Let’s continue from the last section where all nodes established bootstrap network connections, and now we’ll discuss topology analysis.
Since GPU machine architectures vary greatly, with a single machine potentially having multiple NICs and GPU cards with different interconnections, it’s necessary to analyze the device connection topology within machines to achieve optimal performance across various topological structures.
Continuing from before, let’s examine initTransportsRank.
static ncclResult_t initTransportsRank(struct ncclComm* comm, ncclUniqueId* commId) {
// We use 3 AllGathers
// 1. { peerInfo, comm }
// 2. ConnectTransport[nranks], ConnectValue[nranks]
// 3. { nThreads, nrings, compCap, prev[MAXCHANNELS], next[MAXCHANNELS] }
int rank = comm->rank;
int nranks = comm->nRanks;
uint64_t commHash = getHash(commId->internal, NCCL_UNIQUE_ID_BYTES);
TRACE(NCCL_INIT, "comm %p, commHash %lx, rank %d nranks %d - BEGIN", comm, commHash, rank, nranks);
NCCLCHECK(bootstrapInit(commId, rank, nranks, &comm->bootstrap));
// AllGather1 - begin
struct {
struct ncclPeerInfo peerInfo;
struct ncclComm* comm;
} *allGather1Data;
NCCLCHECK(ncclCalloc(&allGather1Data, nranks));
allGather1Data[rank].comm = comm;
struct ncclPeerInfo* myInfo = &allGather1Data[rank].peerInfo;
NCCLCHECK(fillInfo(comm, myInfo, commHash));
...
}
Creates nrank allGather1Data objects, then fills the current rank’s peerInfo through fillInfo. ncclPeerInfo contains basic rank information, such as rank number, which machine and process it belongs to, etc.
struct ncclPeerInfo {
int rank;
int cudaDev;
int gdrSupport;
uint64_t hostHash;
uint64_t pidHash;
dev_t shmDev;
int64_t busId;
};
static ncclResult_t fillInfo(struct ncclComm* comm, struct ncclPeerInfo* info, uint64_t commHash) {
info->rank = comm->rank;
CUDACHECK(cudaGetDevice(&info->cudaDev));
info->hostHash=getHostHash()+commHash;
info->pidHash=getPidHash()+commHash;
// Get the device MAJOR:MINOR of /dev/shm so we can use that
// information to decide whether we can use SHM for inter-process
// communication in a container environment
struct stat statbuf;
SYSCHECK(stat("/dev/shm", &statbuf), "stat");
info->shmDev = statbuf.st_dev;
info->busId = comm->busId;
NCCLCHECK(ncclGpuGdrSupport(&info->gdrSupport));
return ncclSuccess;
}
Gets the current card’s rank, PCIe busId, device number in /dev/shm, fills this into ncclPeerInfo, then checks GDR support through ncclGpuGdrSupport. RDMA needs to register memory before communication so the NIC knows virtual to physical address mapping. If data needs to be copied from GPU memory to system memory for each communication, efficiency would be low. IB provides peer memory interface allowing IB NICs to access other PCIe spaces. NVIDIA implemented its own driver based on peer memory, enabling RDMA to directly register GPU memory, avoiding host-device memory copies as IB can directly DMA GPU memory - this is GDR.
static ncclResult_t ncclGpuGdrSupport(int* gdrSupport) {
int netDevs;
NCCLCHECK(ncclNetDevices(&netDevs));
*gdrSupport = 0;
for (int dev=0; dev<netDevs; dev++) {
// Find a net device which is GDR-capable
ncclNetProperties_t props;
NCCLCHECK(ncclNet->getProperties(dev, &props));
if ((props.ptrSupport & NCCL_PTR_CUDA) == 0) continue;
// Allocate memory on the GPU and try to register it on the NIC.
void *lComm = NULL, *sComm = NULL, *rComm = NULL;
ncclNetHandle_t handle;
void* gpuPtr = NULL;
void* mHandle = NULL;
NCCLCHECK(ncclNetListen(dev, &handle, &lComm));
NCCLCHECK(ncclNetConnect(dev, &handle, &sComm));
NCCLCHECK(ncclNetAccept(lComm, &rComm));
CUDACHECK(cudaMalloc(&gpuPtr, GPU_BUF_SIZE));
ncclDebugNoWarn = NCCL_NET;
if (ncclNetRegMr(sComm, gpuPtr, GPU_BUF_SIZE, NCCL_PTR_CUDA, &mHandle) == ncclSuccess) {
NCCLCHECK(ncclNetDeregMr(sComm, mHandle));
NCCLCHECK(ncclNetRegMr(rComm, gpuPtr, GPU_BUF_SIZE, NCCL_PTR_CUDA, &mHandle));
NCCLCHECK(ncclNetDeregMr(rComm, mHandle));
*gdrSupport = 1;
}
ncclDebugNoWarn = 0;
CUDACHECK(cudaFree(gpuPtr));
NCCLCHECK(ncclNetCloseRecv(rComm));
NCCLCHECK(ncclNetCloseSend(sComm));
NCCLCHECK(ncclNetCloseListen(lComm));
break;
}
return ncclSuccess;
}
This iterates through each NIC to get its information. From the first section we know ncclNet here refers to ncclNetIb.
ncclResult_t ncclIbGdrSupport(int ibDev) {
static int moduleLoaded = -1;
if (moduleLoaded == -1) {
moduleLoaded = (access("/sys/kernel/mm/memory_peers/nv_mem/version", F_OK) == -1) ? 0 : 1;
}
if (moduleLoaded == 0) return ncclSystemError;
return ncclSuccess;
}
ncclResult_t ncclIbGetProperties(int dev, ncclNetProperties_t* props) {
props->name = ncclIbDevs[dev].devName;
props->pciPath = ncclIbDevs[dev].pciPath;
props->guid = ncclIbDevs[dev].guid;
props->ptrSupport = NCCL_PTR_HOST;
if (ncclIbGdrSupport(dev) != ncclSuccess) {
INFO(NCCL_NET,"NET/IB : GPU Direct RDMA Disabled for HCA %d '%s' (no module)", dev, ncclIbDevs[dev].devName);
} else {
props->ptrSupport |= NCCL_PTR_CUDA;
}
props->speed = ncclIbDevs[dev].speed;
props->port = ncclIbDevs[dev].port + ncclIbDevs[dev].realPort;
props->maxComms = ncclIbDevs[dev].maxQp;
return ncclSuccess;
}
This primarily gets the NIC name, PCIe path, GUID and other information, then checks for /sys/kernel/mm/memory_peers/nv_mem/version to determine if nv_peermem (NVIDIA’s driver) is installed. If installed, sets props->ptrSupport |= NCCL_PTR_CUDA indicating GPU memory can be registered.
Then attempts to register GPU memory. If registration succeeds, sets gdrSupport to 1. This actually creates RDMA connections, which we’ll cover separately later.
static ncclResult_t initTransportsRank(struct ncclComm* comm, ncclUniqueId* commId) {
...
NCCLCHECK(bootstrapAllGather(comm->bootstrap, allGather1Data, sizeof(*allGather1Data)));
NCCLCHECK(ncclCalloc(&comm->peerInfo, nranks+1)); // Extra rank to represent CollNet root
for (int i = 0; i < nranks; i++) {
memcpy(comm->peerInfo+i, &allGather1Data[i].peerInfo, sizeof(struct ncclPeerInfo));
if ((i != rank) && (comm->peerInfo[i].hostHash == myInfo->hostHash) && (comm->peerInfo[i].busId == myInfo->busId)) {
WARN("Duplicate GPU detected : rank %d and rank %d both on CUDA device %x", rank, i, myInfo->busId);
return ncclInvalidUsage;
}
}
// AllGather1 data is used again below
// AllGather1 - end
// Topo detection / System graph creation
NCCLCHECK(ncclTopoGetSystem(comm, &comm->topo));
...
}
Then bootstrapAllGather broadcasts allGather1Data, copying obtained peer info from other nodes into comm.
Before examining the specific topology analysis process, let’s briefly understand some PCIe concepts. Here’s a simple PCIe system example:
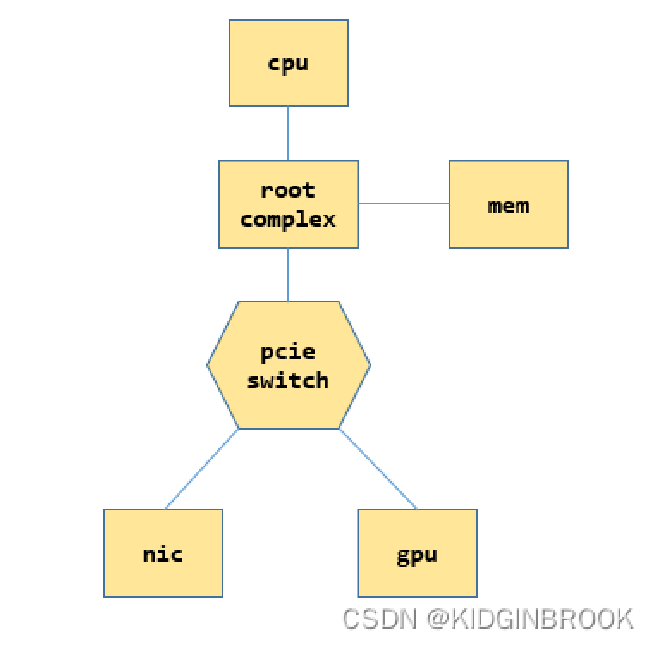
Each CPU has its own root complex (RC). RC helps CPU communicate with other parts like memory and PCIe system. When CPU sends a physical address, if it’s in PCIe space, RC converts it to PCIe requests for communication.
Switches expand PCIe ports and can connect to devices or other switches. Upstream requests are forwarded by them. PCIe devices can connect to RC or switches. Here’s a switch’s internal structure:
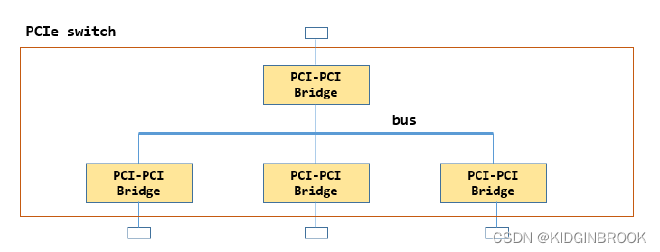
It has an internal PCIe bus with multiple bridges extending to multiple ports. The top one is called upstream port, others are downstream ports.
The previously mentioned busId in NCCL (for GPU and IB NICs) isn’t actually the bus number - it’s the BDF (bus + device + function) ID used to locate PCIe devices. A bus can have multiple devices, each with multiple functions, so BDF can locate specific devices. After machine completes PCIe configuration, related information is provided to users through sysfs, which NCCL uses for topology detection.
Let’s examine ncclTopoGetSystem, this section’s focus. It builds the current rank’s PCI tree in two steps: first representing the entire PCI tree structure in XML, then converting to ncclTopoNode. The XML is defined as follows, with ncclXmlNode representing a PCI tree node:
struct ncclXmlNode {
char name[MAX_STR_LEN];
struct {
char key[MAX_STR_LEN];
char value[MAX_STR_LEN];
} attrs[MAX_ATTR_COUNT+1]; // Need an extra one to consume extra params
int nAttrs;
int type;
struct ncclXmlNode* parent;
struct ncclXmlNode* subs[MAX_SUBS];
int nSubs;
};
struct ncclXml {
struct ncclXmlNode nodes[MAX_NODES];
int maxIndex;
};
ncclXmlNode represents a node, recording parent and all child nodes, with name and attributes set through xmlSetAttr.
ncclXml pre-allocates all nodes, with maxIndex indicating allocation progress. Here are some basic XML APIs:
static ncclResult_t xmlAddNode(struct ncclXml* xml, struct ncclXmlNode* parent, const char* subName, struct ncclXmlNode** sub);
xmlAddNode allocates a new node sub in XML, sets its name to subName with parent as the parent node.
static ncclResult_t xmlFindTagKv(struct ncclXml* xml, const char* tagName, struct ncclXmlNode** node, const char* attrName, const char* attrValue)
xmlFindTagKv traverses allocated XML nodes, finding node n named tagName, then checks if n[“attrName”] equals attrValue. If equal, sets node to n.
static ncclResult_t xmlGetAttrIndex(struct ncclXmlNode* node, const char* attrName, int* index)
xmlGetAttrIndex checks which attribute number attrName is for node.
Now let’s examine the topology analysis process:
ncclResult_t ncclTopoGetSystem(struct ncclComm* comm, struct ncclTopoSystem** system) {
struct ncclXml* xml;
NCCLCHECK(ncclCalloc(&xml, 1));
char* xmlTopoFile = getenv("NCCL_TOPO_FILE");
if (xmlTopoFile) {
INFO(NCCL_ENV, "NCCL_TOPO_FILE set by environment to %s", xmlTopoFile);
NCCLCHECK(ncclTopoGetXmlFromFile(xmlTopoFile, xml));
}
if (xml->maxIndex == 0) {
// Create top tag
struct ncclXmlNode* top;
NCCLCHECK(xmlAddNode(xml, NULL, "system", &top));
NCCLCHECK(xmlSetAttrInt(top, "version", NCCL_TOPO_XML_VERSION));
}
// Auto-detect GPUs if needed
for (int r=0; r<comm->nRanks; r++) {
if (comm->peerInfo[r].hostHash == comm->peerInfo[comm->rank].hostHash) {
char busId[NVML_DEVICE_PCI_BUS_ID_BUFFER_SIZE];
NCCLCHECK(int64ToBusId(comm->peerInfo[r].busId, busId));
struct ncclXmlNode* node;
NCCLCHECK(ncclTopoFillGpu(xml, busId, &node));
if (node == NULL) continue;
NCCLCHECK(xmlSetAttrInt(node, "rank", r));
NCCLCHECK(xmlInitAttrInt(node, "gdr", comm->peerInfo[r].gdrSupport));
}
}
...
}
First creates root node “system” via xmlAddNode, sets root node attribute “system”[“version”] = NCCL_TOPO_XML_VERSION, then iterates through each rank’s hosthash. If equal, indicates same machine, then executes ncclTopoFillGpu to add GPU to XML tree.
ncclResult_t ncclTopoFillGpu(struct ncclXml* xml, const char* busId, struct ncclXmlNode** gpuNode) {
struct ncclXmlNode* node;
NCCLCHECK(ncclTopoGetPciNode(xml, busId, &node));
NCCLCHECK(ncclTopoGetXmlFromSys(node, xml));
...
}
ncclResult_t ncclTopoGetPciNode(struct ncclXml* xml, const char* busId, struct ncclXmlNode** pciNode) {
NCCLCHECK(xmlFindTagKv(xml, "pci", pciNode, "busid", busId));
if (*pciNode == NULL) {
NCCLCHECK(xmlAddNode(xml, NULL, "pci", pciNode));
}
NCCLCHECK(xmlSetAttr(*pciNode, "busid", busId));
return ncclSuccess;
}
Uses ncclTopoGetPciNode to check if current card’s XML node exists in XML. If not, creates new XML node “pci” representing current GPU card, sets “pci”[“busid”]=busId.
Then executes ncclTopoGetXmlFromSys, which mainly gets GPU node to CPU path in sysfs, converts this path to XML tree, and sets related attributes from this path to XML.
ncclResult_t ncclTopoGetXmlFromSys(struct ncclXmlNode* pciNode, struct ncclXml* xml) {
// Fill info, then parent
const char* busId;
NCCLCHECK(xmlGetAttr(pciNode, "busid", &busId));
char* path = NULL;
int index;
NCCLCHECK(xmlGetAttrIndex(pciNode, "class", &index));
if (index == -1) {
if (path == NULL) NCCLCHECK(getPciPath(busId, &path));
NCCLCHECK(ncclTopoSetAttrFromSys(pciNode, path, "class", "class"));
}
NCCLCHECK(xmlGetAttrIndex(pciNode, "link_speed", &index));
if (index == -1) {
if (path == NULL) NCCLCHECK(getPciPath(busId, &path));
char deviceSpeedStr[MAX_STR_LEN];
float deviceSpeed;
NCCLCHECK(ncclTopoGetStrFromSys(path, "max_link_speed", deviceSpeedStr));
sscanf(deviceSpeedStr, "%f GT/s", &deviceSpeed);
char portSpeedStr[MAX_STR_LEN];
float portSpeed;
NCCLCHECK(ncclTopoGetStrFromSys(path, "../max_link_speed", portSpeedStr));
sscanf(portSpeedStr, "%f GT/s", &portSpeed);
NCCLCHECK(xmlSetAttr(pciNode, "link_speed", portSpeed < deviceSpeed ? portSpeedStr : deviceSpeedStr));
}
NCCLCHECK(xmlGetAttrIndex(pciNode, "link_width", &index));
if (index == -1) {
if (path == NULL) NCCLCHECK(getPciPath(busId, &path));
char strValue[MAX_STR_LEN];
NCCLCHECK(ncclTopoGetStrFromSys(path, "max_link_width", strValue));
int deviceWidth = strtol(strValue, NULL, 0);
NCCLCHECK(ncclTopoGetStrFromSys(path, "../max_link_width", strValue));
int portWidth = strtol(strValue, NULL, 0);
NCCLCHECK(xmlSetAttrInt(pciNode, "link_width", std::min(deviceWidth,portWidth)));
}
...
}
First sets various pciNode attributes, gets sysfs path corresponding to busId through getPciPath - this path represents root to leaf node path in PCI tree.
static ncclResult_t getPciPath(const char* busId, char** path) {
char busPath[] = "/sys/class/pci_bus/0000:00/../../0000:00:00.0";
memcpylower(busPath+sizeof("/sys/class/pci_bus/")-1, busId, BUSID_REDUCED_SIZE-1);
memcpylower(busPath+sizeof("/sys/class/pci_bus/0000:00/../../")-1, busId, BUSID_SIZE-1);
*path = realpath(busPath, NULL);
if (*path == NULL) {
WARN("Could not find real path of %s", busPath);
return ncclSystemError;
}
return ncclSuccess;
}
For example, if path is /sys/devices/pci0000:10/0000:10:00.0/0000:11:00.0/0000:12:00.0/0000:13:00.0/0000:14:00.0/0000:15:00.0/0000:16:00.0/0000:17:00.0, where GPU’s busId is 0000:17:00.0, it corresponds to this diagram (note: switch corresponding to 15:00.0 is omitted):
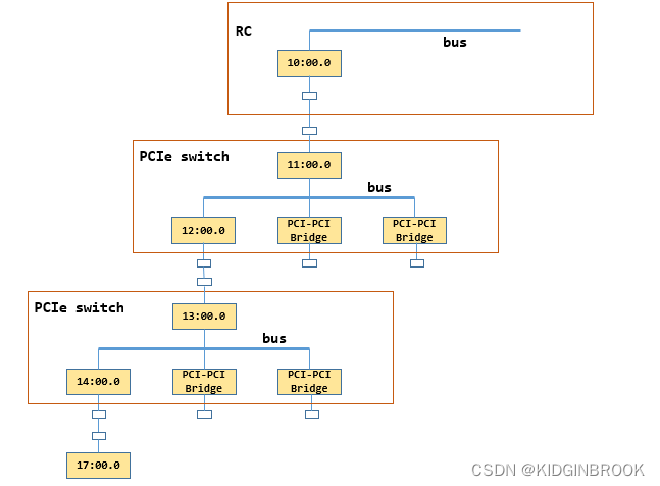
Then reads path properties, gets class (PCI device type), link_speed, link_width etc. and sets them in XML pciNode. ncclTopoGetStrFromSys simply reads kernel files under path into strValue.
ncclResult_t ncclTopoGetStrFromSys(const char* path, const char* fileName, char* strValue) {
char filePath[PATH_MAX];
sprintf(filePath, "%s/%s", path, fileName);
int offset = 0;
FILE* file;
if ((file = fopen(filePath, "r")) != NULL) {
while (feof(file) == 0 && ferror(file) == 0 && offset < MAX_STR_LEN) {
int len = fread(strValue+offset, 1, MAX_STR_LEN-offset, file);
offset += len;
}
fclose(file);
}
if (offset == 0) {
strValue[0] = '\0';
INFO(NCCL_GRAPH, "Topology detection : could not read %s, ignoring", filePath);
} else {
strValue[offset-1] = '\0';
}
return ncclSuccess;
}
ncclResult_t ncclTopoGetXmlFromSys(struct ncclXmlNode* pciNode, struct ncclXml* xml) {
// Fill info, then parent
...
struct ncclXmlNode* parent = pciNode->parent;
if (parent == NULL) {
if (path == NULL) NCCLCHECK(getPciPath(busId, &path));
// Save that for later in case next step is a CPU
char numaIdStr[MAX_STR_LEN];
NCCLCHECK(ncclTopoGetStrFromSys(path, "numa_node", numaIdStr));
// Go up one level in the PCI tree. Rewind two "/" and follow the upper PCI
// switch, or stop if we reach a CPU root complex.
int slashCount = 0;
int parentOffset;
for (parentOffset = strlen(path)-1; parentOffset>0; parentOffset--) {
if (path[parentOffset] == '/') {
slashCount++;
path[parentOffset] = '\0';
int start = parentOffset - 1;
while (start>0 && path[start] != '/') start--;
// Check whether the parent path looks like "BBBB:BB:DD.F" or not.
if (checkBDFFormat(path+start+1) == 0) {
// This a CPU root complex. Create a CPU tag and stop there.
struct ncclXmlNode* topNode;
NCCLCHECK(xmlFindTag(xml, "system", &topNode));
NCCLCHECK(xmlGetSubKv(topNode, "cpu", &parent, "numaid", numaIdStr));
if (parent == NULL) {
NCCLCHECK(xmlAddNode(xml, topNode, "cpu", &parent));
NCCLCHECK(xmlSetAttr(parent, "numaid", numaIdStr));
}
} else if (slashCount == 2) {
// Continue on the upper PCI switch
for (int i = strlen(path)-1; i>0; i--) {
if (path[i] == '/') {
NCCLCHECK(xmlFindTagKv(xml, "pci", &parent, "busid", path+i+1));
if (parent == NULL) {
NCCLCHECK(xmlAddNode(xml, NULL, "pci", &parent));
NCCLCHECK(xmlSetAttr(parent, "busid", path+i+1));
}
break;
}
}
}
}
if (parent) break;
}
pciNode->parent = parent;
parent->subs[parent->nSubs++] = pciNode;
}
if (strcmp(parent->name, "pci") == 0) {
NCCLCHECK(ncclTopoGetXmlFromSys(parent, xml));
} else if (strcmp(parent->name, "cpu") == 0) {
NCCLCHECK(ncclTopoGetXmlFromCpu(parent, xml));
}
free(path);
return ncclSuccess;
}
Then moves upward from pciNode. Since a switch’s upstream and downstream ports each correspond to a bridge, NCCL uses upstream port bridge’s busId to represent this switch. Therefore, it jumps up twice before creating new XML node for this switch. Increments slashCount for each PCI device found upward. When slashCount==2, finds switch upstream port, creates new XML pci node parent representing current switch, links current node pciNode to parent. Since parent is still XML pci node, recursively executes ncclTopoGetXmlFromSys until reaching RC. Then creates child node “cpu” under “system”, stops recursion, executes ncclTopoGetXmlFromCpu to set various “cpu” attributes like arch (e.g., x86 or arm), affinity (which CPU cores belong to this CPU’s NUMA), numaid etc.
This completes ncclTopoGetXmlFromSys. Back to ncclTopoFillGpu:
ncclResult_t ncclTopoFillGpu(struct ncclXml* xml, const char* busId, struct ncclXmlNode** gpuNode) {
...
NCCLCHECK(wrapNvmlSymbols());
NCCLCHECK(wrapNvmlInit());
nvmlDevice_t nvmlDev;
if (wrapNvmlDeviceGetHandleByPciBusId(busId, &nvmlDev) != ncclSuccess) nvmlDev = NULL;
NCCLCHECK(ncclTopoGetXmlFromGpu(node, nvmlDev, xml, gpuNode));
return ncclSuccess;
}
Loads dynamic library libnvidia-ml.so.1 through wrapNvmlSymbols to get GPU information.
ncclResult_t ncclTopoGetXmlFromGpu(struct ncclXmlNode* pciNode, nvmlDevice_t nvmlDev, struct ncclXml* xml, struct ncclXmlNode** gpuNodeRet) {
struct ncclXmlNode* gpuNode = NULL;
NCCLCHECK(xmlGetSub(pciNode, "gpu", &gpuNode));
if (gpuNode == NULL) NCCLCHECK(xmlAddNode(xml, pciNode, "gpu", &gpuNode));
int index = -1;
int dev = -1;
NCCLCHECK(xmlGetAttrIndex(gpuNode, "dev", &index));
if (index == -1) {
if (nvmlDev == NULL) {
WARN("No NVML, trying to use CUDA instead");
const char* busId;
NCCLCHECK(xmlGetAttr(pciNode, "busid", &busId));
if (busId == NULL || cudaDeviceGetByPCIBusId(&dev, busId) != cudaSuccess) dev = -1;
} else {
NCCLCHECK(wrapNvmlDeviceGetIndex(nvmlDev, (unsigned int*)&dev));
}
NCCLCHECK(xmlSetAttrInt(gpuNode, "dev", dev));
}
NCCLCHECK(xmlGetAttrInt(gpuNode, "dev", &dev));
if (dev == -1) { *gpuNodeRet = NULL; return ncclSuccess; }
NCCLCHECK(xmlGetAttrIndex(gpuNode, "sm", &index));
if (index == -1) {
int cudaMajor, cudaMinor;
if (nvmlDev == NULL) {
cudaDeviceProp devProp;
CUDACHECK(cudaGetDeviceProperties(&devProp, dev));
cudaMajor = devProp.major; cudaMinor = devProp.minor;
} else {
NCCLCHECK(wrapNvmlDeviceGetCudaComputeCapability(nvmlDev, &cudaMajor, &cudaMinor));
}
NCCLCHECK(xmlSetAttrInt(gpuNode, "sm", cudaMajor*10+cudaMinor));
}
int sm;
NCCLCHECK(xmlGetAttrInt(gpuNode, "sm", &sm));
struct ncclXmlNode* nvlNode = NULL;
NCCLCHECK(xmlGetSub(pciNode, "nvlink", &nvlNode));
if (nvlNode == NULL) {
// NVML NVLink detection
int maxNvLinks = (sm < 60) ? 0 : (sm < 70) ? 4 : (sm < 80) ? 6 : 12;
if (maxNvLinks > 0 && nvmlDev == NULL) {
WARN("No NVML device handle. Skipping nvlink detection.\n");
maxNvLinks = 0;
}
for (int l=0; l<maxNvLinks; ++l) {
// Check whether we can use this NVLink for P2P
unsigned canP2P;
if ((wrapNvmlDeviceGetNvLinkCapability(nvmlDev, l, NVML_NVLINK_CAP_P2P_SUPPORTED, &canP2P) != ncclSuccess) || !canP2P) continue;
// Make sure the Nvlink is up. The previous call should have trained the link.
nvmlEnableState_t isActive;
if ((wrapNvmlDeviceGetNvLinkState(nvmlDev, l, &isActive) != ncclSuccess) || (isActive != NVML_FEATURE_ENABLED)) continue;
// Try to figure out what's on the other side of the NVLink
nvmlPciInfo_t remoteProc;
if (wrapNvmlDeviceGetNvLinkRemotePciInfo(nvmlDev, l, &remoteProc) != ncclSuccess) continue;
// Make a lower case copy of the bus ID for calling ncclDeviceType
// PCI system path is in lower case
char* p = remoteProc.busId;
char lowerId[NVML_DEVICE_PCI_BUS_ID_BUFFER_SIZE];
for (int c=0; c<NVML_DEVICE_PCI_BUS_ID_BUFFER_SIZE; c++) {
lowerId[c] = tolower(p[c]);
if (p[c] == 0) break;
}
NCCLCHECK(xmlGetSubKv(gpuNode, "nvlink", &nvlNode, "target", lowerId));
if (nvlNode == NULL) {
NCCLCHECK(xmlAddNode(xml, gpuNode, "nvlink", &nvlNode));
NCCLCHECK(xmlSetAttr(nvlNode, "target", lowerId));
NCCLCHECK(xmlSetAttrInt(nvlNode, "count", 1));
} else {
int count;
NCCLCHECK(xmlGetAttrInt(nvlNode, "count", &count));
NCCLCHECK(xmlSetAttrInt(nvlNode, "count", count+1));
}
}
}
// Fill target classes
for (int s=0; s<gpuNode->nSubs; s++) {
struct ncclXmlNode* sub = gpuNode->subs[s];
if (strcmp(sub->name, "nvlink") != 0) continue;
int index;
NCCLCHECK(xmlGetAttrIndex(sub, "tclass", &index));
if (index == -1) {
const char* busId;
NCCLCHECK(xmlGetAttr(sub, "target", &busId));
if (strcmp(busId, "fffffff:ffff:ff") == 0) {
// Remote NVLink device is not visible inside this VM. Assume NVSwitch.
NCCLCHECK(xmlSetAttr(sub, "tclass", "0x068000"));
} else {
char* path;
NCCLCHECK(getPciPath(busId, &path));
NCCLCHECK(ncclTopoSetAttrFromSys(sub, path, "class", "tclass"));
}
}
}
*gpuNodeRet = gpuNode;
return ncclSuccess;
}
First creates node “gpu” under XML GPU node “pci”, sets “gpu” node attributes like dev, compute capability sm, then queries NVLink information. Iterates through all possible NVLinks, queries NVLink information through nvmlDeviceGetNvLinkCapability. If NVLink is enabled, creates new “nvlink” node under “gpu” node, sets “target” attribute indicating NVLink peer’s PCIe busId. Represents “nvlink” nodes with same “target” as one, uses “count” to indicate number of NVLinks between endpoints, sets “tclass” attribute indicating “target”’s PCI device type.
This completes ncclTopoFillGpu. XML now looks like this (showing single NIC case, where “gpu” and its parent node refer to same GPU):

Back to ncclTopoGetSystem, sets “gpu”’s rank and gdr attributes.
Then for all NICs, similar to GPU process, builds XML tree through ncclTopoGetXmlFromSys as shown (single NIC case, where “net”, “nic” and “nic”’s parent node represent same NIC):
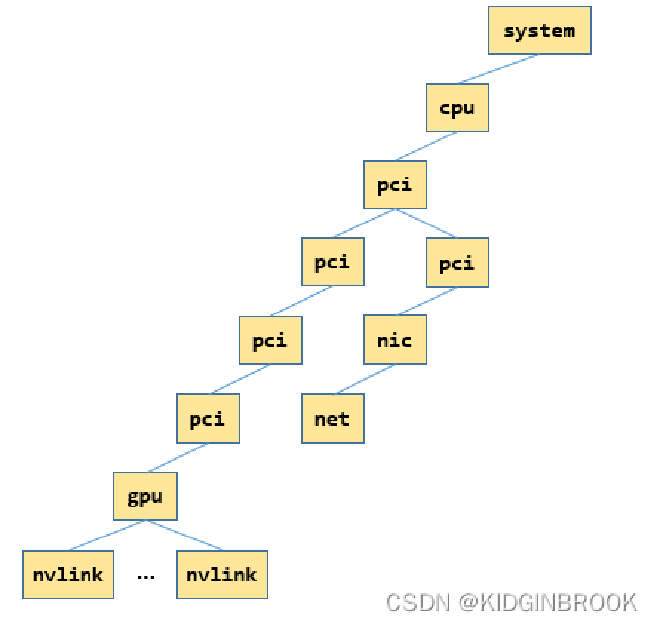
Finally, here’s what the corresponding XML looks like:
<system version="1">
<cpu numaid="0" affinity="00000000,0000000f,ffff0000,00000000,000fffff" arch="x86_64" vendor="GenuineIntel" familyid="6" modelid="85">
<pci busid="0000:11:00.0" class="0x060400" link_speed="8 GT/s" link_width="16">
<pci busid="0000:13:00.0" class="0x060400" link_speed="8 GT/s" link_width="16">
<pci busid="0000:15:00.0" class="0x060400" link_speed="8 GT/s" link_width="16">
<pci busid="0000:17:00.0" class="0x030200" link_speed="16 GT/s" link_width="16">
<gpu dev="0" sm="80" rank="0" gdr="1">
<nvlink target="0000:e7:00.0" count="2" tclass="0x068000"/>
<nvlink target="0000:e4:00.0" count="2" tclass="0x068000"/>
<nvlink target="0000:e6:00.0" count="2" tclass="0x068000"/>
<nvlink target="0000:e9:00.0" count="2" tclass="0x068000"/>
<nvlink target="0000:e5:00.0" count="2" tclass="0x068000"/>
<nvlink target="0000:e8:00.0" count="2" tclass="0x068000"/>
</gpu>
</pci>
</pci>
</pci>
<pci busid="0000:1c:00.0" class="0x020000" link_speed="8 GT/s" link_width="16">
<nic>
<net name="mlx5_0" dev="0" speed="100000" port="1" guid="0x82d0c0003f6ceb8" maxconn="262144" gdr="1"/>
</nic>
</pci>
</pci>
</cpu>
</system>
In summary, this section covered NCCL’s topology analysis process, building XML tree representation of PCI tree structure for GPUs and NICs using sysfs.