init_spec init_spec = {0};
init_spec.progress_func = NULL;
init_spec.job_id = jobId;
init_spec.world_rank = cComm->rank;
init_spec.world_size = nranks;
init_spec.world_local_rank = 0;
init_spec.enable_thread_support = 1;
init_spec.group_channel_idx = 0;
init_spec.oob_colls.barrier = ncclSharpOobBarrier;
init_spec.oob_colls.bcast = ncclSharpOobBcast;
init_spec.oob_colls.gather = ncclSharpOobGather;
init_spec.oob_ctx = cComm;
init_spec.config = sharp_coll_default_config;
init_spec.config.user_progress_num_polls = 10000000;
char devName[MAXNAMESIZE];
ncclNetProperties_t prop;
ncclSharpGetProperties(lComm->dev, &prop);
snprintf(devName, MAXNAMESIZE, "%s:%d", prop.name, prop.port);
init_spec.config.ib_dev_list = devName;
int ret = sharp_coll_init(&init_spec, &cComm->sharpCollContext);
INFO(NCCL_INIT, "Sharp rank %d/%d initialized on %s", cComm->rank, nranks, devName);
if (ret < 0) {
WARN("NET/IB :SHARP coll init error: %s(%d)\n", sharp_coll_strerror(ret), ret);
return ncclInternalError;
}
struct sharp_coll_comm_init_spec comm_spec;
comm_spec.rank = cComm->rank;
comm_spec.size = nranks;
comm_spec.oob_ctx = cComm;
comm_spec.group_world_ranks = NULL;
ret = sharp_coll_comm_init(cComm->sharpCollContext, &comm_spec, &cComm->sharpCollComm);
if (ret < 0) {
WARN("SHARP group create failed: %s(%d)\n", sharp_coll_strerror(ret), ret);
return ncclInternalError;
}
*collComm = cComm;
return ncclSuccess;
Create sharp_coll_init_spec init_spec to initialize sharp communication context sharpCollContext, initialize init_spec, set job_id to rank0’s job_id, set rank, size etc., set init_spec.oob_colls’s oob_ctx to cComm, set oob_colls.barrier etc., oob_colls is analogous to nccl’s bootstrap network, set which network card to use, then execute sharp_coll_init, which will initialize sharp, then initialize sharpCollComm with sharpCollContext through sharp_coll_comm_init, completing the establishment of Sharp communication group.
Then return to ncclSharpConnect and begin registering memory, which will register sharp memory through sharp_coll_reg_mr, and needs to register rdma memory through ibv_reg_mr. Finally request reqFifo, record reqFifo and collNetRecvComm to info, which will later be sent to send.
ncclResult_t collNetRecvConnect(struct ncclConnect* connectInfos, int nranks, int rank, struct ncclConnector* recv) {
...
// Register buffers
NCCLCHECK(collNetRegMr(resources->collNetRecvComm, recv->conn.buffs[NCCL_PROTO_SIMPLE], recv->comm->buffSizes[NCCL_PROTO_SIMPLE],
resources->useGdr ? NCCL_PTR_CUDA : NCCL_PTR_HOST, &resources->mhandles[NCCL_PROTO_SIMPLE]));
NCCLCHECK(collNetRegMr(resources->collNetRecvComm, resources->llData, recv->comm->buffSizes[NCCL_PROTO_LL]/2,
NCCL_PTR_HOST, &resources->mhandles[NCCL_PROTO_LL]));
// Create shared info between send and recv proxies
NCCLCHECK(ncclCalloc(&(resources->reqFifo), NCCL_STEPS));
// Pass info to send side
info->reqFifo = resources->reqFifo;
info->collNetComm = resources->collNetRecvComm;
for (int p=0; p<NCCL_NUM_PROTOCOLS; p++)
info->mhandles[p] = resources->mhandles[p];
cleanup:
if (handlePtrs != NULL) free(handlePtrs);
// Close listen comm
NCCLCHECK(collNetCloseListen(resources->netListenComm));
return res;
}
Then return to collNetSetup, the recv end will send info to the send end, i.e., reqFifo address and collNetRecvComm.
static int collNetSetup(struct ncclComm* comm, struct ncclTopoGraph* collNetGraph, struct ncclChannel* channel, int rank, int nranks, int masterRank, int masterPeer, int nMasters, int type) {
...
// recv side sends connect info to send side
if (isMaster && type == 1) {
sendrecvExchange.collNetRank = rankInCollNet;
memcpy(&sendrecvExchange.connect, masterConnects+rankInCollNet, sizeof(struct ncclConnect));
NCCLCHECKGOTO(bootstrapSend(comm->bootstrap, masterPeer, &sendrecvExchange, sizeof(sendrecvExchange)), res, cleanup);
}
if (ret > 0) {
supported = 1;
}
cleanup:
if (allConnects != NULL) free(allConnects);
if (masterConnects != NULL) free(masterConnects);
return supported;
}
Then begin executing collNetSetup for the send end, which is simpler, mainly involving memory allocation and registration, then through info sent by recv, record reqFifo and comm from info to collNetSendResources.
At this point the communication link establishment is complete, next we’ll look at the api execution process
enqueue#
As mentioned earlier, when a user executes an allreduce api, it will perform the enqueue operation.
ncclResult_t ncclSaveKernel(struct ncclInfo* info) {
struct ncclColl coll;
struct ncclProxyArgs proxyArgs;
memset(&proxyArgs, 0, sizeof(struct ncclProxyArgs));
NCCLCHECK(computeColl(info, &coll, &proxyArgs));
info->comm->myParams->blockDim.x = std::max<unsigned>(info->comm->myParams->blockDim.x, info->nThreads);
int nChannels = info->coll == ncclCollSendRecv ? 1 : coll.args.coll.nChannels;
int nSubChannels = (info->pattern == ncclPatternCollTreeUp || info->pattern == ncclPatternCollTreeDown) ? 2 : 1;
for (int bid=0; bid<nChannels*nSubChannels; bid++) {
int channelId = (info->coll == ncclCollSendRecv) ? info->channelId :
info->comm->myParams->gridDim.x % info->comm->nChannels;
struct ncclChannel* channel = info->comm->channels+channelId;
proxyArgs.channel = channel;
// Adjust pattern for CollNet based on channel index
if (nSubChannels == 2) {
info->pattern = (channelId < info->comm->nChannels/nSubChannels) ? ncclPatternCollTreeUp : ncclPatternCollTreeDown;
}
NCCLCHECK(ncclProxySaveColl(&proxyArgs, info->pattern, info->root, info->comm->nRanks));
info->comm->myParams->gridDim.x++;
int opIndex = channel->collFifoTail;
struct ncclColl* c = channel->collectives+opIndex;
volatile uint8_t* activePtr = (volatile uint8_t*)&c->active;
while (activePtr[0] != 0) sched_yield();
memcpy(c, &coll, sizeof(struct ncclColl));
if (info->coll != ncclCollSendRecv) c->args.coll.bid = bid % coll.args.coll.nChannels;
c->active = 1;
opIndex = (opIndex+1)%NCCL_MAX_OPS;
c->nextIndex = opIndex;
channel->collFifoTail = opIndex;
channel->collCount++;
}
info->comm->opCount++;
return ncclSuccess;
}
Record algorithm, protocol and other information to coll through computeColl. When using sharp, the algorithm is NCCL_ALGO_COLLNET, nChannels is set to half of the searched channel number, pattern is set to ncclPatternCollTreeUp, info->nstepsPerLoop = info->nchunksPerLoop = 1.
Then record coll to all channels, up channel pattern is ncclPatternCollTreeUp, down channel pattern is ncclPatternCollTreeDown, then create ncclProxyArgs through ncclProxySaveColl.
kernel and proxy#
__device__ void ncclAllReduceCollNetKernel(struct CollectiveArgs* args) {
const int tid = threadIdx.x;
const int nthreads = args->coll.nThreads-WARP_SIZE;
const int bid = args->coll.bid;
const int nChannels = args->coll.nChannels;
struct ncclDevComm* comm = args->comm;
struct ncclChannel* channel = comm->channels+blockIdx.x;
const int stepSize = comm->buffSizes[NCCL_PROTO_SIMPLE] / (sizeof(T)*NCCL_STEPS);
int chunkSize = args->coll.lastChunkSize;
const ssize_t minChunkSize = nthreads*8*sizeof(uint64_t) / sizeof(T);
const ssize_t loopSize = nChannels*chunkSize;
const ssize_t size = args->coll.count;
if (loopSize > size) {
chunkSize = DIVUP(size, nChannels*minChunkSize)*minChunkSize;
}
// Compute pointers
const T * __restrict__ thisInput = (const T*)args->sendbuff;
T * __restrict__ thisOutput = (T*)args->recvbuff;
if (blockIdx.x < nChannels) { // first half of the channels do reduce
struct ncclTree* tree = &channel->collTreeUp;
ncclPrimitives<UNROLL, 1, 1, T, 1, 1, 0, FUNC> prims(tid, nthreads, tree->down, &tree->up, NULL, stepSize, channel, comm);
for (ssize_t gridOffset = 0; gridOffset < size; gridOffset += loopSize) {
// Up
ssize_t offset = gridOffset + bid*chunkSize;
int nelem = min(chunkSize, size-offset);
if (tree->up == -1) {
prims.recvReduceCopy(thisInput+offset, thisOutput+offset, nelem);
} else if (tree->down[0] == -1) {
prims.send(thisInput+offset, nelem);
} else {
prims.recvReduceSend(thisInput+offset, nelem);
}
}
}
...
}
Let’s first look at the upstream process. Since nChannels is divided by 2 earlier, channels less than nChannels are upstream channels. If it’s sendEndIndex, its down is -1, so it directly sends its data to the next rank’s buffer through send. If it’s not sendEndIndex, it needs to receive data sent from the previous rank, perform reduce with the corresponding data in its userbuff, and then send it to the up buffer.
Then let’s look at the proxy’s send process:
ncclResult_t collNetSendProxy(struct ncclProxyArgs* args) {
...
if (args->state == ncclProxyOpProgress) {
int p = args->protocol;
int stepSize = args->connector->comm->buffSizes[p] / NCCL_STEPS;
char* localBuff = args->connector->conn.buffs[p];
void* sendMhandle = resources->sendMhandles[p];
void* recvMhandle = resources->recvMhandles[p];
args->idle = 1;
struct reqSlot* reqFifo = resources->reqFifo;
if (args->head < args->end) {
int buffSlot = args->tail%NCCL_STEPS;
if (args->tail < args->end && args->tail < args->head + NCCL_STEPS
&& reqFifo[buffSlot].recvBuff != NULL) {
volatile int* sizesFifo = resources->hostRecvMem->sizesFifo;
volatile uint64_t* recvTail = &resources->hostRecvMem->tail;
if (args->protocol == NCCL_PROTO_LL) {
} else if (args->tail < *recvTail) {
// Send through network
if (sizesFifo[buffSlot] != -1) {
int count = sizesFifo[buffSlot]/ncclTypeSize(args->dtype);
NCCLCHECK(collNetIallreduce(resources->collNetSendComm, localBuff+buffSlot*stepSize, (void*)(reqFifo[buffSlot].recvBuff), count, args->dtype, args->redOp, sendMhandle, recvMhandle, args->requests+buffSlot));
if (args->requests[buffSlot] != NULL) {
sizesFifo[buffSlot] = -1;
// Make sure size is reset to zero before we update the head.
__sync_synchronize();
args->tail += args->sliceSteps;
args->idle = 0;
}
}
}
}
if (args->head < args->tail) {
int done, size;
int buffSlot = args->head%NCCL_STEPS;
NCCLCHECK(collNetTest((void*)(args->requests[buffSlot]), &done, &size));
if (done) {
TRACE(NCCL_NET, "sendProxy [%d/%d] request %p done, size %d", args->head, buffSlot, args->requests[buffSlot], size);
reqFifo[buffSlot].size = size;
// Make sure size is updated before we set recvBuff to NULL (from the view of recv proxy, concerning the flush)
// (reordered store after store is possible on POWER, though not on x86)
__sync_synchronize();
reqFifo[buffSlot].recvBuff = NULL; // Notify recvProxy
args->head += args->sliceSteps;
resources->hostSendMem->head = args->head;
args->idle = 0;
}
}
}
if (args->head == args->end) {
resources->step = args->end;
args->idle = 0;
args->state = ncclProxyOpNone;
}
}
collNetIallreduce fills the sendbuff, recvbuff and corresponding mr into sharp_coll_reduce_spec, then executes sharp_coll_do_allreduce or sharp_coll_do_allreduce_nb. After execution completes, the reduce result will be filled into recvbuff.
Here, sendbuff is the buff in the send conn, and recvbuff is the buff in the recv conn. SendProxy doesn’t know which part of the buff in recv conn is available, so reqFifo is used to coordinate between send and recv. As we can see, the conditions for determining whether data can be sent include not only checking if the queue has data but also checking if the corresponding reqFifo’s recvBuff is NULL. Only when both conditions are met can data be sent.
After sending is complete, tail is increased by sliceSteps. If head is less than tail, it means there are allreduce operations that have been sent but not completed. Then it uses sharp_coll_req_test to check if the corresponding request is complete. If complete, head is increased by sliceSteps, and the corresponding recvBuff is set to NULL to notify RecvProxy that this req has completed.
Then let’s look at RecvProxy:
ncclResult_t collNetRecvProxy(struct ncclProxyArgs* args) {
if (args->head < args->end) {
if ((args->tail < args->head + NCCL_STEPS) && (args->tail < (resources->hostSendMem->head) + NCCL_STEPS) && (args->tail < args->end)) {
int buffSlot = args->tail%NCCL_STEPS;
char* recvBuff = p == NCCL_PROTO_LL ? (char*)resources->llData : localBuff;
int recvStepSize = p == NCCL_PROTO_LL ? stepSize/2 : stepSize;
reqFifo[buffSlot].recvBuff = recvBuff+buffSlot*recvStepSize;
TRACE(NCCL_NET, "recvProxy [%d/%d] posted buffer %p", args->tail, buffSlot, reqFifo[buffSlot].recvBuff);
args->tail += args->sliceSteps;
args->idle = 0;
}
if (args->tail > args->head) {
int buffSlot = args->head%NCCL_STEPS;
if (reqFifo[buffSlot].recvBuff == NULL) { // Buffer is cleared : coll is complete
TRACE(NCCL_NET, "recvProxy [%d/%d] done, size %d", args->head, buffSlot, reqFifo[buffSlot].size);
args->head += args->sliceSteps;
if (args->protocol == NCCL_PROTO_LL) { // ll
} else if (args->protocol == NCCL_PROTO_SIMPLE) {
if (resources->useGdr) NCCLCHECK(collNetFlush(resources->collNetRecvComm, localBuff+buffSlot*stepSize, reqFifo[buffSlot].size, mhandle));
resources->hostRecvMem->tail = args->head;
}
args->idle = 0;
}
}
}
}
Here we can see that as long as the queue has space, it will dispatch the corresponding recvbuf to reqFifo. If tail is greater than head, indicating there are incomplete requests, it checks if the corresponding recvbuff is NULL. If it’s NULL, meaning it’s completed, then head is increased by sliceSteps, and collNetFlush is executed to ensure data is written to disk. The flush here is consistent with ncclNetIb, both reading local QP. After flush, resources->hostRecvMem->tail is set to head to notify the kernel there’s new data.
Finally, let’s look at the recv kernel:
template<int UNROLL, class FUNC, typename T>
__device__ void ncclAllReduceCollNetKernel(struct CollectiveArgs* args) {
...
if (blockIdx.x >= nChannels) { // second half of the channels do broadcast
struct ncclTree* tree = &channel->collTreeDn;
ncclPrimitives<UNROLL, 1, 1, T, 1, 1, 0, FUNC> prims(tid, nthreads, &tree->up, tree->down, NULL, stepSize, channel, comm);
for (ssize_t gridOffset = 0; gridOffset < size; gridOffset += loopSize) {
// Down
ssize_t offset = gridOffset + bid*chunkSize;
int nelem = min(chunkSize, size-offset);
if (tree->up == -1) {
prims.send(thisOutput+offset, nelem);
} else if (tree->down[0] == -1) {
prims.recv(thisOutput+offset, nelem);
} else {
prims.recvCopySend(thisOutput+offset, nelem);
}
}
}
}
If it’s recvEndIndex, it only needs to recv data. If it’s not recvEndIndex, it uses recvCopySend to receive data from the up buffer, copy it to the corresponding position in its user buffer, and send it to the down buffer.