This is a Sonnet 3.6 translation of a Chinese article. Please be mindful of potential translation errors.
The previous section introduced the communication link establishment process. This section will cover the operation process of ncclSend and ncclRecv within a single machine.
Communication within a single machine is conducted through kernels, so the entire communication process can be divided into two steps: first, preparing kernel-related parameters, and second, the actual kernel execution process.
For ease of explanation, unless otherwise specified, the following examples will be based on a single-machine, single-thread, two-GPU scenario. Here’s the test case:
#include<stdio.h>#include"cuda_runtime.h"#include"nccl.h"#include<unistd.h>#include<stdint.h>#define CUDACHECK(cmd) do { \
cudaError_t e = cmd; \
if( e != cudaSuccess ) { \
printf("Failed: Cuda error %s:%d '%s'\n", \
__FILE__,__LINE__,cudaGetErrorString(e)); \
exit(EXIT_FAILURE); \
} \
} while(0)
#define NCCLCHECK(cmd) do { \
ncclResult_t r = cmd; \
if (r!= ncclSuccess) { \
printf("Failed, NCCL error %s:%d '%s'\n", \
__FILE__,__LINE__,ncclGetErrorString(r)); \
exit(EXIT_FAILURE); \
} \
} while(0)
intmain(intargc,char*argv[]){//each process is using two GPUs
intnDev=2;intnRanks=nDev;intchunk=1024*1024;intsize=nDev*chunk;float**sendbuff=(float**)malloc(nDev*sizeof(float*));float**recvbuff=(float**)malloc(nDev*sizeof(float*));cudaStream_t*s=(cudaStream_t*)malloc(sizeof(cudaStream_t)*nDev);//picking GPUs based on localRank
for(inti=0;i<nDev;++i){CUDACHECK(cudaSetDevice(i));CUDACHECK(cudaMalloc(sendbuff+i,size*sizeof(float)));CUDACHECK(cudaMalloc(recvbuff+i,size*sizeof(float)));CUDACHECK(cudaMemset(sendbuff[i],1,size*sizeof(float)));CUDACHECK(cudaMemset(recvbuff[i],0,size*sizeof(float)));CUDACHECK(cudaStreamCreate(s+i));}ncclUniqueIdid;ncclComm_tcomms[nDev];//generating NCCL unique ID at one process and broadcasting it to all
ncclGetUniqueId(&id);//initializing NCCL, group API is required around ncclCommInitRank as it is
//called across multiple GPUs in each thread/process
NCCLCHECK(ncclGroupStart());for(inti=0;i<nDev;i++){CUDACHECK(cudaSetDevice(i));NCCLCHECK(ncclCommInitRank(comms+i,nRanks,id,i));}NCCLCHECK(ncclGroupEnd());//calling NCCL communication API. Group API is required when using
//multiple devices per thread/process
NCCLCHECK(ncclGroupStart());for(inti=0;i<nDev;i++){for(intj=0;j<nDev;j++){NCCLCHECK(ncclSend((constvoid*)(sendbuff[i]+j*chunk),chunk,ncclFloat,j,comms[i],s[i]));NCCLCHECK(ncclRecv((void*)(recvbuff[i]+j*chunk),chunk,ncclFloat,j,comms[i],s[i]));}}NCCLCHECK(ncclGroupEnd());//synchronizing on CUDA stream to complete NCCL communication
for(inti=0;i<nDev;i++)CUDACHECK(cudaStreamSynchronize(s[i]));//freeing device memory
for(inti=0;i<nDev;i++){CUDACHECK(cudaFree(sendbuff[i]));CUDACHECK(cudaFree(recvbuff[i]));}//finalizing NCCL
for(inti=0;i<nDev;i++){ncclCommDestroy(comms[i]);}return0;}
ncclResult_tncclTopoComputeP2pChannels(structncclComm*comm){comm->p2pnChannels=std::min(comm->nChannels,(int)ncclParamMaxP2pNChannels());comm->p2pnChannels=std::max(comm->p2pnChannels,(int)ncclParamMinP2pNChannels());intminChannels=comm->p2pnChannels;// We need to loop through all local GPUs to have a global picture
for(intg=0;g<comm->topo->nodes[GPU].count;g++){for(intr=0;r<comm->nRanks;r++){intnChannels;NCCLCHECK(ncclTopoGetNchannels(comm->topo,g,r,&nChannels));if(nChannels>=0)minChannels=std::min(minChannels,nChannels);}}// Round to next pow2 nChannelsPerPeer and nChannels
comm->p2pnChannelsPerPeer=nextPow2(minChannels);comm->p2pnChannels=nextPow2(comm->p2pnChannels);// Init channels that weren't used so far
for(intc=comm->nChannels;c<comm->p2pnChannels;c++)NCCLCHECK(initChannel(comm,c));// We want to spread channels used when there aren't many and progressively
// fill the whole space of nChannels. To do so we mirror the bits in the
// nChannels space.
for(intc=0;c<comm->p2pnChannelsPerPeer;c++){intmirror=0;for(intb=1,mb=(comm->p2pnChannels>>1);b<comm->p2pnChannels;b<<=1,mb>>=1)if(c&b)mirror|=mb;comm->p2pChannels[c]=mirror;}INFO(NCCL_INIT,"%d coll channels, %d p2p channels, %d p2p channels per peer",comm->nChannels,comm->p2pnChannels,comm->p2pnChannelsPerPeer);returnncclSuccess;}
Previously, when establishing the ringGraph, a series of rings were searched and channels were created based on these rings. Assuming there are now nChannels channels in total, and p2p needs p2pnChannels channels, if p2pnChannels is greater than nChannels, an additional p2pnChannels - nChannels channels will be created, while others are reused; otherwise, they can be directly reused.
For each send/recv operation, p2pnChannelsPerPeer channels are used for parallel sending/receiving. When p2pnChannelsPerPeer is relatively small and p2pnChannels is large, this leads to only using the first few channels, unable to fully utilize all channels. For example, with p2pnChannelsPerPeer = 2 and p2pnChannels = 32, communications between rank0 and rank1, rank2 will all use channel[1] and channel[2]. To solve this issue, NCCL uses array p2pChannels[p2pnChannelsPerPeer] as an offset. For instance, if p2pChannels[0] = 0 and p2pChannels[1] = 16, then rank0 and rank1 communications will use channel[1] and channel[17], while rank0 and rank2 communications will use channel[2] and channel[18], making better use of channels.
For easier understanding, in subsequent examples we’ll assume both p2pnChannels and p2pnChannelsPerPeer are 1.
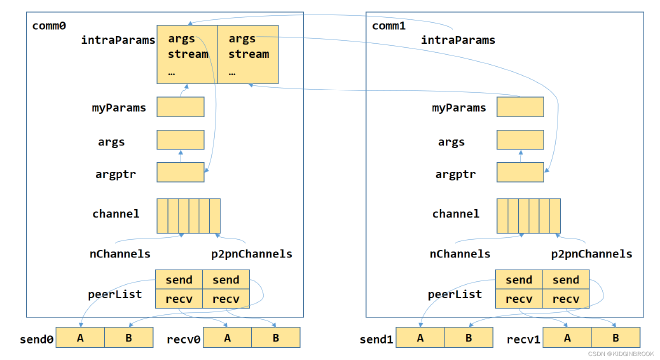
Next, let’s look at peerlist, which is actually a member of comm->p2plist. Figure 1 only shows the peerlist; see the comments below for specific meanings.
In Figure 1, both intraParams and myParams are of type cudaLaunchParams. Communication is actually completed through kernels, and cudaLaunchParams records the kernel parameters.
At the end of initTransportsRank, parameters are set. intraRank0 indicates which rank is the first rank on the current machine, intraRanks indicates how many ranks are on the current machine, and intraRank indicates which rank the current rank is on the current machine.
ncclResult_tncclCommSetIntra(structncclComm*comm,intrank,intranks,structncclComm*comm0){comm->intraRank=rank;comm->intraRanks=ranks;comm->intraPhase=0;// Alloc shared structures
if(rank==0){assert(comm==comm0);int*bar;NCCLCHECK(ncclCalloc(&bar,2));bar[0]=bar[1]=0;comm->intraBarrier=bar;NCCLCHECK(ncclCalloc(&comm->intraParams,comm->intraRanks));NCCLCHECK(ncclCalloc(&comm->intraCudaDevs,comm->intraRanks));int*CGMode;NCCLCHECK(ncclCalloc(&CGMode,1));*CGMode=0x11;comm->intraCGMode=CGMode;int*CC;NCCLCHECK(ncclCalloc(&CC,1));*CC=ncclCudaCompCap();comm->intraCC=CC;}else{comm->intraBarrier=(int*)waitForNonNullPtr(&comm0->intraBarrier);comm->intraParams=(structcudaLaunchParams*)waitForNonNullPtr(&comm0->intraParams);comm->intraCudaDevs=(int*)waitForNonNullPtr(&comm0->intraCudaDevs);comm->intraCGMode=(int*)waitForNonNullPtr(&comm0->intraCGMode);comm->intraCC=(int*)waitForNonNullPtr(&comm0->intraCC);}comm->intraCudaDevs[comm->intraRank]=comm->cudaDev;NCCLCHECK(initParams(comm));intcgMdLaunch=0;// Set CG Mode
comm->launchMode=ncclComm::GROUP;char*str=getenv("NCCL_LAUNCH_MODE");if(str)INFO(NCCL_ENV,"NCCL_LAUNCH_MODE set by environment to %s",str);if(comm->intraRanks==1||(str&&strcmp(str,"PARALLEL")==0)){comm->launchMode=ncclComm::PARALLEL;}if(comm->launchMode==ncclComm::GROUP){CUDACHECK(cudaStreamCreateWithFlags(&comm->groupStream,cudaStreamNonBlocking));#if CUDART_VERSION >= 9000
if(*comm->intraCC&&(ncclCudaCompCap()==*comm->intraCC)){// Check whether the GPU supports Cooperative Group Multi Device Launch
(void)cudaDeviceGetAttribute(&cgMdLaunch,cudaDevAttrCooperativeMultiDeviceLaunch,comm->cudaDev);}#endif
}// Disable cgMdLaunch if any rank does not support it
if(cgMdLaunch==0){*comm->intraCGMode=0x10;}returnncclSuccess;}
Then args and myParam are set through initParam, as shown in Figure 1.
ncclGroupStart simply increments ncclGroupMode. A non-zero ncclGroupMode indicates being in a Group operation. Operations between GroupStart and GroupEnd won’t block, and are submitted all at once through GroupEnd.
ncclResult_tncclEnqueueCheck(structncclInfo*info){// Launch asynchronously if needed
if(ncclAsyncMode()){ncclResult_tret=ncclSuccess;intsavedDev=-1;// Check arguments
NCCLCHECK(PtrCheck(info->comm,info->opName,"comm"));if(info->comm->checkPointers){CUDACHECKGOTO(cudaGetDevice(&savedDev),ret,end);CUDACHECKGOTO(cudaSetDevice(info->comm->cudaDev),ret,end);}NCCLCHECKGOTO(ArgsCheck(info),ret,end);// Always register comm even in case of error to make sure ncclGroupEnd
// cleans it up.
NCCLCHECKGOTO(ncclAsyncColl(info->comm),ret,end);NCCLCHECKGOTO(checkSetStream(info),ret,end);if(info->coll==ncclCollSendRecv){//p2p stored separately
NCCLCHECKGOTO(ncclSaveP2p(info),ret,end);}else{NCCLCHECKGOTO(ncclSaveKernel(info),ret,end);}end:if(savedDev!=-1)CUDACHECK(cudaSetDevice(savedDev));ncclAsyncErrCheck(ret);returnret;}
ncclGroupArgs and ncclGroupIndex are thread_local variables, indicating there are ncclGroupIndex AsyncArgs in total. Here it checks if there are AsyncArgs for the current comm in ncclGroupArgs. If not, a new one is added, setting funcType to ASYNC_FUNC_COLL and setting comm.
cpp12 lines hidden
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
ncclResult_tncclAsyncColl(ncclComm_tcomm){structncclAsyncArgs*args=ncclGroupArgs;for(inti=0;i<ncclGroupIndex;i++){if(args->coll.comm==comm)returnncclSuccess;args++;}if(ncclGroupIndex>=MAX_ASYNC_OPS){WARN("Too many async operations in progress, max is %d",MAX_ASYNC_OPS);returnncclAsyncErrCheck(ncclInvalidUsage);}ncclGroupIndex++;args->funcType=ASYNC_FUNC_COLL;args->coll.comm=comm;returnncclSuccess;}
Then comm->userStream is set to info->stream.
cpp7 lines hidden
1
2
3
4
5
6
7
8
9
10
staticncclResult_tcheckSetStream(structncclInfo*info){if(info->comm->userStreamSet==false){info->comm->userStream=info->stream;info->comm->userStreamSet=true;}elseif(info->stream!=info->comm->userStream){WARN("Error : mixing different streams within a group call is not supported.");returnncclInvalidUsage;}returnncclSuccess;}
Then ncclSaveP2p is executed, saving p2p-related information to comm’s p2plist. peer indicates who to send to, where delta means (rank + delta) % nranks = peer, so the corresponding channel can be found through rank + delta. p2pnChannelsPerPeer channels will execute data transmission in parallel. If the channel hasn’t established a connection with the peer yet, connection information needs to be recorded first. For example, for send on the id-th channel, peer will be recorded at send[id * nranks + nsend[id]], then nsend[id] is incremented to facilitate subsequent connection establishment logic. Finally, sendbuff and data length are recorded in the corresponding peer in peerlist, as shown in Figure 1.
Then ncclGroupEnd begins execution. Since ncclGroupMode is non-zero at this point, it returns directly, completing ncclSend execution.
cpp6 lines hidden
1
2
3
4
5
6
7
8
9
ncclResult_tncclGroupEnd(){if(ncclGroupMode==0){WARN("ncclGroupEnd: not in a group call.");returnncclInvalidUsage;}ncclGroupMode--;if(ncclGroupMode>0)returnncclSuccess;...}
Next is the ncclRecv process, which is identical to ncclSend. After execution, recv-related information is also saved to p2plist.
Then ncclGroupEnd begins execution. Previously, ncclSend and ncclRecv wrote related information to p2plist. The first step now is to establish connections if they don’t exist.
ncclResult_tncclGroupEnd(){if(ncclGroupMode==0){WARN("ncclGroupEnd: not in a group call.");returnncclInvalidUsage;}ncclGroupMode--;if(ncclGroupMode>0)returnncclSuccess;intsavedDev;CUDACHECK(cudaGetDevice(&savedDev));intactiveThreads=0;intdoneArray[MAX_ASYNC_OPS];for(inti=0;i<ncclGroupIndex;i++)doneArray[i]=1;ncclResult_tret=ncclGroupError;if(ret!=ncclSuccess)gotogroup_cleanup;/* Launch async ncclCommInitRank */...for(inti=0;i<ncclGroupIndex;i++){structncclAsyncArgs*args=ncclGroupArgs+i;if(args->funcType==ASYNC_FUNC_COLL){structncclP2Plist*p2plist=&args->coll.comm->p2plist;if(p2plist->count!=0){structncclComm*comm=args->coll.comm;args->coll.connect=0;for(intc=0;c<comm->p2pnChannels;c++)args->coll.connect+=comm->p2plist.connect.nsend[c]+comm->p2plist.connect.nrecv[c];if(args->coll.connect){pthread_create(ncclGroupThreads+i,NULL,ncclAsyncThreadPreconnect,args);}}}}for(inti=0;i<ncclGroupIndex;i++){structncclAsyncArgs*args=ncclGroupArgs+i;if(args->funcType==ASYNC_FUNC_COLL&&(args->coll.connect)){interr=pthread_join(ncclGroupThreads[i],NULL);if(err!=0){WARN("Error waiting for pthread_join : %s\n",strerror(errno));returnncclSystemError;}NCCLCHECKGOTO(args->ret,ret,end);}}...}
A thread is started for each AsyncArgs to execute ncclAsyncThreadPreconnect. Here ncclTransportP2pSetup needs to be executed for each p2p channel, with nsend, send, and other related information recorded in p2plist.
Then all ncclSend and ncclRecv tasks are distributed to various channels. For each AsyncArgs, iterate through each delta to get who to send to (to) and receive from (from), then use p2pnChannelsPerPeer channels to send and receive in parallel, with each channel handling sendbytes / p2pnChannelsPerPeer size. In the above example, rank0 (first AsyncArgs) will execute scheduleSendRecv twice, first with from=to=0, second with from=to=1.
ncclResult_tncclGroupEnd(){...for(inti=0;i<ncclGroupIndex;i++){structncclAsyncArgs*args=ncclGroupArgs+i;if(args->funcType==ASYNC_FUNC_COLL){structncclComm*comm=args->coll.comm;intrank=comm->rank;intnRanks=comm->nRanks;structncclP2Plist*p2plist=&args->coll.comm->p2plist;if(p2plist->count){for(intdelta=0;delta<nRanks;delta++){uint32_tfrom=(rank+nRanks-delta)%nRanks;uint32_tto=(rank+delta)%nRanks;// Compute how much to split operations
// Natural step size matching buffer steps.
ssize_tstepSize=4*comm->buffSizes[NCCL_PROTO_SIMPLE]/NCCL_STEPS;// Split each operation on p2pnChannelsPerPeer max.
ssize_trecvChunkSize=DIVUP(p2plist->peerlist[from].recvbytes,comm->p2pnChannelsPerPeer);ssize_tsendChunkSize=DIVUP(p2plist->peerlist[to].sendbytes,comm->p2pnChannelsPerPeer);recvChunkSize=std::max((ssize_t)1,DIVUP(recvChunkSize,stepSize))*stepSize;sendChunkSize=std::max((ssize_t)1,DIVUP(sendChunkSize,stepSize))*stepSize;ssize_tsendOffset=0;ssize_trecvOffset=0;intremaining=1;intchunk=0;while(remaining){intchannelId=(delta+comm->p2pChannels[chunk%comm->p2pnChannelsPerPeer])%comm->p2pnChannels;remaining=0;ssize_trecvbytes=p2plist->peerlist[from].recvbytes-recvOffset;ssize_tsendbytes=p2plist->peerlist[to].sendbytes-sendOffset;if(recvbytes>recvChunkSize){remaining=1;recvbytes=recvChunkSize;}elsep2plist->peerlist[from].recvbytes=-1;if(sendbytes>sendChunkSize){remaining=1;sendbytes=sendChunkSize;}elsep2plist->peerlist[to].sendbytes=-1;if(sendbytes>=0||recvbytes>=0){NCCLCHECKGOTO(scheduleSendRecv(comm,delta,channelId,recvbytes,((char*)(p2plist->peerlist[from].recvbuff))+recvOffset,sendbytes,((constchar*)(p2plist->peerlist[to].sendbuff))+sendOffset),ret,end);}recvOffset+=recvChunkSize;sendOffset+=sendChunkSize;chunk++;}}p2plist->count=0;}}}...}
Then generate an ncclInfo, recording channelId, sendbuff, recvbuff and other information, and execute ncclSaveKernel.
Then set kernel-related parameters through ncclSaveKernel, namely ncclColl. The args type in Figure 1 is ncclColl. As mentioned in section 7, collectives (ncclColl array) are allocated for each channel during initChannel.
structncclColl{union{struct{structCollectiveArgsargs;uint16_tfuncIndex;// 应该使用哪个kernel
uint16_tnextIndex;// 下一个ncclColl
uint8_tactive;// 当前ncclColl是否被占用
};intdata[0x10];};};structCollectiveArgs{structncclDevComm*comm;// local and remote input, output, and buffer
constvoid*sendbuff;void*recvbuff;// Op-specific fields. Make sure the common part stays the
// same on all structs of the union
union{struct{uint16_tnThreads;}common;struct{uint16_tnThreads;uint8_tbid;uint8_tnChannels;uint32_troot;size_tcount;size_tlastChunkSize;}coll;struct{uint16_tnThreads;uint16_tunused;int32_tdelta;size_tsendCount;size_trecvCount;}p2p;};};
computeColl initializes ncclColl coll using ncclInfo, including sendbuf, recvbuf, comm, etc., then sets myParams’ blockDim. Find the channel using channelId from info, try to add the current coll to channel’s collectives. collFifoTail is the tail of collectives, corresponding ncclColl is c. First wait for c’s active until not occupied, then copy coll to c, set active to 1, increment channel’s collcount, point collFifoTail to next ncclColl, set c’s nextIndex to collFifoTail. Note that ncclProxySaveP2p has no effect in current scenario, so it’s omitted.
ncclResult_tncclSaveKernel(structncclInfo*info){if(info->comm->nRanks==1&&info->coll!=ncclCollSendRecv){if(info->sendbuff!=info->recvbuff)CUDACHECK(cudaMemcpyAsync(info->recvbuff,info->sendbuff,info->nBytes,cudaMemcpyDeviceToDevice,info->stream));returnncclSuccess;}structncclCollcoll;structncclProxyArgsproxyArgs;memset(&proxyArgs,0,sizeof(structncclProxyArgs));NCCLCHECK(computeColl(info,&coll,&proxyArgs));info->comm->myParams->blockDim.x=std::max<unsigned>(info->comm->myParams->blockDim.x,info->nThreads);intnChannels=info->coll==ncclCollSendRecv?1:coll.args.coll.nChannels;intnSubChannels=(info->pattern==ncclPatternCollTreeUp||info->pattern==ncclPatternCollTreeDown)?2:1;for(intbid=0;bid<nChannels*nSubChannels;bid++){intchannelId=(info->coll==ncclCollSendRecv)?info->channelId:info->comm->myParams->gridDim.x%info->comm->nChannels;structncclChannel*channel=info->comm->channels+channelId;if(channel->collCount==NCCL_MAX_OPS){WARN("Too many aggregated operations on channel %d (%d max)",channel->id,NCCL_MAX_OPS);returnncclInvalidUsage;}// Proxy
proxyArgs.channel=channel;// Adjust pattern for CollNet based on channel index
if(nSubChannels==2){info->pattern=(channelId<info->comm->nChannels/nSubChannels)?ncclPatternCollTreeUp:ncclPatternCollTreeDown;}if(info->coll==ncclCollSendRecv){info->comm->myParams->gridDim.x=std::max<unsigned>(info->comm->myParams->gridDim.x,channelId+1);NCCLCHECK(ncclProxySaveP2p(info,channel));}else{NCCLCHECK(ncclProxySaveColl(&proxyArgs,info->pattern,info->root,info->comm->nRanks));}info->comm->myParams->gridDim.x++;intopIndex=channel->collFifoTail;structncclColl*c=channel->collectives+opIndex;volatileuint8_t*activePtr=(volatileuint8_t*)&c->active;while(activePtr[0]!=0)sched_yield();memcpy(c,&coll,sizeof(structncclColl));if(info->coll!=ncclCollSendRecv)c->args.coll.bid=bid%coll.args.coll.nChannels;c->active=1;opIndex=(opIndex+1)%NCCL_MAX_OPS;c->nextIndex=opIndex;channel->collFifoTail=opIndex;channel->collCount++;}info->comm->opCount++;returnncclSuccess;}
At this point scheduleSendRecv execution is complete. Back to ncclGroupEnd, it will execute ncclBarrierEnqueue for each AsyncArgs
We mentioned during channel search that one channel corresponds to one block. Here in setupLaunch we can see it iterates through p2p channels, setting gridDim.x to the number of channels. However, since some channels don’t have p2p operations, a fake ncclColl needs to be created for these empty channels, setting delta to -1 to indicate no p2p operations, and setting funcIndex, comm and other information. Then set the last ncclColl’s active to 2 indicating it’s the last ncclColl. Then copy the first ncclColl of the first channel to comm->args and set func in myParam, completing kernel parameter setup.
ncclResult_tsetupLaunch(structncclComm*comm,structcudaLaunchParams*params){// Only launch blocks where we have work to do.
for(intc=0;c<comm->p2pnChannels;c++){if(comm->channels[c].collCount)params->gridDim.x=c+1;}// Set active = 2 for the last operation and add a no-op on empty channels (p2p case).
for(intc=0;c<params->gridDim.x;c++){structncclChannel*channel=comm->channels+c;if(channel->collCount==0){intopIndex=channel->collFifoTail;structncclColl*c=channel->collectives+opIndex;volatileuint8_t*activePtr=(volatileuint8_t*)&c->active;while(activePtr[0]!=0)sched_yield();c->args.p2p.delta=-1;// no-op
c->funcIndex=FUNC_INDEX_P2P;c->args.comm=comm->devComm;c->active=1;opIndex=(opIndex+1)%NCCL_MAX_OPS;c->nextIndex=opIndex;channel->collFifoTail=opIndex;channel->collCount++;}channel->collectives[(channel->collStart+channel->collCount-1)%NCCL_MAX_OPS].active=2;}// Find the first operation, choose the kernel accordingly and pass it
// as the first argument.
structncclColl*coll=comm->channels[0].collectives+comm->channels[0].collStart;memcpy(&comm->args,coll,sizeof(structncclColl));// As we pass that coll directly, we can free it immediately.
coll->active=0;params->func=ncclKerns[coll->funcIndex];returnncclSuccess;}
Then back to ncclBarrierEnqueue, ncclCpuBarrierIn will be executed.
cpp11 lines hidden
1
2
3
4
5
6
7
8
9
10
11
12
13
14
ncclResult_tncclBarrierEnqueue(structncclComm*comm){...if(comm->launchMode==ncclComm::GROUP){intisLast=0;NCCLCHECK(ncclCpuBarrierIn(comm,&isLast));if(isLast){// I'm the last. Launch all operations.
NCCLCHECK(ncclLaunchCooperativeKernelMultiDevice(comm->intraParams,comm->intraCudaDevs,comm->intraRanks,*comm->intraCGMode));NCCLCHECK(ncclCpuBarrierLast(comm));}}returnncclSuccess;}
Here cas operations are performed on intraBarrier until isLast is set to 1 on the intraRanks-th execution of ncclBarrierEnqueue. In other words, kernel will only start on execution of the last AsyncArgs.
ncclResult_tncclCpuBarrierIn(structncclComm*comm,int*isLast){volatileint*ptr=(volatileint*)(comm->intraBarrier+comm->intraPhase);intval=*ptr;booldone=false;while(done==false){if(val>=comm->intraRanks){WARN("Trying to launch too many collectives");returnncclInvalidUsage;}if(val+1==comm->intraRanks){// Reset the barrier.
comm->intraBarrier[comm->intraPhase^1]=0;*isLast=1;returnncclSuccess;}done=__sync_bool_compare_and_swap(ptr,val,val+1);val++;}*isLast=0;returnncclSuccess;}
Then launch kernels on multiple devices at once through cudaLaunchCooperativeKernelMultiDevice.
cpp16 lines hidden
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
ncclResult_tncclLaunchCooperativeKernelMultiDevice(structcudaLaunchParams*paramsList,int*cudaDevs,intnumDevices,intcgMode){#if CUDART_VERSION >= 9000
if(cgMode&0x01){CUDACHECK(cudaLaunchCooperativeKernelMultiDevice(paramsList,numDevices,// These flags are to reduce the latency of using this API
cudaCooperativeLaunchMultiDeviceNoPreSync|cudaCooperativeLaunchMultiDeviceNoPostSync));returnncclSuccess;}#endif
intsavedDev;CUDACHECK(cudaGetDevice(&savedDev));for(inti=0;i<numDevices;i++){structcudaLaunchParams*params=paramsList+i;CUDACHECK(cudaSetDevice(cudaDevs[i]));CUDACHECK(cudaLaunchKernel(params->func,params->gridDim,params->blockDim,params->args,params->sharedMem,params->stream));}CUDACHECK(cudaSetDevice(savedDev));returnncclSuccess;}
The first ncclColl is passed through parameters to the kernel, so block 0’s c can be directly set to firstcoll. Other blocks need to use load_coll for copying. After loading, the host’s ncclColl active can be set to 0.
cpp10 lines hidden
1
2
3
4
5
6
7
8
9
10
11
12
13
static__device__voidload_parallel(void*dst,void*src,size_tsize,inttid){int*d=(int*)dst;int*s=(int*)src;for(into=tid;o<(size/sizeof(int));o+=blockDim.x)d[o]=s[o];}static__device__voidload_coll(structncclColl*localColl,structncclColl*hostColl,inttid,structncclDevComm*comm){// Check whether the last operation was aborted and make sure all threads exit
intabort=tid==0?*(comm->abortFlag):0;exitIfAbortBarrier(abort);load_parallel(localColl,hostColl,sizeof(structncclColl),tid);__syncthreads();if(tid==0)hostColl->active=0;}
Then begins the while loop to iterate through each ncclColl until ncclColl’s active becomes 2, indicating it’s the last one, at which point the loop exits.
#define IMPL_COLL_KERN(coll, op, ncclFunc, dtype, ctype, fIndex) \
__global__ void NCCL_KERN_NAME(coll, op, dtype)(struct ncclColl firstColl) { \
int tid = threadIdx.x; \
int bid = blockIdx.x; \
__shared__ volatile uint64_t shmem[NCCL_LL128_SHMEM_SIZE]; \
ncclShmem = shmem; \
__shared__ struct ncclColl localColl; \
\
struct ncclDevComm* comm = firstColl.args.comm; \
struct ncclChannel* channel = comm->channels+bid; \
struct ncclColl* c; \
if (bid == 0) { \
/* To optimize for latency, (only) the first operation is passed as argument.*/ \
c = &firstColl; \
} else { \
c = &localColl; \
load_coll(c, channel->collectives+channel->collFifoHead, tid, comm); \
} \
while (1) { \
if (tid < c->args.common.nThreads) { \
if (c->funcIndex == fIndex) { \
coll##Kernel<COLL_UNROLL, ncclFunc<ctype>, ctype>(&c->args); \
} else { \
ncclFuncs[c->funcIndex](&c->args); \
} \
} \
int nextIndex = c->nextIndex; \
if (tid == 0) channel->collFifoHead = nextIndex; \
\
if (c->active == 2) { \
return; \
} \
\
/* Load next collective operation*/ \
c = &localColl; /* for bid 0 */ \
load_coll(c, channel->collectives+nextIndex, tid, comm); \
} \
}
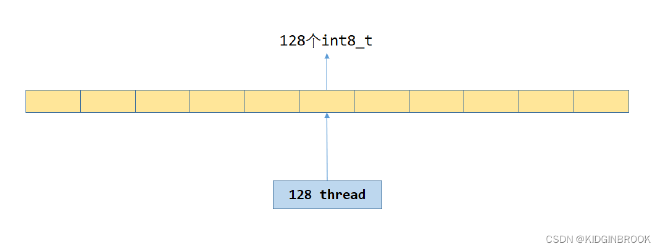
For each ncclColl, ncclSendRecvKernel<4, FuncSum<int8_t>, int8_t> is executed. Let’s first look at thread organization within a block. Assuming args->p2p.nThreads is 320, 160 threads are used for send and 160 for recv. Further, of the 160 threads, 128 are used for actual data transfer, and the remaining 32 threads (one warp) are used for synchronization.
First, calculate nthreads, which is 256 here. Get sendbuff and recvbuff from args. If delta is negative, it means this channel has no p2p operation and is fake, so return directly. If delta is 0, it’s send/recv between the same card, so execute data copy directly through ReduceOrCopyMulti, with blockSize being the copy length each time.
template<intUNROLL,classFUNC,typenameT>__device__voidncclSendRecvKernel(structCollectiveArgs*args){constinttid=threadIdx.x;constintnthreads=args->p2p.nThreads-2*WARP_SIZE;// Compute pointers
constT*sendbuff=(constT*)args->sendbuff;T*recvbuff=(T*)args->recvbuff;if(args->p2p.delta<0)return;// No-op
if(args->p2p.delta==0){if(tid<nthreads&&sendbuff!=recvbuff){// local copy : ReduceOrCopyMulti takes an int as number of elements,
// so we split it in blocks of 1G elements.
intblockSize=1<<30;for(size_toffset=0;offset<args->p2p.sendCount;offset+=blockSize){size_tremaining=args->p2p.sendCount-offset;if(remaining<blockSize)blockSize=remaining;ReduceOrCopyMulti<UNROLL,FUNC,T,1,1,1,1>(tid,nthreads,1,&sendbuff,1,&recvbuff,blockSize);sendbuff+=blockSize;recvbuff+=blockSize;}}return;}...}
Then let’s look at ReduceOrCopyMulti, which handles actual data copying, reducing nsrcs source arrays through FUNC and copying to ndsts destination arrays, each array having length N. ReduceOrCopyMulti attempts to use 128-bit vectorized load/store to improve bandwidth utilization and reduce instruction count for better performance, but this requires aligned data (16 bytes). If src and dst aren’t 16-byte aligned but have the same remainder when divided by 16, then non-vectorized instructions can be used to copy the unaligned front portion, after which vectorized instructions can be used. If the remainders are different, only non-vectorized instructions can be used. The process has three steps: handle the unaligned front portion, handle the aligned middle portion, and handle the tail portion.
ptrAlign128 takes modulo 16. First, it uses XOR to check if srcs and dsts alignment is consistent. If inconsistent, Npreamble = N, and non-vectorized instructions must be used for all copying. Otherwise, Npreamble = (alignof(Pack128) - align) % alignof(Pack128), which is the unaligned front portion.
typedefulong2Pack128;template<typenameT>__device__intptrAlign128(T*ptr){return(uint64_t)ptr%alignof(Pack128);}template<intUNROLL,classFUNC,typenameT,intMINSRCS,intMAXSRCS,intMINDSTS,intMAXDSTS>__device____forceinline__voidReduceOrCopyMulti(constinttid,constintnthreads,intnsrcs,constT*srcs[MAXSRCS],intndsts,T*dsts[MAXDSTS],intN){intNrem=N;if(Nrem<=0)return;intalignDiff=0;intalign=ptrAlign128(srcs[0]);#pragma unroll
for(inti=1;i<MINSRCS;i++)alignDiff|=(align^ptrAlign128(srcs[i]));for(inti=MINSRCS;i<MAXSRCS&&i<nsrcs;i++)alignDiff|=(align^ptrAlign128(srcs[i]));#pragma unroll
for(inti=0;i<MINDSTS;i++)alignDiff|=(align^ptrAlign128(dsts[i]));for(inti=MINDSTS;i<MAXDSTS&&i<ndsts;i++)alignDiff|=(align^ptrAlign128(dsts[i]));intNpreamble=alignDiff?Nrem:N<alignof(Pack128)?N:(alignof(Pack128)-align)%alignof(Pack128);// stage 1: preamble: handle any elements up to the point of everything coming
// into alignment
if(Npreamble){ReduceCopyMulti<FUNC,T,MINSRCS,MAXSRCS,MINDSTS,MAXDSTS>(tid,nthreads,nsrcs,srcs,ndsts,dsts,0,Npreamble);Nrem-=Npreamble;if(Nrem==0)return;}...}
For the unaligned portion, directly use ReduceCopyMulti with non-vectorized instructions. 128 threads read consecutive 128 int8_t from src and store to dst, executing in loops. The access pattern is shown in the following figure.
Then starts step two, handling aligned data. This is done in two parts: first, for data that’s divisible by packFactor * AUTOUNROLL * WARP_SIZE, execute ReduceCopy128bMulti with AUTOUNROLL enabled. For remaining data, set AUTOUNROLL to 1 and execute ReduceCopy128bMulti.
Finally, for data less than packFactor (can’t form 128 bits), use ReduceCopyMulti for non-vectorized copying.
template<intUNROLL,classFUNC,typenameT,intMINSRCS,intMAXSRCS,intMINDSTS,intMAXDSTS>__device____forceinline__voidReduceOrCopyMulti(constinttid,constintnthreads,intnsrcs,constT*srcs[MAXSRCS],intndsts,T*dsts[MAXDSTS],intN){...intoffset=Npreamble;// stage 2: fast path: use 128b loads/stores to do the bulk of the work,
// assuming the pointers we have are all 128-bit alignable.
intw=tid/WARP_SIZE;// Warp number
intnw=nthreads/WARP_SIZE;// Number of warps
intt=tid%WARP_SIZE;// Thread (inside the warp)
constintpackFactor=sizeof(Pack128)/sizeof(T);// stage 2a: main loop
intNpack2a=(Nrem/(packFactor*AUTOUNROLL*WARP_SIZE))*(AUTOUNROLL*WARP_SIZE);// round down
intNelem2a=Npack2a*packFactor;ReduceCopy128bMulti<FUNC,T,AUTOUNROLL,MINSRCS,MAXSRCS,MINDSTS,MAXDSTS>(w,nw,t,nsrcs,srcs,ndsts,dsts,offset,Npack2a);Nrem-=Nelem2a;if(Nrem==0)return;offset+=Nelem2a;// stage 2b: slightly less optimized for section when we don't have full
// unrolling
intNpack2b=Nrem/packFactor;intNelem2b=Npack2b*packFactor;ReduceCopy128bMulti<FUNC,T,1,MINSRCS,MAXSRCS,MINDSTS,MAXDSTS>(w,nw,t,nsrcs,srcs,ndsts,dsts,offset,Npack2b);Nrem-=Nelem2b;if(Nrem==0)return;offset+=Nelem2b;// stage 2c: tail
ReduceCopyMulti<FUNC,T,MINSRCS,MAXSRCS,MINDSTS,MAXDSTS>(tid,nthreads,nsrcs,srcs,ndsts,dsts,offset,Nrem);}
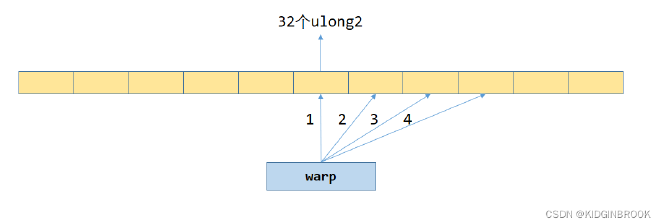
Then let’s look at how ReduceCopy128bMulti uses vectorized instructions for copying. The load/store here uses inline PTX, though it seems unnecessary. Fetch128 loads a ulong2 from position p into register variable v. There’s a variable UNROLL here - one warp processes UNROLL * WARP_SIZE consecutive ulong2s at once, similar to loop unrolling. When UNROLL is 4, the memory access pattern is shown in the following figure. For example, thread 0 will read the first ulong2 from 4 yellow boxes into register variable vals, then write to dst.
Figure 3
Specifically, when UNROLL is 1, the access pattern is similar to ReduceCopyMulti - 128 threads process 128 consecutive ulong2s, then loop to process the next 128 ulong2s.
inline__device__voidFetch128(Pack128&v,constPack128*p){asmvolatile("ld.volatile.global.v2.u64 {%0,%1}, [%2];":"=l"(v.x),"=l"(v.y):"l"(p):"memory");}inline__device__voidStore128(Pack128*p,Pack128&v){asmvolatile("st.volatile.global.v2.u64 [%0], {%1,%2};"::"l"(p),"l"(v.x),"l"(v.y):"memory");}template<classFUNC,typenameT>structMULTI128{__device__voidoperator()(Pack128&x,Pack128&y){x.x=MULTI<FUNC,T>()(x.x,y.x);x.y=MULTI<FUNC,T>()(x.y,y.y);}};template<classFUNC,typenameT,intUNROLL,intMINSRCS,intMAXSRCS,intMINDSTS,intMAXDSTS>__device____forceinline__voidReduceCopy128bMulti(constintw,constintnw,constintt,intnsrcs,constT*s[MAXSRCS],intndsts,T*d[MAXDSTS],constintelemOffset,constintNpack){constintinc=nw*UNROLL*WARP_SIZE;intoffset=w*UNROLL*WARP_SIZE+t;constPack128*srcs[MAXSRCS];for(inti=0;i<MAXSRCS;i++)srcs[i]=((constPack128*)(s[i]+elemOffset))+offset;Pack128*dsts[MAXDSTS];for(inti=0;i<MAXDSTS;i++)dsts[i]=((Pack128*)(d[i]+elemOffset))+offset;while(offset<Npack){Pack128vals[UNROLL];// Load and reduce
for(intu=0;u<UNROLL;++u)Fetch128(vals[u],srcs[0]+u*WARP_SIZE);for(inti=1;i<MINSRCS;i++){Pack128vals2[UNROLL];for(intu=0;u<UNROLL;++u)Fetch128(vals2[u],srcs[i]+u*WARP_SIZE);for(intu=0;u<UNROLL;++u)MULTI128<FUNC,T>()(vals[u],vals2[u]);}#pragma unroll 1
for(inti=MINSRCS;i<MAXSRCS&&i<nsrcs;i++){Pack128vals2[UNROLL];for(intu=0;u<UNROLL;++u)Fetch128(vals2[u],srcs[i]+u*WARP_SIZE);for(intu=0;u<UNROLL;++u)MULTI128<FUNC,T>()(vals[u],vals2[u]);}// Store
for(inti=0;i<MINDSTS;i++){for(intu=0;u<UNROLL;++u)Store128(dsts[i]+u*WARP_SIZE,vals[u]);}#pragma unroll 1
for(inti=MINDSTS;i<MAXDSTS&&i<ndsts;i++){for(intu=0;u<UNROLL;++u)Store128(dsts[i]+u*WARP_SIZE,vals[u]);}for(inti=0;i<MAXSRCS;i++)srcs[i]+=inc;for(inti=0;i<MAXDSTS;i++)dsts[i]+=inc;offset+=inc;}}
This completes the send/recv within the same card. Moving on to ncclSendRecvKernel, we can see that of the 320 threads mentioned earlier, 160 are used for send and 160 for recv. Both send and recv threads instantiate a ncclPrimitives, using directSend to send data and directRecv to receive data.
template<intUNROLL,classFUNC,typenameT>__device__voidncclSendRecvKernel(structCollectiveArgs*args){constinttid=threadIdx.x;constintnthreads=args->p2p.nThreads-2*WARP_SIZE;// Compute pointers
constT*sendbuff=(constT*)args->sendbuff;T*recvbuff=(T*)args->recvbuff;...structncclDevComm*comm=args->comm;structncclChannel*channel=comm->channels+blockIdx.x;constintstepSize=comm->buffSizes[NCCL_PROTO_SIMPLE]/(sizeof(T)*NCCL_STEPS)/SENDRECV_SLICEFACTOR;intnthreadsSplit=nthreads/2;// We set NRECV or NSEND to 2 to use different barriers in primitives for the send threads and
// receive threads, but then we define all peers to -1 since sender threads don't receive and
// receive threads don't send.
intpeerNone[2]={-1,-1};if(tid<nthreadsSplit+WARP_SIZE){constssize_tsendSize=args->p2p.sendCount;if(sendSize<0)return;intpeer=(comm->rank+(int)args->p2p.delta)%comm->nRanks;ncclPrimitives<UNROLL,1,1,T,2,1,1,FUNC>prims(tid,nthreadsSplit,peerNone,&peer,recvbuff,stepSize*4,channel,comm);if(sendSize==0){prims.send(sendbuff,0);}elsefor(ssize_toffset=0;offset<sendSize;offset+=stepSize){intrealChunkSize=min(stepSize,sendSize-offset);ALIGN_SIZE(realChunkSize,nthreads*sizeof(uint64_t)/sizeof(T));intnelem=min(realChunkSize,sendSize-offset);prims.directSend(sendbuff+offset,offset,nelem);}}else{constssize_trecvSize=args->p2p.recvCount;if(recvSize<0)return;intpeer=(comm->rank-(int)args->p2p.delta+comm->nRanks)%comm->nRanks;ncclPrimitives<UNROLL,1,1,T,1,2,1,FUNC>prims(tid-nthreadsSplit-WARP_SIZE,nthreads-nthreadsSplit,&peer,peerNone,recvbuff,stepSize*4,channel,comm);if(recvSize==0){prims.recv(recvbuff,0);}elsefor(ssize_toffset=0;offset<recvSize;offset+=stepSize){intrealChunkSize=min(stepSize,recvSize-offset);ALIGN_SIZE(realChunkSize,nthreads*sizeof(uint64_t)/sizeof(T));intnelem=min(realChunkSize,recvSize-offset);prims.directRecv(recvbuff+offset,offset,nelem);}}}
For better understanding, here are the template types:
First look at ncclPrimitives’ constructor. Here nthreads is 160 - 32 = 128, with 32 threads for synchronization. Since send’s recvPeer is -1, send won’t loadRecvConn, and recv won’t loadSendConn.
cpp8 lines hidden
1
2
3
4
5
6
7
8
9
10
11
__device____forceinline__ncclPrimitives(constinttid,constintnthreads,int*recvPeers,int*sendPeers,T*directBuff,intstepSize,structncclChannel*channel,structncclDevComm*comm):comm(comm),tid(tid),nthreads(nthreads),wid(tid%WARP_SIZE),stepSize(stepSize){// Make sure step is updated before we read it.
barrier();for(inti=0;i<NRECV&&recvPeers[i]>=0;i++)loadRecvConn(&channel->devPeers[recvPeers[i]].recv.conn,i,directBuff);for(inti=0;i<NSEND&&sendPeers[i]>=0;i++)loadSendConn(&channel->devPeers[sendPeers[i]].send.conn,i);loadRecvSync();loadSendSync();}
Then begin loading recv’s ncclConnInfo, saving recvBuff and step information. Since p2pread is supported in p2p setup process, conn->direct hasn’t set NCCL_DIRECT_GPU, so it won’t enter the first if. The first thread of each warp saves ncclConnInfo, initializing recvConnTail and recvConnHead to recvStep.
cpp10 lines hidden
1
2
3
4
5
6
7
8
9
10
11
12
13
__device____forceinline__voidloadRecvConn(structncclConnInfo*conn,inti,T*directBuff){recvBuff[i]=(constT*)conn->buffs[NCCL_PROTO_SIMPLE];recvStep[i]=conn->step;recvStep[i]=ROUNDUP(recvStep[i],SLICESPERCHUNK*SLICESTEPS);recvDirectBuff[i]=NULL;if(DIRECT&&(conn->direct&NCCL_DIRECT_GPU)){recvDirectBuff[i]=directBuff;if(tid==0)*conn->ptrExchange=directBuff;}if(wid==i)recvConn=conn;if(wid==i)recvConnTail=recvConnHead=recvStep[i];// Make sure we set this after rounding up
nrecv++;}
Then load send’s conn, save step and sendBuff. The first thread of each warp saves conn and initializes sendConnTail and sendConnHead to step.
cpp12 lines hidden
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
__device____forceinline__voidloadSendConn(structncclConnInfo*conn,inti){sendBuff[i]=(T*)conn->buffs[NCCL_PROTO_SIMPLE];sendStep[i]=conn->step;sendStep[i]=ROUNDUP(sendStep[i],SLICESPERCHUNK*SLICESTEPS);sendDirectBuff[i]=NULL;if(DIRECT&&(conn->direct&NCCL_DIRECT_GPU)){void*volatile*ptr=conn->ptrExchange;while((sendDirectBuff[i]=(T*)(*ptr))==NULL);barrier();if(tid==0)*ptr=NULL;}if(wid==i)sendConn=conn;if(wid==i)sendConnTail=sendConnHead=sendStep[i];// Make sure we set this after rounding up
nsend++;}
The first thread of the second warp saves tail and caches tail’s value;
The first thread of sync threads saves head
cpp8 lines hidden
1
2
3
4
5
6
7
8
9
10
11
__device____forceinline__voidloadRecvSync(){if(tid>=WARP_SIZE&&tid<2*WARP_SIZE&&wid<nrecv){recvConnTailPtr=recvConn->tail;recvConnTailCache=*recvConnTailPtr;}if(tid>=nthreads&&wid<nrecv){recvConnHeadPtr=recvConn->head;// Return credits in case we rounded up.
*recvConnHeadPtr=recvConnHead;}}
The first thread saves head and caches head’s value. fifo is used by proxy and not needed for now;
The first thread in sync threads saves tail.
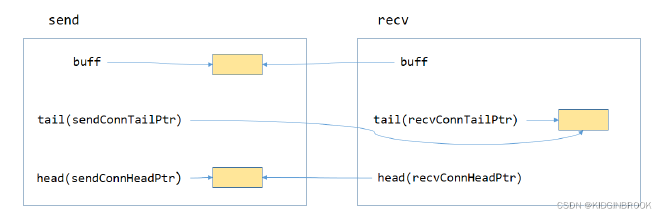
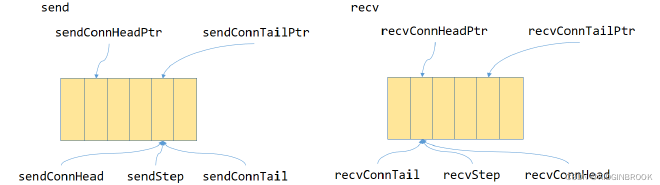
Now let’s look at what these variables do. In p2p transport setup stage (discussed in section 8), each rank created variables to coordinate send/receive process, as shown below. Since p2p read is supported, buff is at the sender; tail is at the receiver and shared by sender and receiver, updated by sender; head is at sender and shared by sender and receiver, updated by receiver. In ncclPrimitives’ receiver, tail is called recvConnTailPtr and head is called recvConnHeadPtr; while in sender, tail is called sendConnTailPtr and head is called sendConnHeadPtr.
Figure 4
Then let’s see how these variables coordinate the send/receive process
Figure 5
The yellow boxes in the middle are the buff shown in Figure 4. The entire buff is divided into NCCL_STEP blocks, Figure 5 only shows six blocks.
sendConnHead, sendConnTailPtr, sendStep are updated by sender, incrementing by one each send. These values are actually equal (so these variables seem somewhat redundant).
recvConnTail, recvConnHeadPtr, recvStep are updated by receiver, incrementing by one each receive. These values are actually equal.
Therefore, for receiver, as long as recvConnTail is less than recvConnTailPtr, it indicates data is available for receiving, and recvConnTail is incremented by one to indicate another block of data has been received.
For sender, as long as sendConnHead is greater than sendConnenHeadPtr plus NCCL_STEP, it indicates space is available for sending, and sendConnHead is incremented by one to indicate another send has been executed.
Then look at the directSend process. The srcs array has only one element, srcPtr is args->sendbuff (user-provided), so srcs[0] is sendbuff; dsts array also has only one element.
Before looking at actual data sending, let’s look at several sync functions. barrier() synchronizes all send or receive threads, subBarrier() synchronizes data transfer threads (excluding sync threads) within send/receive threads, essentially synchronizing different thread groups through different barriers.
Continuing, for send operations, if not sync thread, need to execute waitSend operation above until sending is possible. Since only the first thread executes waitSend, other threads need to wait for the first thread through subBarrier, otherwise data overwrite might occur if buff is full but sending continues. Then use ReduceOrCopyMulti to copy data from src to dst, which we’ve covered earlier. The following barrier ensures queue pointer information is updated only after data sending completes, preventing situations where queue pointers are updated but data copying hasn’t finished. Then update step through incSend. For sync threads, execute __threadfence_system before updating tail pointer through postSend. This fence ensures other threads see correct data in buff when they see tail pointer updates. System-level fence is needed for inter-machine communication scenarios involving CPU threads, requiring system-level memory barriers to ensure network communication correctness. Since __threadfence_system is time-consuming, a separate warp is introduced for synchronization to improve performance. Since postSend and memory barrier execution might be done by different threads, __syncwarp is needed to synchronize the current warp.
template<intDIRECTRECV,intDIRECTSEND,intRECV,intSEND,intSRC,intDST>inline__device__voidGenericOp(constT*srcPtr,T*dstPtr,intnelem,ssize_tdirectOffset){...boolsyncThread=tid>=nthreads;#pragma unroll
for(intslice=0;slice<SLICESPERCHUNK;++slice){intrealSize=max(0,min(dataSize,nelem-offset));if(!syncThread){if(SEND)waitSend(realSize*sizeof(T));if(RECV)waitRecv();if(realSize>0){subBarrier();if(DIRECTRECV&&recvDirectBuff[0]){// We can only have one direct receive. Since srcs[0] == dstPtr+offset, skip one copy
if(SEND){ReduceOrCopyMulti<UNROLL,FUNC,T,1,1,1,NSEND>(tid,nthreads,1,srcs,nsend,dsts+1,realSize);}}else{ReduceOrCopyMulti<UNROLL,FUNC,T,RECV+SRC,RECV*NRECV+SRC,SEND+DST,SEND*NSEND+DST>(tid,nthreads,RECV*nrecv+SRC,srcs,SEND*nsend+DST,dsts,realSize);}}}barrier();FOR_SEND(incSend);FOR_RECV(incRecv);if(syncThread){if(SEND){if(realSize>0&&wid==0)__threadfence_system();__syncwarp();postSend();}if(RECV)postRecv();}srcs[0]+=SRC?realSize:directRecvInc<DIRECTRECV>(0,realSize,sliceSize);for(inti=1-SRC;i<RECV*NRECV;i++)srcs[SRC+i]+=sliceSize;dsts[0]+=DST?realSize:directSendInc<DIRECTSEND>(0,realSize,sliceSize);for(inti=1-DST;i<SEND*NSEND;i++)dsts[DST+i]+=directSendInc<DIRECTSEND>(i,realSize,sliceSize);offset+=realSize;}}
This basically completes the ncclSend/ncclRecv process within a single machine, mainly in two steps: first record user operations through peerlist and generate kernel parameters based on records, then launch kernel to execute copying. For different cards, send copies data from user-specified sendbuff to nccl p2p transport’s buff, recv copies data from buff to user-specified recvbuff. Buff here acts as a fifo, with nccl coordinating send and receive processes through head and tail pointers. For same card, kernel directly copies data from sendbuff to recvbuff.
NCCL Source Code Study - This article is part of a series.