Let’s recall the single-machine execution process: after executing ncclSend, users save sendbuff, sendbytes, peer, and other information to comm->p2plist through ncclEnqueueCheck. Then when executing ncclGroupEnd, if the channel hasn’t established a connection to the peer, it first builds the connection, then executes scheduleSendRecv (ncclSaveKernel) based on p2plist to save information to channel->collectives, and finally launches the kernel. The kernel will traverse channel->collectives to execute send and recv operations. Now let’s examine how the multi-machine process works.
ncclProxyArgs#
First, let’s look at ncclSaveKernel in the scheduleSendRecv process. The difference here from single-machine is ncclProxySaveP2p.
ncclResult_t ncclSaveKernel(struct ncclInfo* info) {
...
for (int bid=0; bid<nChannels*nSubChannels; bid++) {
int channelId = (info->coll == ncclCollSendRecv) ? info->channelId :
info->comm->myParams->gridDim.x % info->comm->nChannels;
struct ncclChannel* channel = info->comm->channels+channelId;
...
// Proxy
proxyArgs.channel = channel;
...
if (info->coll == ncclCollSendRecv) {
info->comm->myParams->gridDim.x = std::max<unsigned>(info->comm->myParams->gridDim.x, channelId+1);
NCCLCHECK(ncclProxySaveP2p(info, channel));
} else {
NCCLCHECK(ncclProxySaveColl(&proxyArgs, info->pattern, info->root, info->comm->nRanks));
}
...
}
...
}
Network communication between multiple machines is executed by independent proxy threads. ncclProxyArgs stores the parameters needed for communication, and proxy threads execute corresponding communication processes based on these args. Then SaveProxy is executed.
ncclResult_t ncclProxySaveP2p(struct ncclInfo* info, struct ncclChannel* channel) {
struct ncclProxyArgs args;
memset(&args, 0, sizeof(struct ncclProxyArgs));
args.channel = channel;
args.sliceSteps = 1;
args.chunkSteps = 1;
args.protocol = NCCL_PROTO_SIMPLE;
args.opCount = info->comm->opCount;
args.dtype = info->datatype;
if (info->delta > 0 && info->sendbytes >= 0) {
int peersend = (info->comm->rank+info->delta)%info->comm->nRanks;
args.nsteps = DIVUP(info->sendbytes, info->comm->buffSizes[NCCL_PROTO_SIMPLE]/NCCL_STEPS/SENDRECV_SLICEFACTOR);
if (args.nsteps == 0) args.nsteps = 1;
NCCLCHECK(SaveProxy<proxySend>(peersend, &args));
}
if (info->delta > 0 && info->recvbytes >= 0) {
int peerrecv = (info->comm->nRanks+info->comm->rank-info->delta)%info->comm->nRanks;
args.nsteps = DIVUP(info->recvbytes, info->comm->buffSizes[NCCL_PROTO_SIMPLE]/NCCL_STEPS/SENDRECV_SLICEFACTOR);
if (args.nsteps == 0) args.nsteps = 1;
NCCLCHECK(SaveProxy<proxyRecv>(peerrecv, &args));
}
return ncclSuccess;
}
First, it gets the ncclPeer connected to the peer for the current channel, and obtains the corresponding connector for this peer based on whether the type is send or recv. In single-machine scenarios, the connector’s transportComm is p2pTransport and proxy is null, so it returns directly. In multi-machine scenarios, it’s netTransport, proxy isn’t null, then it allocates ncclProxyArgs and sets progress to transportComm->proxy.
template <int type>
static ncclResult_t SaveProxy(int peer, struct ncclProxyArgs* args) {
if (peer < 0) return ncclSuccess;
struct ncclPeer* peerComm = args->channel->peers+peer;
struct ncclConnector* connector = type == proxyRecv ? &peerComm->recv : &peerComm->send;
if (connector->transportComm == NULL) {
WARN("[%d] Error no transport for %s peer %d on channel %d\n", connector->comm->rank,
type == proxyRecv ? "recv" : "send", peer, args->channel->id);
return ncclInternalError;
}
if (connector->transportComm->proxy == NULL) return ncclSuccess;
struct ncclProxyArgs* op;
NCCLCHECK(allocateArgs(connector->comm, &op));
memcpy(op, args, sizeof(struct ncclProxyArgs));
op->connector = connector;
op->progress = connector->transportComm->proxy;
op->state = ncclProxyOpReady;
ProxyAppend(connector, op);
return ncclSuccess;
}
Then ProxyAppend is executed.
static void ProxyAppend(struct ncclConnector* connector, struct ncclProxyArgs* args) {
struct ncclComm* comm = connector->comm;
struct ncclProxyState* state = &comm->proxyState;
pthread_mutex_lock(&state->mutex);
if (connector->proxyAppend == NULL) {
// Nothing running for that peer. Add to the circular list
if (state->ops == NULL) {
// Create the list
args->next = args;
state->ops = args;
} else {
// Insert element in the list
args->next = state->ops->next;
state->ops->next = args;
}
connector->proxyAppend = args;
} else {
// There is an active operation already for that peer.
// Add it to the per-peer list
connector->proxyAppend->nextPeer = args;
connector->proxyAppend = args;
}
pthread_mutex_unlock(&state->mutex);
}
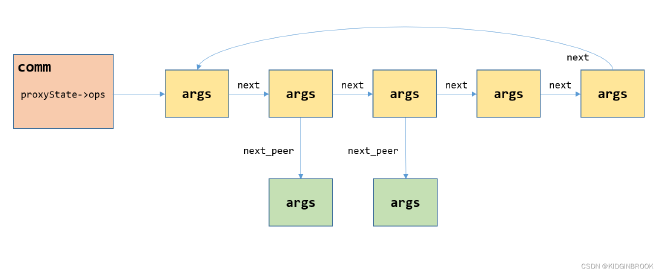
Figure 1
ncclProxyArgs is organized in a layered chain structure as shown in Figure 1. proxyState->ops in comm is the first args in the first layer. A vertical column represents all args on the same connector, with the first layer (yellow box) being the first args for that connector, and the second layer (green box) being the second args. Layers are linked via next_peer pointers; a row represents args at corresponding positions for all connectors, linked within layers via next pointers.
proxy thread#
Let’s look at the proxy thread mentioned earlier. During initTransportsRank, the proxy thread executing persistentThread was created through ncclProxyCreate. During creation, since ProxyAppend hasn’t been executed yet, comm’s proxyState->op is null, so the thread blocks at state->cond.
void* persistentThread(void *comm_) {
struct ncclComm* comm = (struct ncclComm*)comm_;
struct ncclProxyState* state = &comm->proxyState;
struct ncclProxyArgs* op = NULL;
ncclResult_t ret = ncclSuccess;
int idle = 1;
int idleSpin = 0;
while (1) {
do {
if (*comm->abortFlag) return NULL;
if (op == NULL) {
pthread_mutex_lock(&state->mutex);
op = state->ops;
if (op == NULL) {
if (state->stop) {
// No more commands to process and proxy has been requested to stop
pthread_mutex_unlock(&state->mutex);
return NULL;
}
pthread_cond_wait(&state->cond, &state->mutex);
}
pthread_mutex_unlock(&state->mutex);
}
} while (op == NULL);
...
}
}
When ProxyArgs are added and wake up the proxy thread, the proxy thread starts executing the first layer args, gets the first args op, and executes the op’s progress function. For send scenarios, progress is netTransport’s netSendProxy; for receive, it’s netRecvProxy. After executing op’s progress, it traverses to the next args. If next’s state isn’t ncclProxyOpNone, indicating next hasn’t finished executing, op is set to next and will execute next time. If the state is ncclProxyOpNone, indicating next has completed, next needs to be removed from the args chain. At this point, it attempts to replace next with next’s next_peer. If next has no next_peer, it’s directly removed from the first layer chain; otherwise, next_peer is promoted to the first layer to replace next.
void* persistentThread(void *comm_) {
...
while (1) {
...
op->idle = 0;
// opCount >= lastOpCount are part of an ongoing GroupStart/GroupEnd that hasn't started
// yet and might be cancelled before they even start. Hold on on those.
if (op->state != ncclProxyOpNone && op->opCount < comm->lastOpCount) ret = op->progress(op);
if (ret != ncclSuccess) {
comm->fatalError = ret;
INFO(NCCL_ALL,"%s:%d -> %d [Proxy Thread]", __FILE__, __LINE__, ret);
return NULL;
}
idle &= op->idle;
pthread_mutex_lock(&state->mutex);
if (!idle) idleSpin = 0;
struct ncclProxyArgs *next = op->next;
if (next->state == ncclProxyOpNone) {
struct ncclProxyArgs *freeOp = next;
if (next->nextPeer) {
// Replace next by its next per-peer element.
next = next->nextPeer;
if (op != freeOp) {
next->next = freeOp->next;
op->next = next;
} else {
next->next = next;
}
} else {
// Remove next from circular list
next->connector->proxyAppend = NULL;
if (op != freeOp) {
next = next->next;
op->next = next;
} else {
next = NULL;
}
}
if (freeOp == state->ops) state->ops = next;
freeOp->next = state->pool;
state->pool = freeOp;
}
op = next;
if (op == state->ops) {
if (idle == 1) {
if (++idleSpin == 10) {
sched_yield();
idleSpin = 0;
}
}
idle = 1;
}
pthread_mutex_unlock(&state->mutex);
}
}
Let’s see how the proxy thread is awakened. After executing scheduleSendRecv, the kernel is launched through ncclBarrierEnqueue.
ncclResult_t ncclGroupEnd() {
...
for (int i=0; i<ncclGroupIndex; i++) {
struct ncclAsyncArgs* args = ncclGroupArgs+i;
if (args->funcType == ASYNC_FUNC_COLL) {
if (args->coll.comm->userStream == NULL)
CUDACHECKGOTO(cudaSetDevice(args->coll.comm->cudaDev), ret, end);
NCCLCHECKGOTO(ncclBarrierEnqueue(args->coll.comm), ret, end);
}
}
for (int i=0; i<ncclGroupIndex; i++) {
struct ncclAsyncArgs* args = ncclGroupArgs+i;
if (args->funcType == ASYNC_FUNC_COLL) {
CUDACHECKGOTO(cudaSetDevice(args->coll.comm->cudaDev), ret, end);
NCCLCHECKGOTO(ncclBarrierEnqueueWait(args->coll.comm), ret, end);
}
}
for (int i=0; i<ncclGroupIndex; i++) {
struct ncclAsyncArgs* args = ncclGroupArgs+i;
if (args->funcType == ASYNC_FUNC_COLL) {
if (args->coll.comm->userStream == NULL)
CUDACHECKGOTO(cudaSetDevice(args->coll.comm->cudaDev), ret, end);
NCCLCHECKGOTO(ncclEnqueueEvents(args->coll.comm), ret, end);
}
}
...
}
Then in ncclBarrierEnqueueWait, ncclProxyStart is executed, which uses pthread_cond_signal to wake up the proxy thread blocked in proxyState.cond.
ncclResult_t ncclProxyStart(struct ncclComm* comm) {
pthread_mutex_lock(&comm->proxyState.mutex);
if (comm->proxyState.ops != NULL)
pthread_cond_signal(&comm->proxyState.cond);
pthread_mutex_unlock(&comm->proxyState.mutex);
return ncclSuccess;
}
Queue Creation#
First, let’s look at how the send-side proxy thread and kernel cooperate. Similar to the queue between send and recv in single-machine internal communication, proxy and kernel also coordinate through this producer-consumer queue. The overall structure is shown in the following figure:
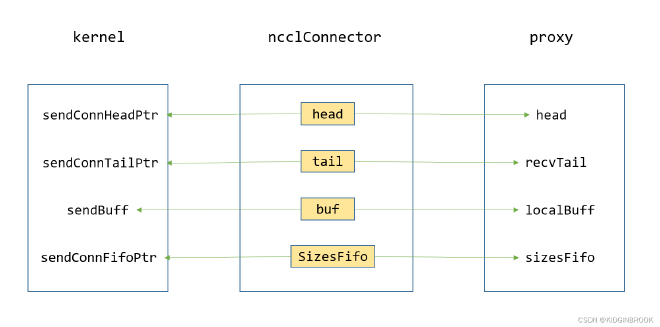
Figure 2
Recalling the communication connection establishment process, the send side executes netSendSetup to allocate variables needed during communication, such as ncclConnector shown in Figure 2.
ncclResult_t netSendSetup(struct ncclTopoSystem* topo, struct ncclTopoGraph* graph, struct ncclPeerInfo* myInfo, struct ncclPeerInfo* peerInfo, struct ncclConnect* connectInfo, struct ncclConnector* send, int channelId) {
...
NCCLCHECK(ncclCudaHostCalloc(&resources->sendMem, 1));
NCCLCHECK(ncclCudaHostCalloc(&resources->recvMem, 1));
send->conn.direct |= resources->useGdr ? NCCL_DIRECT_NIC : 0;
send->conn.tail = &resources->recvMem->tail;
send->conn.fifo = resources->recvMem->sizesFifo;
send->conn.head = &resources->sendMem->head;
for (int i=0; i<NCCL_STEPS; i++) send->conn.fifo[i] = -1;
...
if (resources->buffSizes[LOC_DEVMEM]) {
NCCLCHECK(ncclCudaCalloc(resources->buffers+LOC_DEVMEM, resources->buffSizes[LOC_DEVMEM]));
}
...
int offsets[LOC_COUNT];
offsets[LOC_HOSTMEM] = offsets[LOC_DEVMEM] = 0;
for (int p=0; p<NCCL_NUM_PROTOCOLS; p++) {
resources->mhandlesProto[p] = resources->mhandles+protoLoc[p];
send->conn.buffs[p] = resources->buffers[protoLoc[p]] + offsets[protoLoc[p]];
offsets[protoLoc[p]] += buffSizes[p];
}
...
return ncclSuccess;
}
The core elements are the queue’s head, tail, and SizesFifo, and the buf used in communication - these are all saved to the connector’s conn. For the kernel side, after executing loadSendConn and loadSendSync, the kernel holds the ncclConnector variables, as shown in the left box of Figure 2.
__device__ __forceinline__ void loadSendConn(struct ncclConnInfo* conn, int i) {
sendBuff[i] = (T*)conn->buffs[NCCL_PROTO_SIMPLE];
sendStep[i] = conn->step;
...
}
__device__ __forceinline__ void loadSendSync() {
if (tid < nsend) {
sendConnHeadPtr = sendConn->head;
sendConnHeadCache = *sendConnHeadPtr;
sendConnFifoPtr = sendConn->fifo;
}
if (tid >= nthreads && wid<nsend) {
sendConnTailPtr = sendConn->tail;
}
}
For the proxy thread, ncclConnector is saved in ncclProxyArgs, so proxy can also access these variables, as shown in the right box of Figure 2.
Queue Operation#
Let’s look at how this queue operates from both kernel and proxy perspectives.
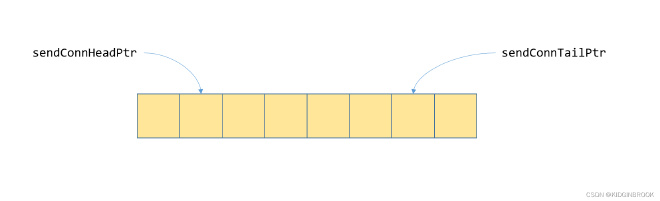
Figure 3
For the kernel side, as shown in Figure 3, the process is consistent with single-machine. Before transferring data, it checks if the queue is full by comparing the distance between sendConnHeadPtr and sendConnTailPtr. Note that sendConnHead is actually sendConnTailPtr. Then it writes the data length to sendConnFifoPtr (sizesFifo), so proxy knows the length of this data write.
inline __device__ void waitSend(int nbytes) {
spins = 0;
if (sendConnHeadPtr) {
while (sendConnHeadCache + NCCL_STEPS < sendConnHead + SLICESTEPS) {
sendConnHeadCache = *sendConnHeadPtr;
if (checkAbort(wid, 1)) break;
}
if (sendConnFifoPtr) {
sendConnFifoPtr[sendConnHead%NCCL_STEPS] = nbytes;
}
sendConnHead += SLICESTEPS;
}
}
Each time new data is transferred, sendConnTailPtr is incremented by one.
inline __device__ void postSend() {
if (sendConnTailPtr) *sendConnTailPtr = sendConnTail += SLICESTEPS;
}
The same queue from the proxy’s perspective is shown in Figure 4:
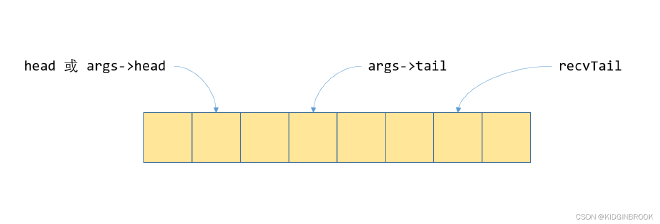
Figure 4
recvTail is updated by the kernel, indicating how much data the kernel side has generated. head is updated by proxy, indicating how much data proxy has finished sending. Since proxy uses asynchronous sending, the tail variable is introduced. Data between head and tail has been asynchronously sent by proxy but not confirmed complete, while data between tail and recvTail hasn’t been sent by proxy yet.
Specifically, when proxy gets a new ncclProxyArgs args (state is ncclProxyOpReady), it first calculates head, tail and end, where head and tail indicate the queue’s ends, and end indicates how many steps are needed to complete sending data for the current args. Then the state changes to ncclProxyOpProgress.
ncclResult_t netSendProxy(struct ncclProxyArgs* args) {
struct netSendResources* resources = (struct netSendResources*) (args->connector->transportResources);
if (args->state == ncclProxyOpReady) {
// Round to next multiple of sliceSteps
resources->step = ROUNDUP(resources->step, args->chunkSteps);
args->head = resources->step;
args->tail = resources->step;
args->end = args->head + args->nsteps;
args->state = ncclProxyOpProgress;
}
...
return ncclSuccess;
}
In single-machine processes, the queue is logical and doesn’t actually allocate a queue. In multi-machine scenarios, sizesFifo can be understood as an actually allocated queue, where each item in the fifo represents the length of this data block. We can see that proxy executes the data sending process directly through ncclNetIsend after getting the corresponding fifo item.
ncclResult_t netSendProxy(struct ncclProxyArgs* args) {
struct netSendResources* resources = (struct netSendResources*) (args->connector->transportResources);
...
if (args->state == ncclProxyOpProgress) {
int p = args->protocol;
int stepSize = args->connector->comm->buffSizes[p] / NCCL_STEPS;
char* localBuff = args->connector->conn.buffs[p];
void* mhandle = *(resources->mhandlesProto[p]);
args->idle = 1;
if (args->head < args->end) {
int buffSlot = args->tail%NCCL_STEPS;
if (args->tail < args->end && args->tail < args->head + NCCL_STEPS) {
volatile int* sizesFifo = resources->recvMem->sizesFifo;
volatile uint64_t* recvTail = &resources->recvMem->tail;
if (args->protocol == NCCL_PROTO_LL128) {
...
} else if (args->protocol == NCCL_PROTO_LL) {
...
} else if (args->tail < *recvTail) {
// Send through network
if (sizesFifo[buffSlot] != -1) {
NCCLCHECK(ncclNetIsend(resources->netSendComm, localBuff+buffSlot*stepSize, sizesFifo[buffSlot], mhandle, args->requests+buffSlot));
if (args->requests[buffSlot] != NULL) {
sizesFifo[buffSlot] = -1;
// Make sure size is reset to zero before we update the head.
__sync_synchronize();
args->tail += args->sliceSteps;
args->idle = 0;
}
}
}
}
...
}
...
}
return ncclSuccess;
}
If head is less than tail, it means there are asynchronously sent requests. It checks if sending is complete through ncclNetTest, and if so, updates head. Finally, if head equals end, it means this args has completed execution, and the state is changed to ncclProxyOpNone.
ncclResult_t netSendProxy(struct ncclProxyArgs* args) {
struct netSendResources* resources = (struct netSendResources*) (args->connector->transportResources);
...
if (args->state == ncclProxyOpProgress) {
...
if (args->head < args->end) {
int buffSlot = args->tail%NCCL_STEPS;
...
if (args->head < args->tail) {
int done;
int buffSlot = args->head%NCCL_STEPS;
NCCLCHECK(ncclNetTest(args->requests[buffSlot], &done, NULL));
if (done) {
args->head += args->sliceSteps;
resources->sendMem->head = args->head;
args->idle = 0;
}
}
}
if (args->head == args->end) {
resources->step = args->end;
args->idle = 0;
args->state = ncclProxyOpNone;
}
}
return ncclSuccess;
}
Network Communication Process#
Let’s examine how send and receive sides coordinate using RDMA as an example. For RDMA send/recv operations, when the send side executes an RDMA send, the receive side must have already posted a WR to its RQ, otherwise an error will occur. To solve this issue, a FIFO is introduced between the send and receive proxies, as shown in Figure 5.
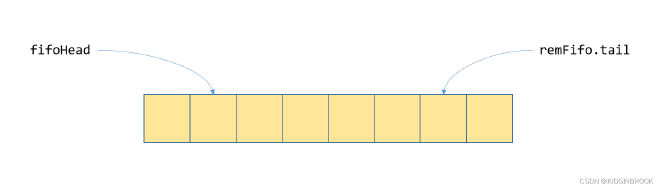
Figure 5
struct ncclIbSendFifo {
uint64_t addr;
int size;
uint32_t seq;
uint32_t rkey;
uint32_t ready;
};
Each element in the FIFO is an ncclIbSendFifo, with fifoHead held by the send side and remFifo.tail held by the receive side. For RDMA send/recv operations, the most important field is ‘ready’, while other fields are used for RDMA write scenarios. The FIFO is created by the send side, and during the RDMA connection process in ncclIbConnect, the corresponding FIFO memory is registered, then the FIFO address and rkey are sent to the receive side through socket. After posting each WR to the RQ, the receive side writes to the ncclIbSendFifo at the tail position of the send side’s FIFO using RDMA write. The send side can only execute send when ready is 1 at the fifoHead position.
Here’s an additional clarification regarding a question: in RDMA write scenarios where addr and rkey fields of ncclIbSendFifo are needed, suppose we call the fifoHead position in the FIFO a slot. When using RDMA write and finding slot->ready is 1, how can we ensure slot->addr and other fields are available (NIC has completed writing)? After consulting with Tuvie, since the slot size is small, it will be in the same PCIe TLP, and because ready is at the last position, when ready is available, other fields are guaranteed to be available as well.
Let’s look at the ncclIbSend logic. First, it gets the corresponding slot from the FIFO using fifoHead and checks ready. If it’s 1, sending is possible. Then it gets a req through ncclIbGetRequest, which represents the current request and will be used later to check if the communication is complete. After setting up the WR, where wr_id is set to the req address for later completion checking, it posts to the SQ and returns, storing the req in the corresponding FIFO position.
ncclResult_t ncclIbIsend(void* sendComm, void* data, int size, void* mhandle, void** request) {
struct ncclIbSendComm* comm = (struct ncclIbSendComm*)sendComm;
if (comm->ready == 0) NCCLCHECK(ncclSendCheck(comm));
if (comm->ready == 0) { *request = NULL; return ncclSuccess; }
struct ibv_mr* mr = (struct ibv_mr*)mhandle;
// Wait for the receiver to have posted the corresponding receive
volatile struct ncclIbSendFifo* slot = comm->fifo + (comm->fifoHead%MAX_REQUESTS);
volatile uint32_t * readyPtr = &slot->ready;
if (*readyPtr == 0) { *request = NULL; return ncclSuccess; }
struct ncclIbRequest* req;
NCCLCHECK(ncclIbGetRequest(comm->reqs, &req));
req->verbs = &comm->verbs;
req->size = size;
struct ibv_send_wr wr;
memset(&wr, 0, sizeof(wr));
wr.wr_id = (uint64_t)req;
struct ibv_sge sge;
if (size == 0) {
wr.sg_list = NULL;
wr.num_sge = 0;
} else {
sge.addr=(uintptr_t)data; sge.length=(unsigned int)size; sge.lkey=mr->lkey;
wr.sg_list = &sge;
wr.num_sge = 1;
}
wr.opcode = IBV_WR_SEND;
wr.send_flags = IBV_SEND_SIGNALED;
int useAr = 0;
if (size > ncclParamIbArThreshold()) {
useAr = 1;
}
// We must clear slot->ready, but reset other fields to aid
// debugging and sanity checks
slot->ready = 0;
slot->addr = 0ULL;
slot->rkey = slot->size = slot->seq = 0;
comm->fifoHead++;
struct ibv_send_wr* bad_wr;
NCCLCHECK(wrap_ibv_post_send(comm->qp, &wr, &bad_wr));
*request = req;
return ncclSuccess;
}
Next, let’s examine ncclIbTest, which checks if a specified req has completed sending. It gets the corresponding CQ from the req, then executes ibv_poll_cq to get the WC, obtains the wr_id from WC (which is the corresponding req), and sets this req’s done to 1. This loops until the specified req->done is 1.
ncclResult_t ncclIbTest(void* request, int* done, int* size) {
struct ncclIbRequest *r = (struct ncclIbRequest*)request;
*done = 0;
while (1) {
if (r->done == 1) {
*done = 1;
if (size) *size = r->size;
r->used = 0;
return ncclSuccess;
}
int wrDone = 0;
struct ibv_wc wcs[4];
NCCLCHECK(wrap_ibv_poll_cq(r->verbs->cq, 4, wcs, &wrDone));
if (wrDone == 0) return ncclSuccess;
for (int w=0; w<wrDone; w++) {
struct ibv_wc *wc = wcs+w;
if (wc->status != IBV_WC_SUCCESS) {
WARN("NET/IB : Got completion with error %d, opcode %d, len %d, vendor err %d", wc->status, wc->opcode, wc->byte_len, wc->vendor_err);
return ncclSystemError;
}
struct ncclIbRequest* doneReq = (struct ncclIbRequest*)wc->wr_id;
if (doneReq) {
if (wc->opcode == IBV_WC_RECV) {
doneReq->size = wc->byte_len;
}
doneReq->done = 1;
if (doneReq->free == 1) {
// This is an internal (FIFO post) req. Free it immediately.
doneReq->used = 0;
}
}
}
}
}
The receive-side proxy’s overall process is similar to the send side, but after executing ncclIbTest, it needs to execute ncclIbFlush.
ncclResult_t netRecvProxy(struct ncclProxyArgs* args) {
...
if (args->tail > args->head) {
int buffSlot = args->head%NCCL_STEPS;
int done, size;
NCCLCHECK(ncclNetTest(args->requests[buffSlot], &done, &size));
if (done) {
args->head += args->sliceSteps;
if (args->protocol == NCCL_PROTO_SIMPLE) {
if (resources->useGdr) NCCLCHECK(ncclNetFlush(resources->netRecvComm, localBuff+buffSlot*stepSize, size, mhandle));
resources->recvMem->tail = args->head;
}
args->idle = 0;
}
}
...
return ncclSuccess;
}
Below is the introduction about flush from section eight:
gpuFlush also corresponds to a QP, but this QP is local, meaning its peer QP is itself. When GDR is enabled, a flush needs to be executed after each data reception, which is actually an RDMA read operation, using the NIC to read the first int of the received data into hostMem. The official issue explains that when data reception completes through GDR and WC is generated to the CPU, the received data might not be readable on the GPU side yet, so a read operation needs to be executed on the CPU side.
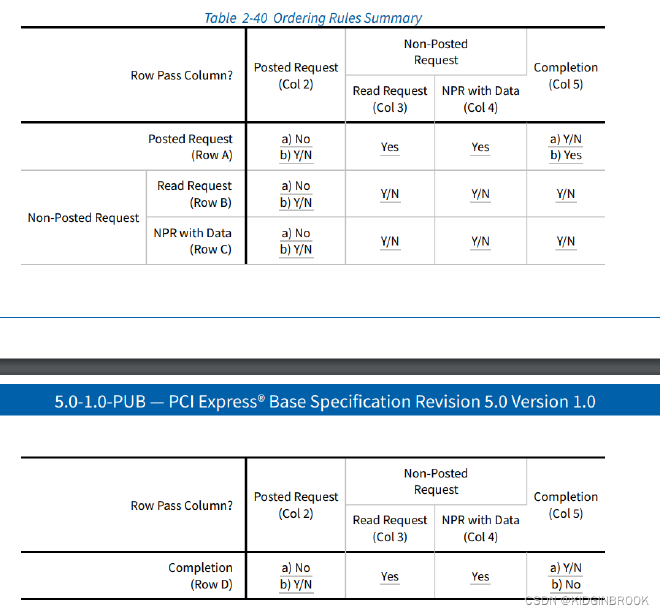
Regarding why reading ensures ordering, after consulting with kkndyu, it was explained that PCIe devices have a Transaction Ordering concept. In the same PCIe controller, Read Requests by default won’t bypass Posted Requests, as shown in col2 of the following diagram:
Finally, let’s summarize the overall multi-machine communication process:
- Communication is coordinated by kernel and proxy threads, where the send-side kernel moves data from input to buf, and the proxy thread sends data from buf to the receive side through the network
- Kernel and proxy implement producer-consumer pattern through queues
- Send side transmits data via RDMA send and implements producer-consumer pattern with receive side through queues located on the send side; receive side executes RDMA write to notify send side after posting each WR to RQ