Background#
In our previous section, we introduced how IB SHARP works. Furthermore, NVIDIA introduced the third generation NVSwitch in their Hopper architecture machines. Similar to IB SHARP between machines, NVLink SHARP (abbreviated as nvls) can be executed within machines through NVSwitch. In this section, we’ll explain how NVLink SHARP works.
For simplicity, we’ll use examples with nranks=2, but it’s worth noting that nvls isn’t actually used when nranks=2.
Graph Search#
ncclResult_t ncclNvlsInit(struct ncclComm* comm) {
...
if (comm->nvlsSupport == 1) comm->nvlsChannels = std::max(comm->config.minCTAs, std::min(comm->config.maxCTAs, (int)ncclParamNvlsChannels()));
return ncclSuccess;
}
During initialization, it mainly determines if nvls is supported. If supported, nvlsSupport is set to 1, and comm->nvlsChannels is set. Note that this represents the number of blocks that the kernel actually launches, not the number of channels found during the search.
Then the search process begins. nvls channels are different from channels found by other algorithms. Let’s look at the specifics:
nvlsGraph.pattern = NCCL_TOPO_PATTERN_NVLS;
nvlsGraph.minChannels = 1;
nvlsGraph.maxChannels = MAXCHANNELS;
if (comm->nvlsSupport) {
NCCLCHECKGOTO(ncclTopoCompute(comm->topo, &nvlsGraph), ret, fail);
NCCLCHECKGOTO(ncclTopoPrintGraph(comm->topo, &nvlsGraph), ret, fail);
}
The pattern is set to NCCL_TOPO_PATTERN_NVLS, and then the search begins. Through this pattern, backToNet and backToFirstRank are determined to be -1.
ncclResult_t ncclTopoSearchRec(struct ncclTopoSystem* system, struct ncclTopoGraph* graph, struct ncclTopoGraph* saveGraph, int* time) {
int backToNet, backToFirstRank;
NCCLCHECK(ncclTopoSearchParams(system, graph->pattern, &backToNet, &backToFirstRank));
if (system->nodes[NET].count) {
} else {
if (graph->pattern == NCCL_TOPO_PATTERN_NVLS) {
NCCLCHECK(ncclTopoSearchTryGpu(system, graph, saveGraph, 0, backToNet, backToFirstRank, 0, time, -1, -1, graph->nChannels));
return ncclSuccess;
}
...
}
return ncclSuccess;
}
At this point, graph->nChannels is 0.
ncclResult_t ncclTopoSearchTryGpu(struct ncclTopoSystem* system, struct ncclTopoGraph* graph, struct ncclTopoGraph* saveGraph, int step, int backToNet, int backToFirstRank, int forcedOrder, int *time, int type, int index, int g) {
const uint64_t flag = 1ULL<<(graph->nChannels);
struct ncclTopoNode* gpu;
NCCLCHECK(ncclTopoFollowPath(system, graph, type, index, GPU, g, 1, &gpu));
if (gpu) {
gpu->used ^= flag;
NCCLCHECK(ncclTopoSearchRecGpu(system, graph, saveGraph, gpu, step, backToNet, backToFirstRank, forcedOrder, time));
gpu->used ^= flag;
NCCLCHECK(ncclTopoFollowPath(system, graph, type, index, GPU, g, -1, &gpu));
}
return ncclSuccess;
}
Since type is -1, ncclTopoFollowPath directly returns gpu0, and the search begins from gpu0.
ncclResult_t ncclTopoSearchRecGpu(struct ncclTopoSystem* system, struct ncclTopoGraph* graph, struct ncclTopoGraph* saveGraph, struct ncclTopoNode* gpu, int step, int backToNet, int backToFirstRank, int forcedOrder, int *time) {
if ((*time) <= 0) return ncclSuccess;
(*time)--;
int ngpus = system->nodes[GPU].count;
if (step == ngpus) {
}
graph->intra[graph->nChannels*ngpus+step] = gpu->gpu.rank;
int g = gpu - system->nodes[GPU].nodes;
if (step == backToNet) {
} else if (graph->pattern == NCCL_TOPO_PATTERN_NVLS) {
NCCLCHECK(ncclTopoSearchTryNvls(system, graph, saveGraph, g, ngpus, time));
} else if (step < system->nodes[GPU].count-1) {
} else if (step == backToFirstRank) {
} else {
}
return ncclSuccess;
}
GPU 0 is filled into graph->intra, and since the pattern is NCCL_TOPO_PATTERN_NVLS, ncclTopoSearchTryNvls is executed directly.
ncclResult_t ncclTopoSearchTryNvls(struct ncclTopoSystem* system, struct ncclTopoGraph* graph, struct ncclTopoGraph* saveGraph, int g, int ngpus, int *time) {
struct ncclTopoNode* nvs;
struct ncclTopoNode* gpu;
int d0=0; // See if there is enough bandwidth for NVS->GPU traffic
do {
NCCLCHECK(ncclTopoFollowPath(system, graph, NVS, 0, GPU, d0, d0 == g ? 2 : 1, &gpu));
d0++;
} while (gpu && d0 < system->nodes[GPU].count);
if (gpu == NULL) {
d0--;
} else {
int d1=0; // See if there is enough bandwidth for GPU->NVS traffic
do {
NCCLCHECK(ncclTopoFollowPath(system, graph, GPU, d1, NVS, 0, d1 == g ? 2 : 1, &nvs));
d1++;
} while (nvs && d1 < system->nodes[GPU].count);
if (nvs == NULL) {
d1--;
} else { // Both directions worked. Move on to the next path.
NCCLCHECK(ncclTopoSearchRecGpu(system, graph, saveGraph, NULL, ngpus, -1, -1, 0, time));
}
while (d1) {
d1--;
NCCLCHECK(ncclTopoFollowPath(system, graph, GPU, d1, NVS, 0, d1 == g ? -2 : -1, &nvs));
}
}
while (d0) {
d0--;
NCCLCHECK(ncclTopoFollowPath(system, graph, NVS, 0, GPU, d0, d0 == g ? -2 : -1, &gpu));
}
return ncclSuccess;
}
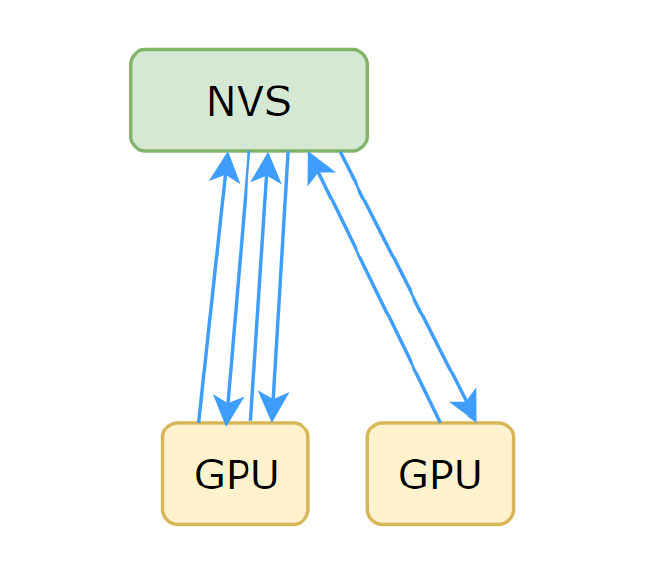
This determines if the bandwidth meets requirements. Let’s first look at the actual GPU and NVSwitch topology in a machine as shown in Figure 1
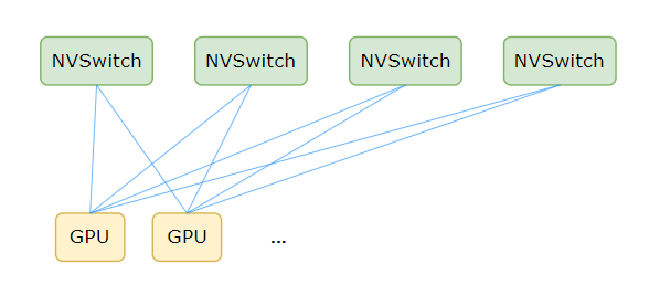
Figure 1#
However, since NVSwitch is transparent to users, the topology built in NCCL is actually as shown below
Figure 2#
Assuming the bandwidth in the current search condition is bw, and g is GPU0, the logic for searching one channel is to determine if the bidirectional bandwidth from all GPU nodes to NVSwitch is greater than bw. If greater, then subtract bw. Specifically for GPU0, it needs to check if the existing link bandwidth is greater than 2 * bw, which we’ll explain later.
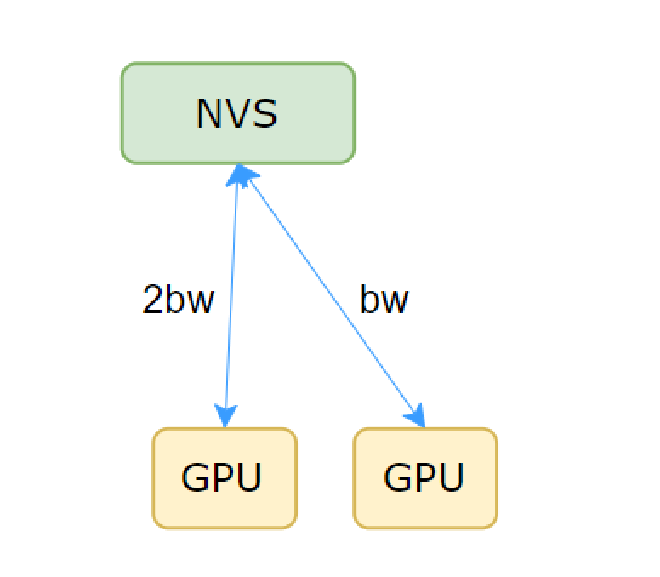
Figure 3#
Then ncclTopoSearchRecGpu continues executing. Note that step is specified as ngpus, so this completes the search for one channel. nChannels becomes 1, so the next time ncclTopoSearchTryGpu executes, it will start from GPU1, repeating this process until ngpus channels are found. Taking four GPUs as an example, the searched channels are shown as follows:
0
1
2
3
While channels in other algorithms represent the transmission order within nodes, nvls channels are different. For example, the 0 in the first channel, which NCCL calls nvlsHead, indicates which node is responsible for operations like reduce for a certain memory segment, as we’ll see later.
Channel Connection#
static ncclResult_t connectNvls(struct ncclComm* comm, int* nvlsHeads, struct ncclTopoGraph* nvlsGraph) {
int nHeads = nvlsGraph->nChannels;
int headRank = -1;
for (int h=0; h<nHeads; h++) {
if (nvlsGraph->intra[h*comm->localRanks] == comm->rank) headRank = h;
}
for (int c=0; c<comm->nvlsChannels; c++) {
struct ncclChannel* channel = comm->channels+c;
channel->nvls.nHeads = nHeads;
for (int h=0; h<nHeads; h++) channel->nvls.up[h] = comm->nRanks+1+h;
for (int h=nHeads; h<NCCL_MAX_NVLS_ARITY; h++) channel->nvls.up[h] = -1;
channel->nvls.down = comm->nRanks+1+headRank;
channel->nvls.out = -1; // NVLS+SHARP not yet implemented.
channel->nvls.headRank = headRank;
channel->nvls.treeUp = channel->nvls.treeDown[0] = channel->nvls.treeDown[1] = channel->nvls.treeDown[2] = -1;
channel->nvls.node = comm->node;
channel->nvls.nNodes = comm->nNodes;
}
if (comm->nNodes == 1) return ncclSuccess;
}
Calculate headRank, which indicates which channel’s node is this rank, then begin setting up all nvls channels. The up and down here are used to index peers. Since nvls connections start from nRanks+1, nRanks+1 needs to be added here. Up represents all heads, down is headRank, which is actually itself.
Memory Registration#
The overall memory registration process is shown in Figure 4. First, a multicast object is created through cuMulticastCreate, where the handle in the figure points to this multicast object. Then each GPU associates the current device with this multicast object through cuMulticastAddDevice, then allocates memory, and finally associates the allocated memory with the handle through cuMulticastBindAddr or cuMulticastBindMem.
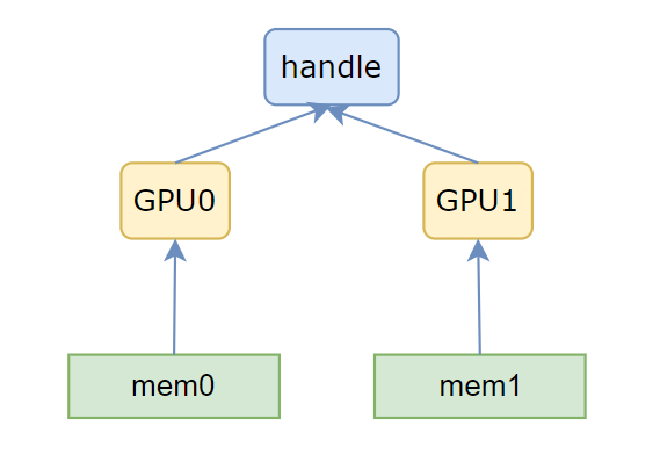
Figure 4#
ncclResult_t ncclNvlsSetup(struct ncclComm* comm, struct ncclComm* parent) {
...
size_t buffSize = comm->buffSizes[NCCL_PROTO_SIMPLE];
size_t memSize = NVLS_MEM_ALIGN_SIZE;
size_t nvlsPerRankSize = nChannels * 2 * (buffSize + memSize);
size_t nvlsTotalSize = nvlsPerRankSize * nHeads;
char* shareableHandle = resources->shareableHandle;
NCCLCHECKGOTO(nvlsGetProperties(comm, resources, dev, comm->localRanks, nvlsTotalSize), res, cleanup);
...
}
buffSize is the buff size for the SIMPLE protocol, memSize is used to save head and tail, then calculate how much memory needs to be allocated in total. nHeads is the number of channels found, which is nRanks. We’ll see later why the memory size is configured this way. Then save the total memory size and localRanks information to resources.
ncclResult_t ncclNvlsSetup(struct ncclComm* comm, struct ncclComm* parent) {
...
if (comm->localRank == 0) {
NCCLCHECKGOTO(nvlsGroupCreate(comm, &resources->properties, comm->localRank, comm->localRanks, &resources->mcHandle, shareableHandle), res, cleanup);
NCCLCHECKGOTO(bootstrapIntraNodeBroadcast(comm->bootstrap, comm->localRankToRank, comm->localRank, comm->localRanks, 0, shareableHandle, NVLS_HANDLE_SIZE), res, cleanup);
} else {
NCCLCHECKGOTO(bootstrapIntraNodeBroadcast(comm->bootstrap, comm->localRankToRank, comm->localRank, comm->localRanks, 0, shareableHandle, NVLS_HANDLE_SIZE), res, cleanup);
NCCLCHECKGOTO(nvlsGroupConnect(comm, shareableHandle, comm->localRankToRank[0], &resources->mcHandle), res, cleanup);
}
...
}
rank0 executes nvlsGroupCreate, creates a multicast object through cuMulticastCreate, and saves it in resources->mcHandle. Since it needs to be shared across processes, it needs to be converted to a shareable handle, which is done through direct memcpy here.
ncclResult_t nvlsGroupCreate(struct ncclComm *comm, CUmulticastObjectProp *prop, int rank, unsigned int nranks, CUmemGenericAllocationHandle *mcHandle, char *shareableHandle) {
size_t size = prop->size;
CUCHECK(cuMulticastCreate(mcHandle, prop));
memcpy(shareableHandle, mcHandle, sizeof(CUmemGenericAllocationHandle));
return ncclSuccess;
}
Then all ranks execute bootstrapIntraNodeBroadcast, rank0 broadcasts the shared handle of the multicast object to all ranks’ shareableHandle. After other ranks receive the shareableHandle, they convert it to mcHandle through nvlsGroupConnect. Then through cuMulticastAddDevice, the current card is bound to mcHandle, so all ranks now have the multicast object corresponding to mcHandle.
ncclResult_t nvlsGroupBindMem(struct ncclComm *comm, struct ncclNvlsSharedRes* resources) {
size_t size = resources->size;
size_t granularity;
CUdeviceptr ptr = 0;
CUmemAllocationProp prop;
memset(&prop, 0, sizeof(prop));
prop.type = CU_MEM_ALLOCATION_TYPE_PINNED;
prop.location.type = CU_MEM_LOCATION_TYPE_DEVICE;
prop.location.id = resources->dev;
prop.requestedHandleTypes = NVLS_CU_MEM_HANDLE_TYPE;
CUCHECK(cuMemGetAllocationGranularity(&granularity, &prop, CU_MEM_ALLOC_GRANULARITY_RECOMMENDED));
resources->ucGran = granularity;
// Map a VA for UC memory
CUCHECK(cuMemAddressReserve(&ptr, size, granularity, 0U, 0));
// Alloc local physical mem for this NVLS group
CUCHECK(cuMemCreate(&resources->ucHandle, size, &prop, 0));
CUCHECK(cuMemMap(ptr, size, 0, resources->ucHandle, 0));
CUCHECK(cuMemSetAccess(ptr, size, &resources->accessDesc, 1));
CUDACHECK(cudaMemset((void*)ptr, 0, size));
resources->ucBuff = (char*)ptr;
CUCHECK(cuMulticastBindMem(resources->mcHandle, 0/*mcOffset*/, resources->ucHandle, 0/*memOffset*/, size, 0/*flags*/));
return ncclSuccess;
}
Then begin allocating physical memory and mapping it to virtual address space. First, reserve a virtual address space to ptr, then allocate physical memory to ucHandle, then map the physical memory pointed to by ucHandle to ptr, and assign ptr to ucBuff, as shown in Figure 5.
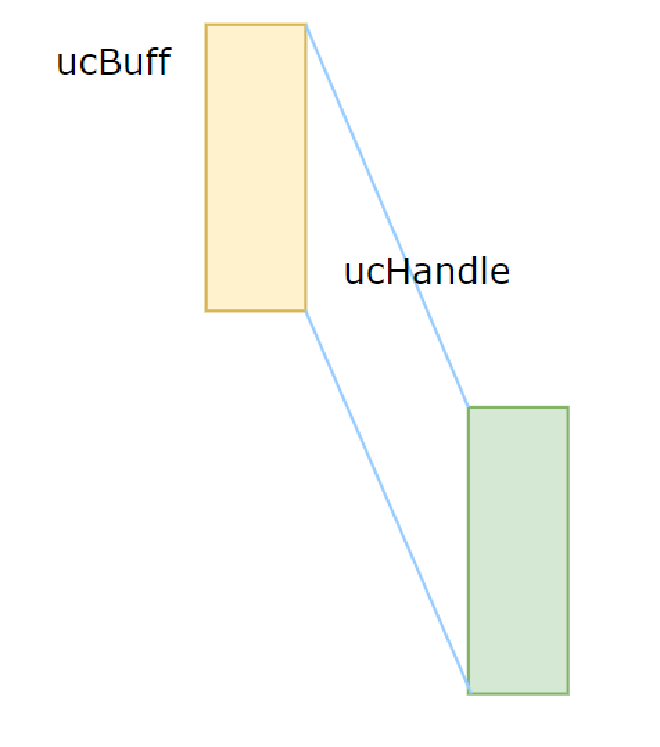
Figure 5#
Finally, bind the physical memory corresponding to ucHandle to mcHandle through cuMulticastBindMem.
Then begin executing nvlsGroupMapMem to map mcHandle to virtual address space.
ncclResult_t nvlsGroupMapMem(struct ncclComm *comm, struct ncclNvlsSharedRes* resources) {
size_t size = resources->size;
CUdeviceptr ptr = 0;
// Create a VA for the NVLS
CUCHECK(cuMemAddressReserve(&ptr, size, resources->granularity, 0U, 0));
// Map the VA locally
CUCHECK(cuMemMap(ptr, size, 0, resources->mcHandle, 0));
resources->mcBuff = (char*)ptr;
INFO(NCCL_NVLS, "NVLS Mapped MC buffer at %p size %zi", resources->mcBuff, size);
// Having completed the BindMem we can now call SetAccess
// NB: It will block until all ranks have bound to the Group
CUCHECK(cuMemSetAccess((CUdeviceptr)resources->mcBuff, size, &resources->accessDesc, 1));
return ncclSuccess;
}
Similarly, reserve virtual address space to ptr, then map mcHandle to ptr, save in mcBuff. At this point, it’s as shown in Figure 6
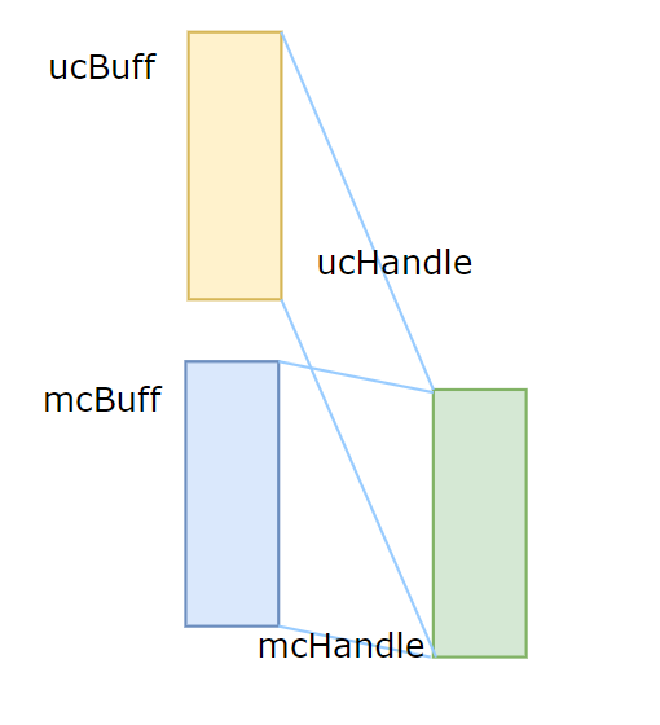
Figure 6#
At this point, this physical memory is mapped to both ucBuff and mcBuff. ucBuff is Unicast buffer, access to it only affects the current device’s memory. mcBuff is Multicast buffer, access to it will be broadcast by NVSwitch to all devices added to mcHandle.
Then begin recording the memory to each peer’s connection buffer.
ncclResult_t ncclNvlsSetup(struct ncclComm* comm, struct ncclComm* parent) {
...
for (int h = 0; h < nHeads; h++) {
int nvlsPeer = comm->nRanks + 1 + h;
for (int c = 0; c < nChannels; c++) {
struct ncclChannel* channel = comm->channels + c;
char* mem = NULL;
struct ncclChannelPeer* peer = channel->peers[nvlsPeer];
// Reduce UC -> MC
mem = resources->ucBuff + (h * 2 * nChannels + c) * (buffSize + memSize);
peer->send[1].transportComm = &nvlsTransport.send;
peer->send[1].conn.buffs[NCCL_PROTO_SIMPLE] = mem;
peer->send[1].conn.head = (uint64_t*)(mem + buffSize);
peer->send[1].conn.tail = (uint64_t*)(mem + buffSize + memSize / 2);
mem = resources->mcBuff + (h * 2 * nChannels + c) * (buffSize + memSize);
peer->recv[0].transportComm = &nvlsTransport.recv;
peer->recv[0].conn.buffs[NCCL_PROTO_SIMPLE] = mem;
peer->recv[0].conn.head = (uint64_t*)(mem + buffSize);
peer->recv[0].conn.tail = (uint64_t*)(mem + buffSize + memSize / 2);
peer->recv[0].conn.flags |= NCCL_NVLS_MIN_POLL;
// Broadcast MC -> UC
mem = resources->ucBuff + ((h * 2 + 1) * nChannels + c) * (buffSize + memSize);
peer->recv[1].transportComm = &nvlsTransport.recv;
peer->recv[1].conn.buffs[NCCL_PROTO_SIMPLE] = mem;
peer->recv[1].conn.head = (uint64_t*)(mem + buffSize);
peer->recv[1].conn.tail = (uint64_t*)(mem + buffSize + memSize / 2);
mem = resources->mcBuff + ((h * 2 + 1) * nChannels + c) * (buffSize + memSize);
peer->send[0].transportComm = &nvlsTransport.send;
peer->send[0].conn.buffs[NCCL_PROTO_SIMPLE] = mem;
peer->send[0].conn.head = (uint64_t*)(mem + buffSize);
peer->send[0].conn.tail = (uint64_t*)(mem + buffSize + memSize / 2);
peer->send[0].conn.flags |= NCCL_NVLS_MIN_POLL;
CUDACHECKGOTO(cudaMemcpyAsync(&comm->channels[c].devPeersHostPtr[nvlsPeer]->send[0], &peer->send[0].conn, sizeof(struct ncclConnInfo), cudaMemcpyHostToDevice, comm->sharedRes->hostStream.cudaStream), res, cleanup);
CUDACHECKGOTO(cudaMemcpyAsync(&comm->channels[c].devPeersHostPtr[nvlsPeer]->recv[0], &peer->recv[0].conn, sizeof(struct ncclConnInfo), cudaMemcpyHostToDevice, comm->sharedRes->hostStream.cudaStream), res, cleanup);
CUDACHECKGOTO(cudaMemcpyAsync(&comm->channels[c].devPeersHostPtr[nvlsPeer]->send[1], &peer->send[1].conn, sizeof(struct ncclConnInfo), cudaMemcpyHostToDevice, comm->sharedRes->hostStream.cudaStream), res, cleanup);
CUDACHECKGOTO(cudaMemcpyAsync(&comm->channels[c].devPeersHostPtr[nvlsPeer]->recv[1], &peer->recv[1].conn, sizeof(struct ncclConnInfo), cudaMemcpyHostToDevice, comm->sharedRes->hostStream.cudaStream), res, cleanup);
}
}
...
}
After this process completes, it will be as shown in Figure 7.
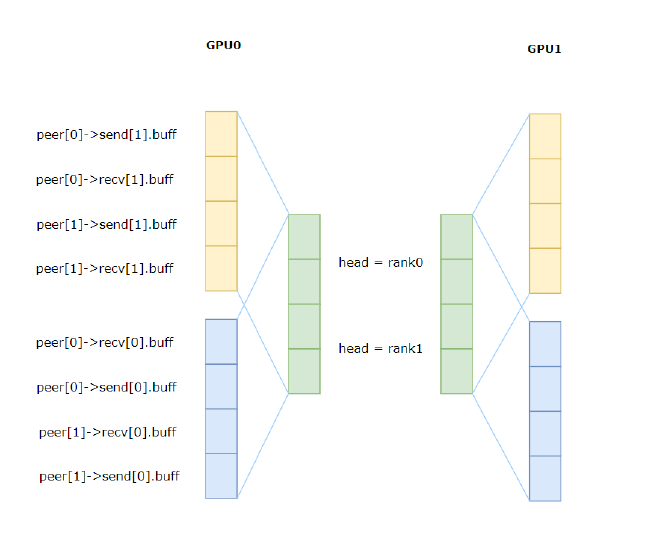
Figure 7#
The yellow parts in the figure are ucBuff, and the blue parts are mcBuff. mcBuff is multimem in PTX, and multimem operations are as follows:
The multimem.* operations operate on multimem addresses and accesses all of the multiple memory locations which the multimem address points to.
Taking ld_reduce as an example:
multimem.ld_reduce{.ldsem}{.scope}{.ss}.op.type d, [a];
If GPU0 executes multimem.ld_reduce on peer[0]->send[1].buff, this will load data from the corresponding positions of GPU0 and GPU1, perform reduce, and save the result in d.
Using ReduceScatter as an Example to Explain the Kernel Process#
Version 2.19 has undergone significant changes, so before looking at the nvls kernel, let’s first introduce how the new kernel execution process works.
Kernel Forwarding#
Let’s first look at how the kernel is launched and how it executes step by step to reach the corresponding device functions for protos, algos, etc.
Due to multiple APIs, reduce types, data types, algorithms, and protocols, where kernels are the Cartesian product of these variables, NCCL uses generate.py to generate these kernel definitions, mainly generating two arrays: ncclDevKernelForFunc and ncclDevFuncTable, for global functions and device functions respectively.
static ncclResult_t scheduleCollTasksToPlan(...) {
...
NCCLCHECK(computeColl(&info, &workFuncIndex, &workElem, &proxyOp));
...
if (!plan->kernelSpecialized) {
plan->kernelFn = ncclDevKernelForFunc[workFuncIndex];
plan->kernelSpecialized = ncclDevKernelForFuncIsSpecialized[workFuncIndex];
}
...
}
During the enqueue process, workFuncIndex is calculated through computeColl, then kernelFn is recorded as ncclDevKernelForFunc[workFuncIndex]. Taking ReduceScatter sum as an example, the workFuncIndex is 485, and looking up ncclDevKernelForFunc[485] gives us ncclDevKernel_ReduceScatter_Sum_f32_RING_LL. Note that while we’re actually using the SIMPLE protocol, this kernel is LL. Let’s see how it’s further forwarded.
DEFINE_ncclDevKernel(ReduceScatter_Sum_f32_RING_LL, ncclFuncReduceScatter, FuncSum, float, NCCL_ALGO_RING, NCCL_PROTO_LL, 483)
#define DEFINE_ncclDevKernel(suffix, coll, redop, ty, algo, proto, specializedFnId) \
__global__ void ncclDevKernel_##suffix(struct ncclDevComm* comm, uint64_t channelMask, struct ncclWork* workHead) { \
ncclKernelMain<specializedFnId, RunWork<coll, ty, redop<ty>, algo, proto>>(comm, channelMask, workHead); \
}
The function ncclDevKernel_ReduceScatter_Sum_f32_RING_LL is defined as above, with specializedFnId as 483, and directly executes ncclKernelMain.
Before looking at ncclKernelMain, let’s examine how existing parameter information is stored.
__shared__ ncclShmemData ncclShmem;
struct ncclShmemGroup {
ncclConnInfo *recvConns[NCCL_MAX_NVLS_ARITY];
ncclConnInfo *sendConns[NCCL_MAX_NVLS_ARITY];
void* srcs[NCCL_MAX_NVLS_ARITY+1];
void* dsts[NCCL_MAX_NVLS_ARITY+1];
union {
unpackGroupShmem unpack;
} devicePlugin;
};
struct ncclShmemData {
struct ncclShmemGroup groups[NCCL_MAX_GROUPS];
uint64_t redOpArgs[NCCL_MAX_NVLS_ARITY+1];
int channelId;
int aborted;
alignas(16) struct ncclDevComm comm;
alignas(16) struct ncclDevChannel channel;
alignas(16) struct ncclWork work;
alignas(16) union {
unpackShmem unpack;
} devicePlugin;
};
ncclShmem is located in shared memory and stores the parameter information needed by the kernel, such as channelId, comm, channel, etc. All threads in a block will use this information for sending and receiving data. In previous versions, all threads in a block had the same peer, while in the new version different threads may correspond to different peers. For example, in send/recv, a block can send/receive to/from 8 peers, and in nvls discussed in this section, different warps in a block use a pipelined approach to complete the overall process. Therefore, the data structure ncclShmemGroup groups was introduced, where a group represents threads executing the same logic, and the required conn, srcs, dsts information for the group is stored in groups.
template<int SpecializedFnId, typename SpecializedRunWork>
__device__ void ncclKernelMain(struct ncclDevComm* comm, uint64_t channelMask, struct ncclWork* workHead) {
int tid = threadIdx.x;
if (tid < WARP_SIZE) {
int x = tid;
if (channelMask & (1ull<<x)) {
int y = __popcll(channelMask & ((1ull<<x)-1));
if (blockIdx.x == y) ncclShmem.channelId = x;
}
...
}
__syncthreads(); // publish ncclShmem.channelId
int channelId = ncclShmem.channelId;
...
}
The correspondence between blocks and channels is selected, calculating which channel the current block should handle.
template<int SpecializedFnId, typename SpecializedRunWork>
__device__ void ncclKernelMain(struct ncclDevComm* comm, uint64_t channelMask, struct ncclWork* workHead) {
...
while (true) {
// Notify host that all fifo reads are complete.
...
if (0 <= SpecializedFnId && ncclShmem.work.header.funcIndex == (unsigned)SpecializedFnId) {
SpecializedRunWork().run(&ncclShmem.work);
} else {
ncclDevFuncTable[ncclShmem.work.header.funcIndex]();
}
int workIxNext = ncclShmem.work.header.workNext;
__syncthreads();
...
}
...
}
With funcIndex being 485 and SpecializedFnId being 483, it will look up the corresponding function in ncclDevFuncTable again, which is ncclDevFunc_ReduceScatter_Sum_f32_RING_SIMPLE, thus finding the function to execute.
DEFINE_ncclDevFunc(ReduceScatter_Sum_f32_RING_SIMPLE, ncclFuncReduceScatter, FuncSum, float, NCCL_ALGO_RING, NCCL_PROTO_SIMPLE)
#define DEFINE_ncclDevFunc(suffix, coll, redop, ty, algo, proto) \
__device__ void ncclDevFunc_##suffix() { \
RunWork<coll, ty, redop<ty>, algo, proto>().run(&ncclShmem.work); \
}
template<ncclFunc_t Fn, typename T, typename RedOp, int Algo, int Proto>
struct RunWork {
// This __forceinline__ is necessary. The compiler was inserting a function call
// here from the LL ncclKernel.
__device__ __forceinline__ void run(ncclWork *w) {
int wid = threadIdx.x / WARP_SIZE;
ncclWorkElem* we = w->header.type == ncclWorkTypeRegColl ? &w->regElems[0].elem : &w->elems[0];
int stride = w->header.type == ncclWorkTypeRegColl ? sizeof(ncclWorkElemReg) : sizeof(ncclWorkElem);
#pragma unroll 1
while ((char*)we + stride <= (char*)(w+1) && we->isUsed) {
if (wid < we->nWarps) {
RunWorkElement<Fn, T, RedOp, Algo, Proto>().run(we);
}
we = (ncclWorkElem*)((char*)we + stride);
}
}
};
Looking at the definition of this function, we can see that Fn is ncclFuncReduceScatter, T is float, RedOp is FuncSum<float>, algo is NCCL_ALGO_RING, and protocol is NCCL_PROTO_SIMPLE, then it begins executing runRing
template<typename T, typename RedOp, typename Proto>
__device__ __forceinline__ void runRing(ncclWorkElem *args) {
...
const ssize_t loopSize = nChannels*chunkSize;
const ssize_t size = args->count;
Primitives<T, RedOp, FanSymmetric<1>, 0, Proto, 0>
prims(tid, nthreads, &ring->prev, &ring->next, args->sendbuff, args->recvbuff, args->redOpArg);
for (ssize_t gridOffset = 0; gridOffset < size; gridOffset += loopSize) {
ssize_t realChunkSize;
...
realChunkSize = int(realChunkSize);
ssize_t chunkOffset = gridOffset + bid*int(realChunkSize);
/// begin ReduceScatter steps ///
ssize_t offset;
int nelem = min(realChunkSize, size-chunkOffset);
int rankDest;
// step 0: push data to next GPU
rankDest = ringRanks[nranks-1];
offset = chunkOffset + rankDest * size;
prims.send(offset, nelem);
First step, execute send for the block data corresponding to its own rank, which means sending data to the next rank’s buffer.
// k-2 steps: reduce and copy to next GPU
for (int j=2; j<nranks; ++j) {
rankDest = ringRanks[nranks-j];
offset = chunkOffset + rankDest * size;
prims.recvReduceSend(offset, nelem);
}
Then for the next nranks - 2 steps, execute recvReduceSend, which means reducing the data sent from the previous rank in its buffer with the corresponding position in its user input data, then sending it to the next rank.
// step k-1: reduce this buffer and data, which will produce the final result
rankDest = ringRanks[0];
offset = chunkOffset + rankDest * size;
prims.recvReduceCopy(offset, chunkOffset, nelem, /*postOp=*/true);
}
}
}
Finally, execute recvReduceCopy, which means reducing the data sent from the previous rank with the corresponding position in its user input and copying it to the user output.
Primitive Initialization#
Reviewing the construction of primitives in ReduceScatter, recvPeers is the previous rank in the ring, sendPeers is the next rank in the ring, inputBuf and outputBuf are the input/output buffers provided by the user executing the API, group is the default parameter 0. redOpArg is used for operations like mean, where it would be set to nranks and divided by nranks during reduceCopy. In this example of sum operation, redOpArg can be ignored.
Primitives<T, RedOp, FanSymmetric<1>, 0, Proto, 0>
prims(tid, nthreads, &ring->prev, &ring->next, args->sendbuff, args->recvbuff, args->redOpArg);
__device__ Primitives(
int tid, int nthreads, int const *recvPeers, int const *sendPeers,
void const *inputBuf, void *outputBuf, uint64_t redOpArg, uint8_t group=0,
uint8_t connIndexRecv = 0, uint8_t connIndexSend = 0, struct ncclWorkElem* e = nullptr, int stepSize_=0
):
tid(tid), nthreads(nthreads), tidInBlock(threadIdx.x), group(group),
stepSize(stepSize_ == 0 ? ncclShmem.comm.buffSizes[NCCL_PROTO_SIMPLE]/NCCL_STEPS/sizeof(T) : stepSize_) {
}
In the template parameters, Direct and P2p are 0, Fan is FanSymmetric<1>, which records how many recv and send operations there are, with MaxRecv and MaxArity both being 1.
template<int MaxArity>
struct FanSymmetric {
static constexpr int MaxRecv = MaxArity, MaxSend = MaxArity;
int n;
FanSymmetric() = default;
__device__ FanSymmetric(int nrecv, int nsend): n(nrecv) {
// assert(nrecv == nsend && nrecv <= MaxArity);
}
__device__ int nrecv() const { return n; }
__device__ int nsend() const { return n; }
};
Let’s continue looking at the initialization process
__device__ Primitives(...)
// For send operations, we need an extra warp to overlap the threadfence and the copy
this->nworkers = nthreads - (MaxSend > 0 && nthreads-WARP_SIZE >= 64 ? WARP_SIZE : 0);
int nrecv=0, nsend=0;
while (nrecv < MaxRecv && recvPeers[nrecv] != -1) nrecv++;
while (nsend < MaxSend && sendPeers[nsend] != -1) nsend++;
this->fan = Fan(nrecv, nsend);
constexpr int ThreadPerSync = 8;
static_assert(MaxSend <= ThreadPerSync && MaxRecv <= ThreadPerSync, "Not enough threads to cover all peers");
int g = tid / ThreadPerSync;
int ng = nthreads / ThreadPerSync;
index = tid % ThreadPerSync;
flags = 0;
if (g == 0) {
if (index < nrecv) flags |= RoleWaitRecv;
if (index == nrecv) flags |= RoleInput;
} else if (g == 1) {
if (index < nsend) flags |= RoleWaitSend;
if (index == nsend) flags |= RoleOutput;
} else if (g == ng - 2) {
if (index < nrecv) flags |= RolePostRecv;
} else if (g == ng - 1) {
if (index < nsend) flags |= RolePostSend;
}
...
}
nthreads is the total number of executing threads, in this example equal to the number of threads in the block. nworkers is the number of threads actually doing work. Since sending requires one warp to execute threadfence, the actual working threads are nthreads minus one warp, though when the total number of warps is small, an independent synchronization warp won’t be used. Record nsend and nrecv, both being 1 in this case.
Then begin setting each thread’s role, dividing nthreads into groups of 8. Assuming there are n-1 groups, and both recvPeer and sendPeer have two each, the role allocation for threads is shown in Figure 8, where WaitRecv indicates the thread is responsible for waiting until data is available to receive in the fifo. In this example, g[0]’s thr[0] waits for the 0th recvPeer, thr[1] for the 1st recvPeer, Input threads are responsible for writing to user buffer addresses, PostRecv is responsible for notifying recvPeer after receiving data, g[n-2]’s thr[0] notifies the 0th recvPeer, thr[1] notifies the 1st recvPeer, and similarly for send.
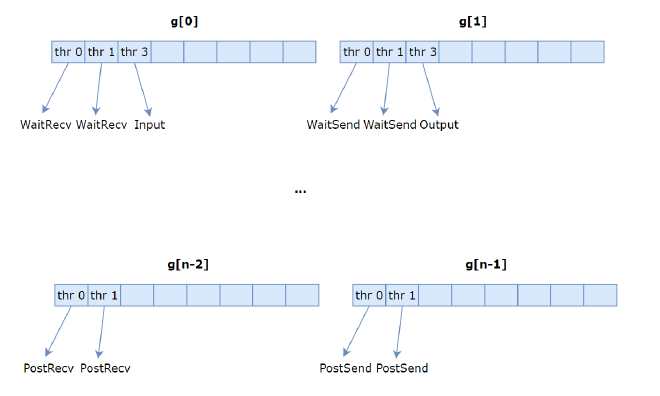
Figure 8#
__device__ __forceinline__ void loadRecvConn(ncclDevChannelPeer *peer, int connIndex, struct ncclWorkElem* e) {
if (flags & (RoleWaitRecv|RolePostRecv)) {
auto *conn = &peer->recv[connIndex];
step = conn->step;
step = roundUp(step, SlicePerChunk*StepPerSlice);
if (flags & RolePostRecv) {
connStepPtr = conn->head;
*connStepPtr = step; // Return credits in case we rounded up.
}
if (flags & RoleWaitRecv) {
ncclShmem.groups[group].recvConns[index] = conn; // WaitRecv role saves since that's who needs it in setDataPtrs()
flags |= (conn->flags & NCCL_NVLS_MIN_POLL) ? NvlsMinPolling : 0;
connStepPtr = conn->tail;
connStepCache = loadStepValue(connStepPtr);
flags |= (conn->offsFifo != nullptr) ? OffsFifoEnabled : 0;
if (Direct) {
...
}
if (flags & OffsFifoEnabled)
connOffsFifoPtr = conn->offsFifo;
connEltsFifo = (T*)conn->buffs[NCCL_PROTO_SIMPLE];
}
}
}
Only threads with RoleWaitRecv and RolePostRecv execute loadRecvConn, reading the step which, as mentioned in previous sections, represents the position in the fifo. RolePostRecv threads are responsible for notifying recvPeer, so they need to save the head pointer from conn to connStepPtr. RoleWaitRecv threads are responsible for waiting until new data is in the fifo, so they need to save the tail pointer from conn to connStepPtr and cache the content in connStepCache to avoid frequent global memory reads. Finally, conn->buff (the fifo) is recorded in connEltsFifo.
__device__ __forceinline__ void loadSendConn(ncclDevChannelPeer *peer, int connIndex, struct ncclWorkElem* e) {
if (flags & (RoleWaitSend|RolePostSend)) {
auto *conn = &peer->send[connIndex];
step = conn->step;
step = roundUp(step, SlicePerChunk*StepPerSlice);
if (flags & RolePostSend) {
connStepPtr = conn->tail;
connEltsFifo = (T*)conn->buffs[NCCL_PROTO_SIMPLE];
}
if (flags & RoleWaitSend) {
ncclShmem.groups[group].sendConns[index] = conn; // WaitSend role saves since that's who needs it in setDataPtrs()
flags |= (conn->flags & NCCL_NVLS_MIN_POLL) ? NvlsMinPolling : 0;
connStepPtr = conn->head;
connStepCache = loadStepValue(connStepPtr);
flags |= (conn->offsFifo != nullptr) ? OffsFifoEnabled : 0;
if (flags & OffsFifoEnabled)
connOffsFifoPtr = conn->offsFifo;
connEltsFifo = (T*)conn->buffs[NCCL_PROTO_SIMPLE];
...
}
}
}
loadSendConn follows the same logic: RolePostSend threads are responsible for notifying send peer so they hold the tail pointer, RoleWaitSend threads are responsible for waiting for send peer so they hold the head pointer, then record the fifo.
Finally, setDataPtrs is executed to set userBuff as the user’s input and output.
__device__ void setDataPtrs(void const *inputBuf, void *outputBuf, uint64_t redOpArg, struct ncclWorkElemReg* e) {
if (flags & RoleInput) {
userBuff = (T*)inputBuf;
ncclShmem.redOpArgs[0] = redOpArg; // scaler for local input
}
if (flags & RoleOutput) userBuff = (T*)outputBuf;
...
}
This completes the initialization.
recvReduceSend#
__device__ __forceinline__ void recvReduceSend(intptr_t inpIx, int eltN, bool postOp=false) {
genericOp<0, 0, 1, 1, Input, -1>(inpIx, -1, eltN, postOp);
}
template <int DirectRecv1, int DirectSend1, int Recv, int Send, int SrcBuf, int DstBuf>
__device__ __forceinline__ void genericOp(
intptr_t srcIx, intptr_t dstIx, int nelem, bool postOp
) {
constexpr int DirectRecv = 1 && Direct && DirectRecv1;
constexpr int DirectSend = 1 && Direct && DirectSend1;
constexpr int Src = SrcBuf != -1;
constexpr int Dst = DstBuf != -1;
nelem = nelem < 0 ? 0 : nelem;
int sliceSize = stepSize*StepPerSlice;
sliceSize = max(divUp(nelem, 16*SlicePerChunk)*16, sliceSize/32);
int slice = 0;
int offset = 0;
...
}
In the template parameters, Recv indicates whether recv needs to be executed, Send indicates whether Send needs to be executed, SrcBuf indicates whether the input contains user’s src buff, and DstBuf indicates whether the output contains user’s dst buff. Then calculate to get DirectRecv and DirectSend as 0, Src as 1, and Dst as 0.
template <int DirectRecv1, int DirectSend1, int Recv, int Send, int SrcBuf, int DstBuf>
__device__ __forceinline__ void genericOp(
intptr_t srcIx, intptr_t dstIx, int nelem, bool postOp
) {
...
if (tid < nworkers && offset < nelem) {
do {
sliceSize = sliceSize < nelem-offset ? sliceSize : nelem-offset;
if (Src && (flags & (SrcBuf==Input ? RoleInput : RoleOutput)))
ncclShmem.groups[group].srcs[0] = userBuff + srcIx + offset;
if (Dst && (flags & (DstBuf==Input ? RoleInput : RoleOutput)))
ncclShmem.groups[group].dsts[0] = userBuff + dstIx + offset;
waitPeer<DirectRecv, DirectSend, Recv, Send, Src, Dst>(srcIx, dstIx, offset, sliceSize);
...
} while (slice < SlicePerChunk && offset < nelem);
}
...
}
In version 2.7.8, the worker threads responsible for data transmission and the synchronization threads are in the same loop, which introduces many branch instructions affecting performance. In the new version, the logic is split into two loops to improve performance, with worker threads executing the first loop and synchronization threads executing the second loop.
The RoleInput thread fills the user buff into srcs[0], then executes waitPeer. The waitPeer function is the previous waitSend and waitRecv, which will wait until data can be sent and received, and fill the data addresses into srcs and dsts.
template <int DirectRecv, int DirectSend, int Recv, int Send, int Src, int Dst>
__device__ __forceinline__ void waitPeer(intptr_t srcIx, intptr_t dstIx, int offset, int nelts) {
const bool isSendNotRecv = (Send && Recv) ? (flags & RoleWaitSend) : Send;
const bool noRecvWait = DirectRecv && Src && (flags & DirectRead); // no wait when directly reading from remote input
const bool noSendWait = DirectSend && (flags & (DirectRead|DirectWrite)); // no wait in empty send (e.g. directScatter) or direct remote write
if (((flags & (Recv*RoleWaitRecv)) && !noRecvWait) ||
((flags & (Send*RoleWaitSend)) && !noSendWait)) {
int spins = 0;
while (connStepCache + (isSendNotRecv ? NCCL_STEPS : 0) < step + StepPerSlice) {
connStepCache = loadStepValue(connStepPtr);
if (checkAbort(spins)) break;
}
}
...
}
Both noRecvWait and noSendWait are 0. For the RoleWaitSend thread, isSendNotRecv is 1, and since it holds the connStepPtr as head pointer, its waiting logic is that if the head pointer plus queue capacity is less than step + StepPerSlice, it cannot execute send as it would exceed queue capacity, so it waits in a loop. For the RoleWaitRecv thread, isSendNotRecv is 0, and since it holds the connStepPtr as tail pointer, its waiting logic is that if step + StepPerSlice exceeds the tail pointer, it means there’s no data in the queue, so it needs to wait.
template <int DirectRecv, int DirectSend, int Recv, int Send, int Src, int Dst>
__device__ __forceinline__ void waitPeer(intptr_t srcIx, intptr_t dstIx, int offset, int nelts) {
...
if (flags & (Recv*RoleWaitRecv | Send*RoleWaitSend)) {
if (isSendNotRecv && (flags & SizesFifoEnabled))
connSizesFifoPtr[step%NCCL_STEPS] = nelts*sizeof(T);
void **ptrs = isSendNotRecv ? (ncclShmem.groups[group].dsts + Dst)
: (ncclShmem.groups[group].srcs + Src);
if (flags & OffsFifoEnabled)
else if (isSendNotRecv && DirectSend) {
} else if (!isSendNotRecv && DirectRecv) {
}
else {
ptrs[index] = connEltsFifo + (step%NCCL_STEPS)*stepSize;
}
step += StepPerSlice;
}
}
Then it starts filling the srcs and dsts arrays by putting the slot corresponding to its own fifo in, and updates the step. So for recvReduceSend, srcs[0] is the user buff, srcs[1] is the fifo of the previous rank, dsts[0] is the fifo of the next rank, thus achieving the previously described function: receiving data from the previous rank, executing reduce with the user’s input buff, then sending to the next rank.
template <int DirectRecv1, int DirectSend1, int Recv, int Send, int SrcBuf, int DstBuf>
__device__ __forceinline__ void genericOp(
intptr_t srcIx, intptr_t dstIx, int nelem, bool postOp
) {
...
if (tid < nworkers && offset < nelem) {
do {
...
subBarrier();
int workSize = ncclShmem.aborted ? 0 : sliceSize;
if (DirectRecv && ncclShmem.groups[group].srcs[0] == ncclShmem.groups[group].dsts[0]
} else if (DirectSend && !DirectRecv && SrcBuf != Input && ncclShmem.groups[group].dsts[Dst] == nullptr) {
} else {
constexpr int PreOpSrcs = SrcBuf != Input ? 0 :
DirectRecv*MaxRecv == NCCL_MAX_DIRECT_ARITY ? (1+NCCL_MAX_DIRECT_ARITY) : 1;
reduceCopy<Unroll, RedOp, T,
MultimemSrcs, Recv+Src, Recv*MaxRecv+Src,
MultimemDsts, Send+Dst, Send*MaxSend+Dst, PreOpSrcs>
(tid, nworkers, ncclShmem.redOpArgs[0], ncclShmem.redOpArgs, postOp,
Recv*fan.nrecv()+Src, ncclShmem.groups[group].srcs,
Send*fan.nsend()+Dst, ncclShmem.groups[group].dsts,
workSize);
}
barrier(); // This barrier has a counterpart in following loop
postPeer<Recv, Send>(0 < sliceSize);
offset += sliceSize;
slice += 1;
} while (slice < SlicePerChunk && offset < nelem);
}
while (slice < SlicePerChunk) {
sliceSize = sliceSize < nelem-offset ? sliceSize : nelem-offset;
barrier(); // Has couterpart in preceding worker-only loop.
postPeer<Recv, Send>(0 < sliceSize);
offset += sliceSize;
slice += 1;
}
}
After waitPeer completes, indicating data transmission can begin, it first executes subBarrier() to synchronize all worker threads, ensuring they enter the data transmission logic only after waitPeer completes. Then it executes reduceCopy to perform reduce from srcs and copy to dsts. Then it executes barrier() for all threads, including worker and synchronization threads, because synchronization threads can only start post after data transmission ends. Let’s look at the postPeer executed by synchronization threads.
template<int Recv, int Send>
inline __device__ void postPeer(bool dataStored) {
if (flags & (Recv*RolePostRecv | Send*RolePostSend)) {
step += StepPerSlice;
if (Send && (flags & RolePostSend) && dataStored) fence_acq_rel_sys();
st_relaxed_sys_global(connStepPtr, step);
}
}
RolePost threads need to update step and write step to connStepPtr. For RolePostRecv holding the head pointer, it can write directly. For RolePostSend holding the tail pointer, to ensure data writing completes before post, it needs a fence. Here it uses acq_rel barrier, though release semantics would be sufficient for this scenario, but checking PTX shows there’s no separate release semantic instruction. For data reading scenarios, matching read barriers are also needed, but nccl’s implementation uses volatile which can bypass L1 cache, so barriers aren’t needed.
nvls#
ReduceScatter kernel#
if (tid < tidEndScatter) {
// Scatter
using Proto = ProtoSimple<1, 1, COLL_UNROLL>;
Primitives<T, RedOp, FanAsymmetric<0, NCCL_MAX_NVLS_ARITY>, /*Direct=*/0, Proto, 0>
prims(tid, nThreadsScatter, NULL, nvls->up, args->sendbuff, NULL,
args->redOpArg, 0 * Proto::MaxGroupWidth, 1, 1);
for (ssize_t gridOffset = 0; gridOffset < size; gridOffset += loopSize) {
ssize_t offset = gridOffset + bid * chunkSize;
int nelem = min(chunkSize, size - offset);
prims.scatter(offset, nvls->nHeads * size, nelem, size, -1, 0);
}
}
The scatter thread executes scatter operation through prim, with sendPeers as up, therefore including all ranks. inputBuf is the user’s input args->sendbuff, and connIndexSend is 1, so it loads the 1st send conn.
__device__ __forceinline__ void
scatter(intptr_t inpIx, ssize_t totalElem, int peerElem, ssize_t peerOffset, int skip, int shift) {
ScatterGatherOp<0, 0, 0, 1>(inpIx, -1, totalElem, peerElem, peerOffset, skip, shift, /*postOp=*/false);
}
template <int DirectRecv1, int DirectSend1, int Recv, int Send>
__device__ __forceinline__ void
ScatterGatherOp(intptr_t inpIx, intptr_t outIx, ssize_t totalElem, int peerElem, ssize_t peerOffset, int skip, int shift, bool postOp) {
constexpr int DirectRecv = 1 && Direct && DirectRecv1;
constexpr int DirectSend = 1 && Direct && DirectSend1;
int offset = 0; // slice offset
int sliceSize = stepSize*StepPerSlice;
int dataSize = max(DIVUP(peerElem, 16*SlicePerChunk)*16, sliceSize/32); // per-peer slice size
#pragma unroll
for (int slice=0; slice<SlicePerChunk; ++slice) {
ssize_t realSize = max(0, min(dataSize, peerElem-offset));
bool fenceNeeded = false;
if (tid < nworkers) {
if (Send) {
// Scatter pre-scales data of input buffer only in non-Direct case
constexpr int PreOpSrcs = DirectSend ? 0 : 1;
if (flags & RoleInput) ncclShmem.groups[group].srcs[0] = userBuff + inpIx + offset;
// realSize is not accurate here; but intra-node does not rely on sizes FIFO
waitPeer<0, DirectSend, 0, 1, 1, 0>(0, inpIx, offset, realSize);
subBarrier();
#pragma unroll
// Loop over peers
for (int j=0; j<fan.nsend(); j++) {
int i = (j+shift)%fan.nsend();
ssize_t pOffset = i*peerOffset;
// Skip the data I am responsible of reducing myself
if (skip >= 0 && i >= skip) pOffset += peerElem;
void* src0 = (T*)ncclShmem.groups[group].srcs[0] + pOffset;
ssize_t realPeerSize = min(realSize, totalElem-pOffset);
if (realPeerSize > 0 && ncclShmem.groups[group].dsts[i] != nullptr) {
reduceCopy<Unroll, RedOp, T, 0,1,1, 0,1,1, PreOpSrcs>(tid, nworkers, ncclShmem.redOpArgs[0], ncclShmem.redOpArgs, false, 1, &src0, 1, ncclShmem.groups[group].dsts+i, realPeerSize);
// Mark for threadfence at the end
fenceNeeded |= true;
}
}
} else if (Recv) {
}
}
fenceNeeded = barrierAny(fenceNeeded);
postPeer<Recv, Send>(fenceNeeded);
offset += realSize;
}
}
As shown in Figure 9, scatter takes the data from userBuff and sends it to all sendPeer corresponding buffers (peer[0]->send[1].buff and peer[1]->send[1].buff) at peerOffset intervals.
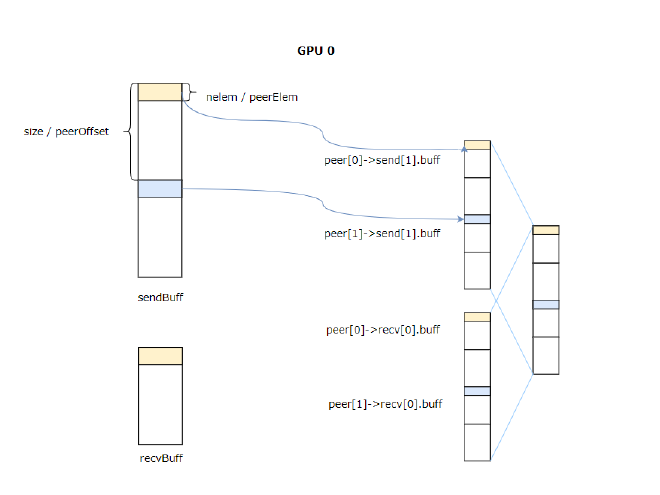
Figure 9#
For reduce threads, sendPeers is NULL, recvPeers is nvls->down, connIndexRecv is 0, so it loads the 0th recv conn and executes recv.
else if (tid < tidEndReduce) {
// Reduce through NVLS
using Proto = ProtoSimple<1, 1, COLL_UNROLL, 1, 0>;
Primitives<T, RedOp, FanAsymmetric<1, 0>, /*Direct=*/0, Proto, 0>
prims(tid - tidEndScatter, nThreadsReduce, &nvls->down, NULL, NULL, args->recvbuff,
args->redOpArg, 3 * Proto::MaxGroupWidth, 0, 0);
for (ssize_t gridOffset = 0; gridOffset < size; gridOffset += loopSize) {
ssize_t offset = gridOffset + bid * chunkSize;
int nelem = min(chunkSize, size - offset);
prims.recv(offset, nelem);
}
}
In the recv function, dst is set to args->recvbuff, src is the Multicast buffer corresponding to its own rank. As shown in Figure 10, after execution, GPU0’s recvBuff gets the reduced results corresponding to all cards.
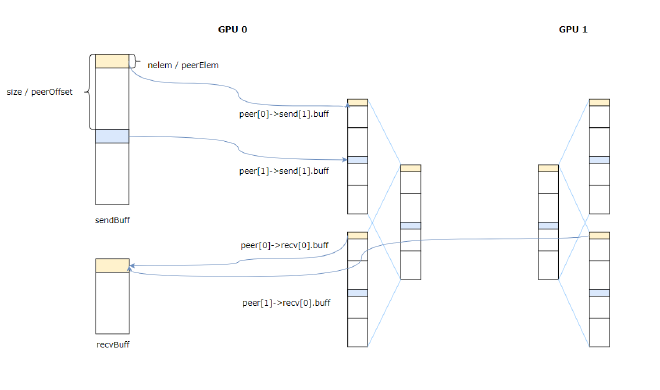
Figure 10#
reduceCopy kernel#
Taking ReduceScatter as an example, let’s look at how the reduceCopy kernel simultaneously supports Unicast buffer and Multicast buffer.
template<int Unroll, typename RedFn, typename T,
int MultimemSrcs, int MinSrcs, int MaxSrcs,
int MultimemDsts, int MinDsts, int MaxDsts, int PreOpSrcs,
typename IntBytes>
__device__ __forceinline__ void reduceCopy(
int thread, int nThreads,
uint64_t redArg, uint64_t *preOpArgs, bool postOp,
int nSrcs, void **srcPtrs, int nDsts, void **dstPtrs,
IntBytes nElts
) {
int lane = thread%WARP_SIZE;
// If a multimem src is present then our biggest pack size is limited to what
// is supported for this redfn/type.
constexpr int BigPackSize = (MultimemSrcs == 0) ? 16 : LoadMultimem_BigPackSize<RedFn>::BigPackSize;
IntBytes nBytesBehind = 0;
IntBytes nBytesAhead = nElts*sizeof(T);
#if __cpp_if_constexpr
if constexpr (BigPackSize > sizeof(T)) {
#else
if (BigPackSize > sizeof(T)) {
#endif
// Check that all pointers are BigPackSize aligned.
bool aligned = true;
if (lane < nSrcs) aligned &= 0 == cvta_to_global(srcPtrs[lane]) % (BigPackSize + !BigPackSize);
if (lane < nDsts) aligned &= 0 == cvta_to_global(dstPtrs[lane]) % (BigPackSize + !BigPackSize);
aligned = __all_sync(~0u, aligned);
if (aligned) {
reduceCopyPacks<RedFn, T, Unroll, BigPackSize,
MultimemSrcs, MinSrcs, MaxSrcs, MultimemDsts, MinDsts, MaxDsts, PreOpSrcs>
(nThreads, /*&*/thread, redArg, preOpArgs, postOp,
nSrcs, srcPtrs, nDsts, dstPtrs, /*&*/nBytesBehind, /*&*/nBytesAhead);
if (nBytesAhead == 0) return;
reduceCopyPacks<RedFn, T, /*Unroll=*/1, BigPackSize,
MultimemSrcs, MinSrcs, MaxSrcs, MultimemDsts, MinDsts, MaxDsts, PreOpSrcs>
(nThreads, /*&*/thread, redArg, preOpArgs, postOp,
nSrcs, srcPtrs, nDsts, dstPtrs, /*&*/nBytesBehind, /*&*/nBytesAhead);
if (nBytesAhead == 0) return;
}
}
...
}
In the template parameters, MultimemSrcs indicates how many inputs are multimem, MultimemDsts indicates how many outputs are multimem. In the parameters, thread is the tid, nThreads is the total number of threads, there are nSrcs inputs with addresses in srcPtrs, nDsts outputs stored in dstPtrs, and nElts is the number of elements. The function’s purpose is to reduce all src and store them to all dst.
nBytesBehind indicates how much data has been processed, nBytesAhead indicates how much data remains unprocessed.
Then it checks if vectorized instructions can be used. BigPackSize is the granularity of load/store instructions. If the input is non-Multimem, it tries to use 16 bytes (128 bits); if it’s multimem, it needs to check Func and data type - in this case it’s FuncSum, so it’s also 16 bytes.
template<typename Fn>
struct LoadMultimem_BigPackSize {
using T = typename Fn::EltType;
static constexpr bool IsSum = std::is_same<Fn, FuncSum<T>>::value ||
std::is_same<Fn, FuncPreMulSum<T>>::value ||
std::is_same<Fn, FuncSumPostDiv<T>>::value;
static constexpr bool IsMinMax = std::is_same<Fn, FuncMinMax<T>>::value;
static constexpr bool IsFloat = IsFloatingPoint<T>::value;
static constexpr int BigPackSize =
IsFloat && IsSum && sizeof(T) < 8 ? 16 :
IsFloat && IsSum ? 8 :
IsFloat && IsMinMax && sizeof(T)==2 ? 16 :
!IsFloat && (IsSum||IsMinMax) && sizeof(T)>=4 ? sizeof(T) :
/*multimem.ld_reduce not supported:*/ 0;
};
For vectorization, inputs and outputs need to be aligned. Let’s look at the reduceCopyPacks logic using alignment as an example.
template<typename RedFn, typename T, int Unroll, int BytePerPack,
int MultimemSrcs, int MinSrcs, int MaxSrcs,
int MultimemDsts, int MinDsts, int MaxDsts, int PreOpSrcs,
typename IntBytes>
__device__ __forceinline__ void reduceCopyPacks(
int nThreads, int &thread,
uint64_t redArg, uint64_t *preOpArgs, bool postOp,
int nSrcs, void **srcPtrs, int nDsts, void **dstPtrs,
IntBytes &nBytesBehind, IntBytes &nBytesAhead
) {
// A hunk is the amount of contiguous data a warp consumes per loop iteration
// assuming all threads partake.
constexpr int BytePerHunk = Unroll*WARP_SIZE*BytePerPack;
int nWarps = nThreads/WARP_SIZE;
int warp = thread/WARP_SIZE;
int lane = thread%WARP_SIZE;
...
}
BytePerPack is BigPackSize, which is 16 bytes. Assuming Unroll is 4, a warp’s memory access pattern is shown in Figure 11. A blue box is 32 16-byte segments, BytePerHunk is the continuous data length processed by a warp at once (4 blue boxes). The first thread in the warp will access the first 16 bytes in the 4 blue boxes pointed to by the arrow.
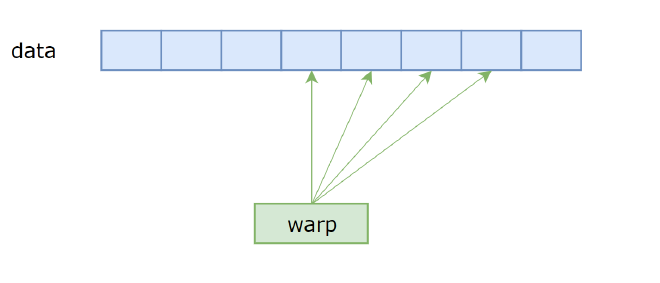
Figure 11#
Then initialize the starting position for each thread
__device__ __forceinline__ void reduceCopyPacks(...) {
// This thread's initial position.
IntBytes threadBytesBehind = nBytesBehind + (warp*BytePerHunk + lane*BytePerPack);
IntBytes threadBytesAhead = nBytesAhead - (warp*BytePerHunk + lane*BytePerPack);
// Number of hunks to be consumed over all warps.
IntBytes nHunksAhead = nBytesAhead/(BytePerHunk + !BytePerHunk);
// Advance collective position.
nBytesBehind += nHunksAhead*BytePerHunk;
nBytesAhead -= nHunksAhead*BytePerHunk;
if (Unroll==1 && BytePerPack <= nBytesAhead) {
// Only Unroll=1 can do partial hunks (where not all threads partake).
nHunksAhead += 1;
nBytesBehind += nBytesAhead - (nBytesAhead%(BytePerPack + !BytePerPack));
nBytesAhead = nBytesAhead%(BytePerPack + !BytePerPack);
}
nHunksAhead -= warp;
RedFn redFn(redArg);
uintptr_t minSrcs[MinSrcs + !MinSrcs];
uintptr_t minDsts[MinDsts + !MinDsts];
#pragma unroll
for (int s=0; s < MinSrcs; s++)
minSrcs[s] = cvta_to_global(srcPtrs[s]) + threadBytesBehind;
#pragma unroll
for (int d=0; d < MinDsts; d++)
minDsts[d] = cvta_to_global(dstPtrs[d]) + threadBytesBehind;
...
}
threadBytesBehind is the current thread’s starting position, threadBytesAhead is the amount of data the current thread needs to process, then record MinSrcs src and minDsts dst pointers to minSrcs and minDsts.
__device__ __forceinline__ void reduceCopyPacks(...) {
...
while (Unroll==1 ? (BytePerPack <= threadBytesAhead) : (0 < nHunksAhead)) {
BytePack<BytePerPack> acc[Unroll];
{ RedFn preFn(0 < PreOpSrcs ? preOpArgs[0] : 0);
#pragma unroll Unroll
for (int u=0; u < Unroll; u++) {
if (0 < MultimemSrcs) {
// applyLoadMultimem uses relaxed semantics for same reason we use volatile below.
acc[u] = applyLoadMultimem<RedFn, BytePerPack>(redFn, minSrcs[0]);
} else {
// Use volatile loads in case credits are polled for with volatile (instead of acquire).
acc[u] = ld_volatile_global<BytePerPack>(minSrcs[0]);
if (0 < PreOpSrcs) acc[u] = applyPreOp(preFn, acc[u]);
}
minSrcs[0] += WARP_SIZE*BytePerPack;
}
}
...
}
BytePack in this scenario is 16 bytes, described by a union, acc is used to store reduce results.
template<>
union alignas(16) BytePack<16> {
BytePack<8> half[2];
uint8_t u8[16];
uint16_t u16[8];
uint32_t u32[4];
uint64_t u64[2];
ulong2 ul2, native;
};
Then begin initializing acc. If there’s no multimem in the input, it will load 128b corresponding to the first blue box to acc[0] through ld_volatile_global, then loop Unroll times to load corresponding data from all blue boxes to acc. Let’s look at ld_volatile_global.
#define DEFINE_ld_st_16__space(space, addr_cxx_ty, addr_reg_ty) \
template<> \
__device__ __forceinline__ BytePack<16> ld_##space<16>(addr_cxx_ty addr) { \
BytePack<16> ans; \
asm("ld." #space ".v2.b64 {%0,%1}, [%2];" : "=l"(ans.u64[0]), "=l"(ans.u64[1]) : #addr_reg_ty(addr)); \
return ans; \
} \
template<> \
__device__ __forceinline__ BytePack<16> ld_volatile_##space<16>(addr_cxx_ty addr) { \
BytePack<16> ans; \
asm("ld.volatile." #space ".v2.b64 {%0,%1}, [%2];" : "=l"(ans.u64[0]), "=l"(ans.u64[1]) : #addr_reg_ty(addr)); \
return ans; \
} \
template<> \
__device__ __forceinline__ void st_##space<16>(addr_cxx_ty addr, BytePack<16> value) { \
asm("st." #space ".v2.b64 [%0], {%1,%2};" :: #addr_reg_ty(addr), "l"(value.u64[0]), "l"(value.u64[1]) : "memory"); \
}
DEFINE_ld_st_16__space(global, uintptr_t, l)
Since BytePerPack is 16, it will execute ld_volatile_global<16>, which is actually ld.volatile.global.v2.b64 loading 128b to ans’s u64[0] and u64[1].
When the input includes multimem, it will use applyLoadMultimem to load data, reduce it and store it to acc; st_global<16> stores BytePack’s u64[0] and u64[1] to addr using st.global.v2.b64.
#define SIZEOF_BytePack_field_u32 4
#define PTX_REG_BytePack_field_u32 "r"
DEFINE_Apply_LoadMultimem_sum_v4(float, f32, u32)
#define DEFINE_Apply_LoadMultimem_sum_v4(T, ptx_ty, pack_field) \
template<> \
struct Apply_LoadMultimem<FuncSum<T>, 4*(SIZEOF_BytePack_field_##pack_field)> { \
static constexpr int PackSize = 4*(SIZEOF_BytePack_field_##pack_field); \
__device__ static BytePack<PackSize> load(FuncSum<T> fn, uintptr_t addr) { \
BytePack<PackSize> ans; \
asm("multimem.ld_reduce.relaxed.sys.global.add.v4." #ptx_ty " {%0,%1,%2,%3}, [%4];" \
: "=" PTX_REG_BytePack_field_##pack_field(ans.pack_field[0]), \
"=" PTX_REG_BytePack_field_##pack_field(ans.pack_field[1]), \
"=" PTX_REG_BytePack_field_##pack_field(ans.pack_field[2]), \
"=" PTX_REG_BytePack_field_##pack_field(ans.pack_field[3]) \
: "l"(addr)); \
return ans; \
} \
};
We can see it uses multimem.ld_reduce.relaxed.sys.global.add.v4.f32 to execute reduce operations on 4 floats and store the result in acc.
After completing the first src read, continue reading other src to tmp, then execute reduce operation through Apply_Reduce, which performs elementwise sum on 4 floats.
__device__ __forceinline__ void reduceCopyPacks(...) {
...
while (Unroll==1 ? (BytePerPack <= threadBytesAhead) : (0 < nHunksAhead)) {
...
#pragma unroll (MinSrcs-1 + !(MinSrcs-1))
for (int s=1; s < MinSrcs; s++) {
BytePack<BytePerPack> tmp[Unroll];
RedFn preFn(s < PreOpSrcs ? preOpArgs[s] : 0);
#pragma unroll Unroll
for (int u=0; u < Unroll; u++) {
if (s < MultimemSrcs) {
// applyLoadMultimem uses relaxed semantics for same reason we use volatile below.
acc[u] = applyLoadMultimem<RedFn, BytePerPack>(redFn, minSrcs[s]);
} else {
// Use volatile loads in case credits are polled for with volatile (instead of acquire).
tmp[u] = ld_volatile_global<BytePerPack>(minSrcs[s]);
}
minSrcs[s] += WARP_SIZE*BytePerPack;
}
#pragma unroll Unroll
for (int u=0; u < Unroll; u++) {
if (s < PreOpSrcs) tmp[u] = applyPreOp(preFn, tmp[u]);
acc[u] = applyReduce(redFn, acc[u], tmp[u]);
}
}
for (int s=MinSrcs; (MinSrcs < MaxSrcs) && (s < MaxSrcs) && (s < nSrcs); s++) {
uintptr_t src = cvta_to_global(srcPtrs[s]) + threadBytesBehind;
BytePack<BytePerPack> tmp[Unroll];
RedFn preFn(s < PreOpSrcs ? preOpArgs[s] : 0);
#pragma unroll Unroll
for (int u=0; u < Unroll; u++) {
// Use volatile loads in case credits are polled for with volatile (instead of acquire).
tmp[u] = ld_volatile_global<BytePerPack>(src);
src += WARP_SIZE*BytePerPack;
}
#pragma unroll Unroll
for (int u=0; u < Unroll; u++) {
if (s < PreOpSrcs) tmp[u] = applyPreOp(preFn, tmp[u]);
acc[u] = applyReduce(redFn, acc[u], tmp[u]);
}
}
...
}
...
}
template<typename Fn, int EltPerPack>
struct Apply_Reduce {
template<int Size>
__device__ static BytePack<Size> reduce(Fn fn, BytePack<Size> a, BytePack<Size> b) {
a.half[0] = Apply_Reduce<Fn, EltPerPack/2>::reduce(fn, a.half[0], b.half[0]);
a.half[1] = Apply_Reduce<Fn, EltPerPack/2>::reduce(fn, a.half[1], b.half[1]);
return a;
}
};
template<typename T>
struct Apply_Reduce<FuncSum<T>, /*EltPerPack=*/1> {
__device__ static BytePack<sizeof(T)> reduce(FuncSum<T> fn, BytePack<sizeof(T)> a, BytePack<sizeof(T)> b) {
return toPack<T>(fromPack<T>(a) + fromPack<T>(b));
}
};
Now we have the reduce result of all inputs, then start storing to all output dst.
__device__ __forceinline__ void reduceCopyPacks(...) {
...
while (Unroll==1 ? (BytePerPack <= threadBytesAhead) : (0 < nHunksAhead)) {
...
#pragma unroll (MinDsts + !MinDsts)
for (int d=0; d < MinDsts; d++) {
#pragma unroll Unroll
for (int u=0; u < Unroll; u++) {
if (d < MultimemDsts) {
multimem_st_global(minDsts[d], acc[u]);
} else {
st_global<BytePerPack>(minDsts[d], acc[u]);
}
minDsts[d] += WARP_SIZE*BytePerPack;
}
}
for (int d=MinDsts; (MinDsts < MaxDsts) && (d < MaxDsts) && (d < nDsts); d++) {
uintptr_t dst = cvta_to_global(dstPtrs[d]) + threadBytesBehind;
#pragma unroll Unroll
for (int u=0; u < Unroll; u++) {
st_global<BytePerPack>(dst, acc[u]);
dst += WARP_SIZE*BytePerPack;
}
}
}
...
}
This completes the reduceCopy process. Note that in the nvls scenario, head, tail and other flags are mcBuff. Let’s look at how waitPeer determines if waiting is needed.
inline __device__ uint64_t loadStepValue(uint64_t* ptr) {
#if __CUDA_ARCH__ >= 900 && CUDART_VERSION >= 12010
if (flags & NvlsMinPolling) {
uint64_t ans;
asm("multimem.ld_reduce.acquire.sys.global.min.u64 %0, [%1];" : "=l"(ans) : "l"(cvta_to_global(ptr)));
return ans;
}
#endif
// volatile is faster than acquire but not as correct. Make sure reduceCopy
// loads data using volatile so it doesn't see stale data in L1.
return ld_volatile_global(ptr);
}
In the nvls scenario, flags will have NvlsMinPolling. Here it uses multimem.ld_reduce to read all peers’ steps and takes the min, so it only receives data when all peers are ready. It uses acquire semantics here, paired with postPeer’s release to ensure memory ordering.
Then look at postPeer
template<int Recv, int Send>
inline __device__ void postPeer(bool dataStored) {
if (flags & (Recv*RolePostRecv | Send*RolePostSend)) {
step += StepPerSlice;
if (Send && (flags & RolePostSend) && dataStored) fence_acq_rel_sys();
st_relaxed_sys_global(connStepPtr, step);
}
}
Here it uses non-multimem instructions to write mcBuff. The PTX manual says this is undefined behavior, but officially it’s acceptable for write operations.
AllReduce#
The allreduce kernel mainly has three thread groups. The scatter thread logic is as follows:
using Proto = ProtoSimple<1, 1, COLL_UNROLL>;
Primitives<T, RedOp, FanAsymmetric<0, NCCL_MAX_NVLS_ARITY>, /*Direct=*/0, Proto, 0>
prims(tid, nThreadsScatter, NULL, nvls->up, args->sendbuff, NULL,
args->redOpArg, 0 * Proto::MaxGroupWidth, 1, 1);
for (ssize_t gridOffset = 0; gridOffset < size; gridOffset += loopSize) {
ssize_t offset = gridOffset + bid * nvls->nHeads * chunkSize;
int nelem = args->regUsed ? 0 : min(nvls->nHeads * chunkSize, size - offset);
prims.scatter(offset, nelem, chunkSize, chunkSize, -1, 0);
}
Like ring allreduce, nvls loop size is nranks * chunkSize, which is variable nlem or loopSize. Scatter threads are responsible for sending data from sendbuff to nvls->up, connIndexSend is 1, so it uses the first send conn. After execution, it looks like Figure 12.
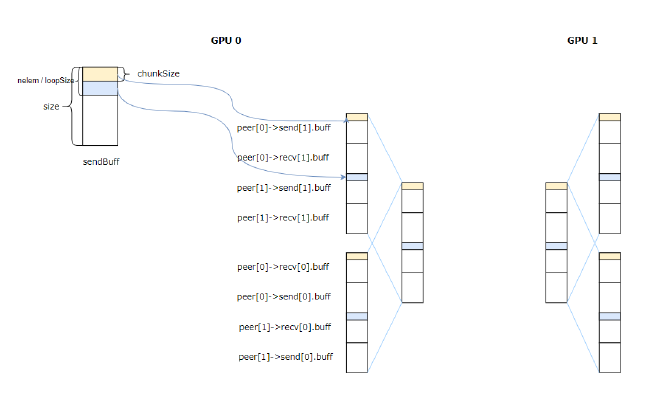
Figure 12#
The reduce thread group logic is shown below.
else if (tid < tidEndReduce && nvls->headRank != -1) {
if (!hasOut) {
// Reduce, broadcast through NVLS
using Proto = ProtoSimple<1, 1, COLL_UNROLL, 1, 1>;
Primitives<T, RedOp, FanSymmetric<1>, /*Direct=*/1, Proto, 0>
prims(tid - tidEndGather, nThreadsReduce, &nvls->down, &nvls->down, NULL, NULL,
args->redOpArg, 2 * Proto::MaxGroupWidth, 0, 0, args);
for (ssize_t gridOffset = 0; gridOffset < size; gridOffset += loopSize) {
ssize_t offset = gridOffset + (bid * nvls->nHeads + nvls->headRank) * chunkSize;
int nelem = min(chunkSize, size - offset);
prims.directRecvDirectSend(offset, offset, nelem);
}
}
...
}
Here MultimemSrcs and MultimemDsts are 1, using the 0th conn. After executing directRecvDirectSend, the effect is as shown in Figure 13. GPU 0 follows the yellow arrows, reducing the light yellow data blocks from both cards to get the dark yellow data block, then broadcasts the data to both cards using multimem.st. Similarly, GPU 1 follows the green arrows, reducing light blue data blocks to get the dark blue data block. At this point, both cards have the global data.
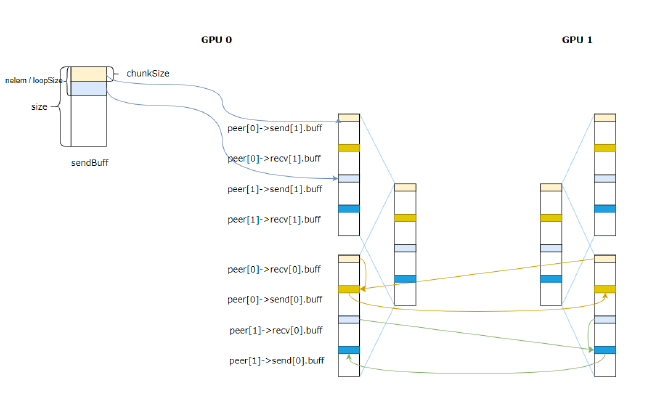
Figure 13#
Finally, gather threads are responsible for copying the global data to recvbuff.
} else if (tid < tidEndGather) {
// Gather
using Proto = ProtoSimple<1, 1, COLL_UNROLL>;
Primitives<T, RedOp, FanAsymmetric<NCCL_MAX_NVLS_ARITY, 0>, /*Direct=*/0, Proto, 0>
prims(tid - tidEndScatter, nThreadsGather, nvls->up, NULL, NULL, args->recvbuff,
args->redOpArg, 1 * Proto::MaxGroupWidth, 1, 1);
for (ssize_t gridOffset = 0; gridOffset < size; gridOffset += loopSize) {
ssize_t offset = gridOffset + bid * nvls->nHeads * chunkSize;
int nelem = args->regUsed ? 0 :min(nvls->nHeads * chunkSize, size - offset);
prims.gather(offset, nelem, chunkSize, chunkSize, -1, 0);
}
The gather process is ScatterGatherOp executing the recv branch, which we won’t elaborate on. After execution, it looks like Figure 14, completing the allreduce.
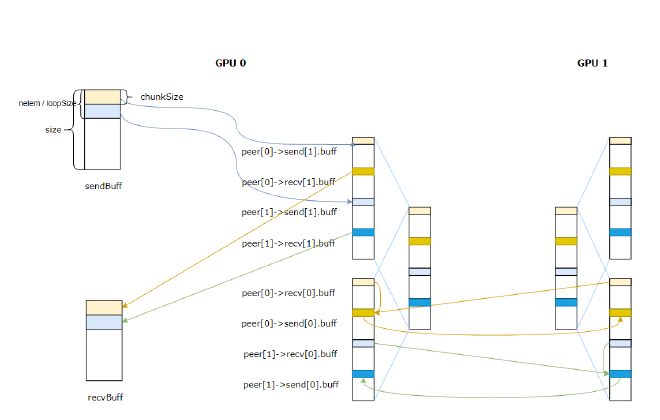
Figure 14#
Search Bandwidth#
Figure 15#
As mentioned earlier, when searching for channels, the bandwidth corresponding to head needs to be multiplied by 2. Taking Figure 15 as an example and recalling the Allreduce process, when GPU 0 executes ld_reduce, the bandwidth consumption is as shown in Figure 16
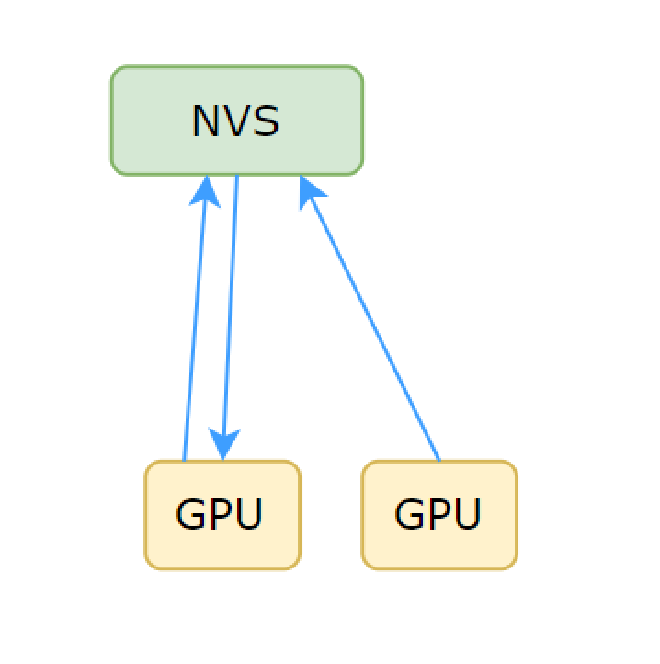
Figure 16#
Then when executing multimem.st, the bandwidth produced is as shown in Figure 17, so head needs double bandwidth.