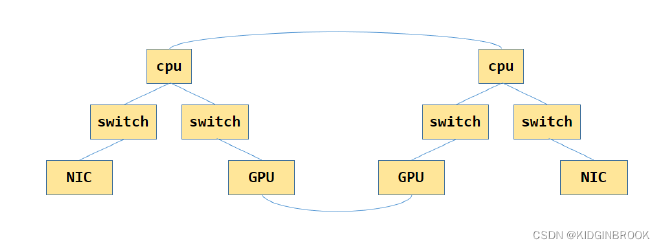
In the previous section, NCCL completed the mapping of the machine’s PCI system topology. The resulting graph is shown below, where GPUs are connected via NVLink:
To facilitate future channel searching, NCCL will first calculate the optimal paths and corresponding bandwidth between GPU/NIC nodes and all other nodes. The bandwidth is the minimum value of all edges along the optimal path.
Abstractly, this problem can be modeled as: given an undirected graph where each edge has a weight, and given a query (u, v), find a path from node u to node v that maximizes the minimum edge weight along the path. This is similar to finding the minimum bottleneck path in an undirected graph, which can be solved using spanning trees + LCA. If u is fixed in the query, it can also be solved using an SPFA-like method with modified relaxation.
Let’s first cover the graph data structure that we forgot to introduce in the previous section:
Edges in the graph are represented by ncclTopoLink, where type distinguishes edge types like NVLink and PCI; width represents bandwidth; remNode represents the connected node at the other end.
The final calculated paths between nodes are represented by ncclTopoLinkList, where count is the number of edges in the path, width is the path’s bandwidth (the minimum bandwidth among count edges), and list contains the specific edges.
struct ncclTopoLink {
int type;
float width;
struct ncclTopoNode* remNode;
};
struct ncclTopoLinkList {
struct ncclTopoLink* list[NCCL_TOPO_MAX_HOPS];
int count;
float width;
int type;
};
The path type has the following enumeration values:
#define PATH_LOC 0
#define PATH_NVL 1
#define PATH_PIX 2
#define PATH_PXB 3
#define PATH_PHB 4
#define PATH_SYS 5
#define PATH_NET 6
PATH_LOC is for a node to itself, PATH_NVL indicates all edges are NVLink, PATH_PIX indicates passing through at most one PCIe switch, PATH_PXB indicates passing through multiple PCIe switches but no CPU, PATH_PHB indicates passing through CPU, PATH_SYS indicates paths between different NUMA nodes.
Each node is represented by ncclTopoNode, where nlinks indicates how many edges the node has, links stores the connected edges, and paths stores paths to other nodes. paths[type][id] in node1 represents the path from node1 to the id-th node of type.
ncclTopoNodeSet represents all nodes of a certain type (like GPU, PCI, NIC, etc.), and ncclTopoSystem stores all types of nodes globally.
struct ncclTopoNodeSet {
int count;
struct ncclTopoNode nodes[NCCL_TOPO_MAX_NODES];
};
struct ncclTopoSystem {
struct ncclTopoNodeSet nodes[NCCL_TOPO_NODE_TYPES];
float maxWidth;
};
struct ncclTopoNode {
int type;
int64_t id;
// Type specific data
union {
struct {
int dev; // NVML dev number
int rank;
int cudaCompCap;
int gdrSupport;
}gpu;
struct {
uint64_t asic;
int port;
float width;
int gdrSupport;
int collSupport;
int maxChannels;
}net;
struct {
int arch;
int vendor;
int model;
cpu_set_t affinity;
}cpu;
};
int nlinks;
struct ncclTopoLink links[NCCL_TOPO_MAX_LINKS];
// Pre-computed paths to GPUs and NICs
struct ncclTopoLinkList* paths[NCCL_TOPO_NODE_TYPES];
// Used during search
uint64_t used;
};
Let’s look at NCCL’s path calculation process, which mainly consists of these three steps:
NCCLCHECK(ncclTopoComputePaths(comm->topo, comm->peerInfo));
// Remove inaccessible GPUs and unused NICs
NCCLCHECK(ncclTopoTrimSystem(comm->topo, comm));
// Recompute paths after trimming
NCCLCHECK(ncclTopoComputePaths(comm->topo, comm->peerInfo));
Here ncclTopoComputePaths performs the path calculation, ncclTopoTrimSystem removes unused nodes. Let’s examine these in detail:
ncclResult_t ncclTopoComputePaths(struct ncclTopoSystem* system, struct ncclPeerInfo* peerInfos) {
// Precompute paths between GPUs/NICs.
// Remove everything in case we're re-computing
for (int t=0; t<NCCL_TOPO_NODE_TYPES; t++) ncclTopoRemovePathType(system, t);
// Set direct paths from/to CPUs. We need them in many cases.
for (int c=0; c<system->nodes[CPU].count; c++) {
NCCLCHECK(ncclTopoSetPaths(system->nodes[CPU].nodes+c, system));
}
...
}
First, ncclTopoRemovePathType clears all paths in nodes.
ncclTopoSetPaths calculates paths from all other nodes to baseNode. It iterates through all CPU nodes to calculate paths from all other nodes to all CPU nodes.
ncclTopoSetPaths implements something similar to SPFA. Since this version of NCCL doesn’t allow GPUs as intermediate nodes in paths, GPU nodes won’t be added to the queue to update other nodes during SPFA. Since the undirected graph has no cycles in this scenario, the SPFA process is equivalent to BFS.
Here baseNode is the CPU node. First, space is allocated for CPU-to-CPU paths. nodeList and nextNodeList act as queues, with baseNode being enqueued first.
The getPath function retrieves the path from node to the id-th node of type t.
static ncclResult_t getPath(struct ncclTopoSystem* system, struct ncclTopoNode* node, int t, int64_t id, struct ncclTopoLinkList** pat
h);
getPath retrieves the CPU node’s path to itself, then sets count to 0, bandwidth to LOC_WIDTH, and type to PATH_LOC.
Then it repeatedly takes a node from nodeList, gets the path from node to baseNode, and uses node to update its connected nodes. It iterates through node’s edges (link), gets the remote node (remNode), gets remNode’s path to baseNode (remPath), and compares which path is better - the original remPath or the new path+link. The new path’s bandwidth (width) is the min of path and link bandwidths. If width is greater than remPath->width, remPath is updated to path+link.
static ncclResult_t ncclTopoSetPaths(struct ncclTopoNode* baseNode, struct ncclTopoSystem* system) {
if (baseNode->paths[baseNode->type] == NULL) {
NCCLCHECK(ncclCalloc(baseNode->paths+baseNode->type, system->nodes[baseNode->type].count));
}
// breadth-first search to set all paths to that node in the system
struct ncclTopoNodeList nodeList;
struct ncclTopoNodeList nextNodeList;
nodeList.count = 1; nodeList.list[0] = baseNode;
nextNodeList.count = 0;
struct ncclTopoLinkList* basePath;
NCCLCHECK(getPath(system, baseNode, baseNode->type, baseNode->id, &basePath));
basePath->count = 0;
basePath->width = LOC_WIDTH;
basePath->type = PATH_LOC;
while (nodeList.count) {
nextNodeList.count = 0;
for (int n=0; n<nodeList.count; n++) {
struct ncclTopoNode* node = nodeList.list[n];
struct ncclTopoLinkList* path;
NCCLCHECK(getPath(system, node, baseNode->type, baseNode->id, &path));
for (int l=0; l<node->nlinks; l++) {
struct ncclTopoLink* link = node->links+l;
struct ncclTopoNode* remNode = link->remNode;
if (remNode->paths[baseNode->type] == NULL) {
NCCLCHECK(ncclCalloc(remNode->paths+baseNode->type, system->nodes[baseNode->type].count));
}
struct ncclTopoLinkList* remPath;
NCCLCHECK(getPath(system, remNode, baseNode->type, baseNode->id, &remPath));
float width = std::min(path->width, link->width);
if (remPath->width < width) {
// Find reverse link
for (int l=0; l<remNode->nlinks; l++) {
if (remNode->links[l].remNode == node) {
remPath->list[0] = remNode->links+l;
break;
}
}
if (remPath->list[0] == NULL) {
WARN("Failed to find reverse path from remNode %d/%lx nlinks %d to node %d/%lx",
remNode->type, remNode->id, remNode->nlinks, node->type, node->id);
return ncclInternalError;
}
// Copy the rest of the path
for (int i=0; i<path->count; i++) remPath->list[i+1] = path->list[i];
remPath->count = path->count + 1;
remPath->width = width;
// Start with path type = link type. PATH and LINK types are supposed to match.
// Don't consider LINK_NET as we only care about the NIC->GPU path.
int type = link->type == LINK_NET ? 0 : link->type;
// Differentiate between one and multiple PCI switches
if (type == PATH_PIX && (node->type == PCI || link->remNode->type == PCI) && remPath->count > 3) type = PATH_PXB;
// Consider a path going through the CPU as PATH_PHB
if (link->type == LINK_PCI && (node->type == CPU || link->remNode->type == CPU)) type = PATH_PHB;
// Ignore Power CPU in an NVLink path
if (path->type == PATH_NVL && type == PATH_SYS && link->remNode->type == CPU &&
link->remNode->cpu.arch == NCCL_TOPO_CPU_ARCH_POWER) type = 0;
remPath->type = std::max(path->type, type);
// Add to the list for the next iteration if not already in the list
// Disallow GPUs as intermediate steps for now
if (remNode->type != GPU) {
int i;
for (i=0; i<nextNodeList.count; i++) if (nextNodeList.list[i] == remNode) break;
if (i == nextNodeList.count) nextNodeList.list[nextNodeList.count++] = remNode;
}
}
}
}
memcpy(&nodeList, &nextNodeList, sizeof(nodeList));
}
return ncclSuccess;
}
After updating the path, remPath’s type needs to be calculated. There’s a trick here where the edge type from the previous section corresponds to the path type in this section - for example, LINK_PCI equals PATH_PIX. This shows how the various path types mentioned earlier are calculated.
First, calculate the type for the current link as a path, initialized as the link’s type. For example, if the edge is LINK_PCI, it’s LINK_PIX. If remPath’s count is greater than 3, type updates to PATH_PXB (though there’s a question of whether exceeding 3 might cross two PCIe switches). If the link has one end at CPU, type further updates to PATH_PHB. Finally, take the max: remPath->type = std::max(path->type, type).
#define LINK_LOC 0
#define LINK_NVL 1
#define LINK_PCI 2
// Skipping 3 for PATH_PXB
// Skipping 4 for PATH_PHB
#define LINK_SYS 5
#define LINK_NET 6
#define PATH_LOC 0
#define PATH_NVL 1
#define PATH_PIX 2
#define PATH_PXB 3
#define PATH_PHB 4
#define PATH_SYS 5
#define PATH_NET 6
If remNode isn’t a GPU, it’s added to nextNodeList. After nodeList is fully traversed, nextNodeList is assigned to nodeList to continue traversal.
Back to ncclTopoComputePaths, it uses ncclTopoSetPaths again to calculate distances from GPU nodes to all other nodes.
ncclResult_t ncclTopoComputePaths(struct ncclTopoSystem* system, struct ncclPeerInfo* peerInfos) {
...
// Set direct paths from/to GPUs.
for (int g=0; g<system->nodes[GPU].count; g++) {
// Compute paths to GPU g
NCCLCHECK(ncclTopoSetPaths(system->nodes[GPU].nodes+g, system));
// Update path when we don't want to / can't use GPU Direct P2P
for (int p=0; p<system->nodes[GPU].count; p++) {
int p2p, read;
NCCLCHECK(ncclTopoCheckP2p(system, system->nodes[GPU].nodes[p].id, system->nodes[GPU].nodes[g].id, &p2p, &read));
if (p2p == 0) {
// Divert all traffic through the CPU
int cpu;
NCCLCHECK(getLocalCpu(system, g, &cpu));
NCCLCHECK(addCpuStep(system, cpu, GPU, p, GPU, g));
}
}
if (peerInfos == NULL) continue;
// Remove GPUs we can't talk to because of containers.
struct ncclPeerInfo* dstInfo = peerInfos+system->nodes[GPU].nodes[g].gpu.rank;
for (int p=0; p<system->nodes[GPU].count; p++) {
if (p == g) continue;
struct ncclPeerInfo* srcInfo = peerInfos+system->nodes[GPU].nodes[p].gpu.rank;
int shm;
NCCLCHECK(ncclTransports[TRANSPORT_SHM].canConnect(&shm, system, NULL, srcInfo, dstInfo));
if (shm == 0) {
// Mark this peer as inaccessible. We'll trim it later.
system->nodes[GPU].nodes[p].paths[GPU][g].count = 0;
}
}
}
// Set direct paths from/to NICs.
for (int n=0; n<system->nodes[NET].count; n++) {
struct ncclTopoNode* netNode = system->nodes[NET].nodes+n;
NCCLCHECK(ncclTopoSetPaths(netNode, system));
for (int g=0; g<system->nodes[GPU].count; g++) {
// Update path when we dont want to / can't use GPU Direct RDMA.
int gdr;
NCCLCHECK(ncclTopoCheckGdr(system, system->nodes[GPU].nodes[g].id, netNode->id, 0, &gdr));
if (gdr == 0) {
// We cannot use GPU Direct RDMA, divert all traffic through the CPU local to the GPU
int localCpu;
NCCLCHECK(getLocalCpu(system, g, &localCpu));
NCCLCHECK(addCpuStep(system, localCpu, NET, n, GPU, g));
NCCLCHECK(addCpuStep(system, localCpu, GPU, g, NET, n));
}
}
}
return ncclSuccess;
}
Then ncclTopoCheckP2p checks if p2p communication is possible between the current GPU node and all other GPU nodes. This essentially checks if the path type from gpu1 to gpu2 meets p2pLevel restrictions. By default, p2pLevel is PATH_SYS - if users haven’t set it via environment variables, there’s effectively no restriction and any GPUs can use p2p communication. Additionally, p2p read is supported if the path type is PATH_NVL.
ncclResult_t ncclTopoCheckP2p(struct ncclTopoSystem* system, int64_t id1, int64_t id2, int* p2p, int *read) {
*p2p = 0;
*read = 0;
// Get GPUs from topology
int g1, g2;
NCCLCHECK(ncclTopoIdToIndex(system, GPU, id1, &g1));
struct ncclTopoNode* gpu1 = system->nodes[GPU].nodes+g1;
if (ncclTopoIdToIndex(system, GPU, id2, &g2) == ncclInternalError) {
// GPU not found, we can't use p2p.
return ncclSuccess;
}
struct ncclTopoLinkList* path = gpu1->paths[GPU]+g2;
// In general, use P2P whenever we can.
int p2pLevel = PATH_SYS;
// User override
if (ncclTopoUserP2pLevel == -1)
NCCLCHECK(ncclGetLevel(&ncclTopoUserP2pLevel, "NCCL_P2P_DISABLE", "NCCL_P2P_LEVEL"));
if (ncclTopoUserP2pLevel != -2) {
p2pLevel = ncclTopoUserP2pLevel;
goto compare;
}
// Don't use P2P through ARM CPUs
int arch, vendor, model;
NCCLCHECK(ncclTopoCpuType(system, &arch, &vendor, &model));
if (arch == NCCL_TOPO_CPU_ARCH_ARM) p2pLevel = PATH_PXB;
if (arch == NCCL_TOPO_CPU_ARCH_X86 && vendor == NCCL_TOPO_CPU_VENDOR_INTEL) {
if (model == NCCL_TOPO_CPU_TYPE_BDW) p2pLevel = PATH_PXB;
else p2pLevel = PATH_PHB;
}
compare:
// Compute the PCI distance and compare with the p2pLevel.
if (path->type <= p2pLevel) *p2p = 1;
if (path->type == PATH_NVL) {
struct ncclTopoNode* gpu2 = system->nodes[GPU].nodes+g2;
// Enable P2P Read for Ampere/NVLink only
if ((gpu1->gpu.cudaCompCap == gpu2->gpu.cudaCompCap) && (gpu1->gpu.cudaCompCap == 80)) *read = 1;
}
return ncclSuccess;
}
Then it checks if the current GPU can communicate with other GPUs via shm. In Docker environments, communication might be impossible if shm is mounted differently. If shm communication isn’t possible, path’s count is set to 0, and the corresponding node will be deleted later (though there’s a question of why p2p availability isn’t checked when shm fails).
Finally, similar to GPUs, ncclTopoSetPaths is executed for all NICs to calculate paths, then each NIC and GPU pair is checked for gdr support.
ncclResult_t ncclTopoCheckGdr(struct ncclTopoSystem* system, int64_t busId, int netDev, int read, int* useGdr) {
*useGdr = 0;
// Get GPU and NET
int n, g;
NCCLCHECK(ncclTopoIdToIndex(system, NET, netDev, &n));
struct ncclTopoNode* net = system->nodes[NET].nodes+n;
NCCLCHECK(ncclTopoIdToIndex(system, GPU, busId, &g));
struct ncclTopoNode* gpu = system->nodes[GPU].nodes+g;
// Check that both the NIC and GPUs support it
if (net->net.gdrSupport == 0) return ncclSuccess;
if (gpu->gpu.gdrSupport == 0) return ncclSuccess;
if (read) { // For reads (sends) only enable under certain conditions
int gdrReadParam = ncclParamNetGdrRead();
if (gdrReadParam == 0) return ncclSuccess;
if (gdrReadParam < 0) {
int nvlink = 0;
// Since we don't know whether there are other communicators,
// it's better to keep things local if we have a single GPU.
if (system->nodes[GPU].count == 1) nvlink = 1;
for (int i=0; i<system->nodes[GPU].count; i++) {
if (i == g) continue;
if (gpu->paths[GPU][i].type == PATH_NVL) {
nvlink = 1;
break;
}
}
if (!nvlink) return ncclSuccess;
}
}
// Check if we are close enough that it makes sense to enable GDR
int netGdrLevel = PATH_PXB;
NCCLCHECK(ncclGetLevel(&ncclTopoUserGdrLevel, NULL, "NCCL_NET_GDR_LEVEL"));
if (ncclTopoUserGdrLevel != -2) netGdrLevel = ncclTopoUserGdrLevel;
int distance = gpu->paths[NET][n].type;
if (distance > netGdrLevel) {
INFO(NCCL_NET,"GPU Direct RDMA Disabled for GPU %lx / HCA %d (distance %d > %d)", busId, netDev, distance, netGdrLevel);
return ncclSuccess;
}
*useGdr = 1;
INFO(NCCL_NET,"GPU Direct RDMA Enabled for GPU %lx / HCA %d (distance %d <= %d), read %d", busId, netDev, distance, netGdrLevel, read);
return ncclSuccess;
}
Besides checking previous gdr support, it also checks if the distance between GPU and NIC is less than netGdrLevel. netGdrLevel defaults to PATH_PXB but can be user-defined. The default PXB value is explained in the official documentation:
Even though the only theoretical requirement for GPUDirect RDMA to work between a third-party device and an NVIDIA GPU is that they share the same root complex, there exist bugs (mostly in chipsets) causing it to perform badly, or not work at all in certain setups. We can distinguish between three situations, depending on what is on the path between the GPU and the third-party device:
- PCIe switches only
- single CPU/IOH
- CPU/IOH <-> QPI/HT <-> CPU/IOH
The first situation, where there are only PCIe switches on the path, is optimal and yields the best performance. The second one, where a single CPU/IOH is involved, works, but yields worse performance ( especially peer-to-peer read bandwidth has been shown to be severely limited on some processor architectures ). Finally, the third situation, where the path traverses a QPI/HT link, may be extremely performance-limited or even not work reliably.
We can see that performance is best when only passing through PCIe switches, worse when passing through CPU, and worst or potentially unusable when crossing NUMA nodes.
When p2p or gdr isn’t supported, communication goes through CPU relay. getLocalCpu finds the nearest CPU c.
static ncclResult_t getLocalCpu(struct ncclTopoSystem* system, int gpu, int* retCpu) {
// Find the closest CPU to a GPU
int minHops = 0;
int localCpu = -1;
struct ncclTopoLinkList* paths = system->nodes[GPU].nodes[gpu].paths[CPU];
for (int c=0; c<system->nodes[CPU].count; c++) {
int hops = paths[c].count;
if (minHops == 0 || hops < minHops) {
localCpu = c;
minHops = hops;
}
}
if (localCpu == -1) {
WARN("Error : could not find CPU close to GPU %d", gpu);
return ncclInternalError;
}
*retCpu = localCpu;
return ncclSuccess;
}
Then addCpuStep modifies the path from i1 to i2 to become the path from i1 to c plus the path from cpu to i2.
static ncclResult_t addCpuStep(struct ncclTopoSystem* system, int c, int t1, int i1, int t2, int i2) {
struct ncclTopoNode* cpuNode = system->nodes[CPU].nodes+c;
struct ncclTopoNode* srcNode = system->nodes[t1].nodes+i1;
int l=0;
// Node 1 -> CPU
for (int i=0; i<srcNode->paths[CPU][c].count; i++) srcNode->paths[t2][i2].list[l++] = srcNode->paths[CPU][c].list[i];
// CPU -> Node 2
for (int i=0; i<cpuNode->paths[t2][i2].count; i++) srcNode->paths[t2][i2].list[l++] = cpuNode->paths[t2][i2].list[i];
// Update path characteristics
srcNode->paths[t2][i2].count = l;
srcNode->paths[t2][i2].type = std::max(srcNode->paths[CPU][c].type, cpuNode->paths[t2][i2].type);
srcNode->paths[t2][i2].width = std::min(srcNode->paths[CPU][c].width, cpuNode->paths[t2][i2].width);
return ncclSuccess;
}
This completes ncclTopoComputePaths. Next, ncclTopoTrimSystem removes unreachable GPU nodes and unused NICs from the graph.
ncclResult_t ncclTopoTrimSystem(struct ncclTopoSystem* system, struct ncclComm* comm) {
int *domains;
int64_t *ids;
NCCLCHECK(ncclCalloc(&domains, system->nodes[GPU].count));
NCCLCHECK(ncclCalloc(&ids, system->nodes[GPU].count));
int myDomain = 0;
for (int g=0; g<system->nodes[GPU].count; g++) {
struct ncclTopoNode* gpu = system->nodes[GPU].nodes+g;
domains[g] = g;
ids[g] = gpu->id;
for (int p=0; p<g; p++) {
if (gpu->paths[GPU][p].count > 0) {
domains[g] = std::min(domains[g], domains[p]);
}
}
if (gpu->gpu.rank == comm->rank) myDomain = domains[g];
}
int ngpus = system->nodes[GPU].count;
for (int i=0; i<ngpus; i++) {
if (domains[i] == myDomain) continue;
struct ncclTopoNode* gpu = NULL;
int g;
for (g=0; g<system->nodes[GPU].count /* This one varies over the loops */; g++) {
gpu = system->nodes[GPU].nodes+g;
if (gpu->id == ids[i]) break; else gpu=NULL;
}
if (gpu == NULL) {
WARN("Could not find id %lx", ids[i]);
free(domains);
free(ids);
return ncclInternalError;
}
NCCLCHECK(ncclTopoRemoveNode(system, GPU, g));
}
comm->localRanks = system->nodes[GPU].count;
if (system->nodes[GPU].count == comm->nRanks) {
for (int n=system->nodes[NET].count-1; n>=0; n--)
NCCLCHECK(ncclTopoRemoveNode(system, NET, n));
}
free(domains);
free(ids);
return ncclSuccess;
}
First, using a union-find-like approach, multiple GPU nodes are merged into sets. myDomain is the set number corresponding to the current rank’s GPU. Then GPU nodes not belonging to myDomain are removed from the graph. Finally, if the comm’s rank count equals the number of GPU nodes in the graph, it means NICs aren’t needed, so they’re also removed from the graph.
After getting the new graph structure, ncclTopoComputePaths is executed once more to get the final paths between all nodes.