In previous sections, we looked at the nccl send/recv communication process. In this section, we’ll examine the collective communication process using ring allreduce as an example. The overall execution flow is similar to send/recv, so we’ll briefly cover similar processes and focus mainly on ring allreduce’s unique characteristics.
Single Machine
Searching for the ring#
During nccl initialization, the internal topology is analyzed, creating a topology graph of CPU, GPU, NIC, and other PCI nodes. Based on this graph, a series of channels are searched. Assume the ring searched by ncclTopoCompute on a single machine is:
graph->intra: GPU/0 GPU/1 GPU/2 GPU/3 GPU/4 GPU/5 GPU/6 GPU/7
Then set prev and next for each channel’s ncclRing, representing the previous and next GPUs for the current rank. For example, GPU0’s prev is GPU7, and next is GPU1.
Establishing connections#
Then begin establishing connections from the current rank to prev and next GPUs
for (int c=0; c<comm->nChannels; c++) {
struct ncclChannel* channel = comm->channels+c;
NCCLCHECKGOTO(setupChannel(comm, c, rank, nranks, rings+c*nranks), ret, affinity_restore);
if (comm->nRanks == 1) continue;
NCCLCHECKGOTO(ncclTransportP2pSetup(comm, &ringGraph, channel, 1, &channel->ring.prev, 1, &channel->ring.next), ret, affinity_restore);
}
After connections are established, as shown in the diagram, buff is on the sending end, while head and tail are shared by both send and recv ends.
For ease of explanation, let’s establish some conventions: assume the send end is rank0 and recv end is rank1. sendbuff refers to the input passed by the user executing the API, recvbuff refers to the output passed by the user executing the API; buffer refers to the buff shown in figure 1; The actual process of rank0 sending data to rank1 involves copying data from sendbuff to buff located at rank0, and the recv end receives data by copying from buff at rank0 to recvbuff, but we’ll describe the send process as sending sendbuff to rank1’s buffer, and the receive process as copying data from the current rank’s buffer to recvbuff (in other words, assuming buff is at rank1 for easier understanding)
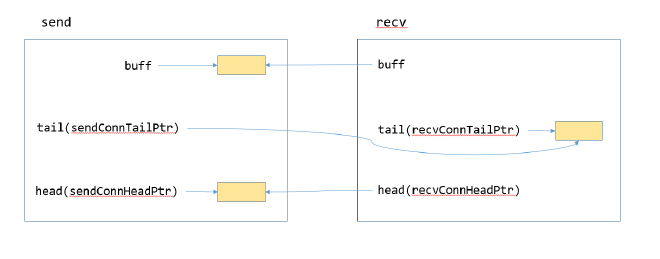
Figure 1#
Executing API#
After completing the above initialization, users begin executing allreduce.
ncclResult_t ncclAllReduce(const void* sendbuff, void* recvbuff, size_t count,
ncclDataType_t datatype, ncclRedOp_t op, ncclComm* comm, cudaStream_t stream) {
struct ncclInfo info = { ncclCollAllReduce, "AllReduce",
sendbuff, recvbuff, count, datatype, op, 0, comm, stream, /* Args */
ALLREDUCE_CHUNKSTEPS, ALLREDUCE_SLICESTEPS };
return ncclEnqueueCheck(&info);
}
enqueue#
After creating info, execute ncclEnqueueCheck, assuming it’s not a group operation
ncclResult_t ncclEnqueueCheck(struct ncclInfo* info) {
// Launch asynchronously if needed
if (ncclAsyncMode()) {
...
} else {
NCCLCHECK(PtrCheck(info->comm, info->opName, "comm"));
NCCLCHECK(ArgsCheck(info));
NCCLCHECK(checkSetStream(info));
INFO(NCCL_COLL,"%s: opCount %lx sendbuff %p recvbuff %p count %zi datatype %d op %d root %d comm %p [nranks=%d] stream %p",
info->opName, info->comm->opCount, info->sendbuff, info->recvbuff, info->count,
info->datatype, info->op, info->root, info->comm, info->comm->nRanks, info->stream);
NCCLCHECK(ncclSaveKernel(info));
NCCLCHECK(ncclBarrierEnqueue(info->comm));
NCCLCHECK(ncclBarrierEnqueueWait(info->comm));
NCCLCHECK(ncclEnqueueEvents(info->comm));
return ncclSuccess;
}
}
ncclSaveKernel#
Then use ncclSaveKernel to add parameters and other information to the channel.
ncclResult_t ncclSaveKernel(struct ncclInfo* info) {
...
struct ncclColl coll;
struct ncclProxyArgs proxyArgs;
memset(&proxyArgs, 0, sizeof(struct ncclProxyArgs));
NCCLCHECK(computeColl(info, &coll, &proxyArgs));
info->comm->myParams->blockDim.x = std::max<unsigned>(info->comm->myParams->blockDim.x, info->nThreads);
int nChannels = info->coll == ncclCollSendRecv ? 1 : coll.args.coll.nChannels;
int nSubChannels = (info->pattern == ncclPatternCollTreeUp || info->pattern == ncclPatternCollTreeDown) ? 2 : 1;
for (int bid=0; bid<nChannels*nSubChannels; bid++) {
int channelId = (info->coll == ncclCollSendRecv) ? info->channelId :
info->comm->myParams->gridDim.x % info->comm->nChannels;
struct ncclChannel* channel = info->comm->channels+channelId;
if (channel->collCount == NCCL_MAX_OPS) {
WARN("Too many aggregated operations on channel %d (%d max)", channel->id, NCCL_MAX_OPS);
return ncclInvalidUsage;
}
// Proxy
proxyArgs.channel = channel;
// Adjust pattern for CollNet based on channel index
if (nSubChannels == 2) {
info->pattern = (channelId < info->comm->nChannels/nSubChannels) ? ncclPatternCollTreeUp : ncclPatternCollTreeDown;
}
if (info->coll == ncclCollSendRecv) {
info->comm->myParams->gridDim.x = std::max<unsigned>(info->comm->myParams->gridDim.x, channelId+1);
NCCLCHECK(ncclProxySaveP2p(info, channel));
} else {
NCCLCHECK(ncclProxySaveColl(&proxyArgs, info->pattern, info->root, info->comm->nRanks));
}
info->comm->myParams->gridDim.x++;
int opIndex = channel->collFifoTail;
struct ncclColl* c = channel->collectives+opIndex;
volatile uint8_t* activePtr = (volatile uint8_t*)&c->active;
while (activePtr[0] != 0) sched_yield();
memcpy(c, &coll, sizeof(struct ncclColl));
if (info->coll != ncclCollSendRecv) c->args.coll.bid = bid % coll.args.coll.nChannels;
c->active = 1;
opIndex = (opIndex+1)%NCCL_MAX_OPS;
c->nextIndex = opIndex;
channel->collFifoTail = opIndex;
channel->collCount++;
}
info->comm->opCount++;
return ncclSuccess;
}
The core here is computeColl, which adds kernel parameter information to the channel’s collectives through computeColl, and updates myParams->gridDim.x, meaning one channel corresponds to one block.
static ncclResult_t computeColl(struct ncclInfo* info /* input */, struct ncclColl* coll, struct ncclProxyArgs* proxyArgs /* output */) {
coll->args.sendbuff = info->sendbuff;
coll->args.recvbuff = info->recvbuff;
coll->args.comm = info->comm->devComm;
if (info->coll == ncclCollSendRecv) {
coll->args.p2p.sendCount = info->sendbytes;
coll->args.p2p.recvCount = info->recvbytes;
coll->args.p2p.delta = info->delta;
coll->funcIndex = FUNC_INDEX_P2P;
coll->args.p2p.nThreads = info->nThreads = info->comm->maxThreads[NCCL_ALGO_RING][NCCL_PROTO_SIMPLE]+2*WARP_SIZE;
return ncclSuccess;
}
// Set nstepsPerLoop and nchunksPerLoop
NCCLCHECK(getAlgoInfo(info));
NCCLCHECK(getPatternInfo(info));
NCCLCHECK(getLoopInfo(info));
...
}
nccl supports three protocols: NCCL_PROTO_LL, NCCL_PROTO_LL128, and NCCL_PROTO_SIMPLE, and three algorithms: NCCL_ALGO_TREE, NCCL_ALGO_RING, and NCCL_ALGO_COLLNET. getAlgoInfo will iterate through combinations of these three algorithms and three protocols to select the best algorithm and protocol. We’ll look at how this selection works when we discuss tree allreduce later. For now, let’s assume the selected protocol is NCCL_PROTO_SIMPLE and algorithm is NCCL_ALGO_RING.
getPatternInfo will set info->pattern to ncclPatternRingTwice.
getLoopInfo will set nstepsPerLoop and nchunksPerLoop.
info->nstepsPerLoop = 2*(info->comm->nRanks-1); info->nchunksPerLoop = info->comm->nRanks;
Let’s look at the meaning of these variables mentioned above:
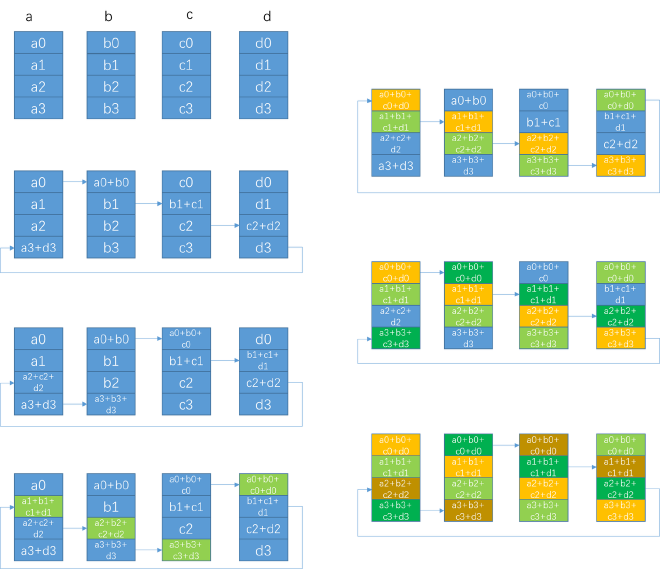
Figure 2#
The ring allreduce process for n ranks is shown above (image from here). Suppose we need to allreduce 100M of data, the execution process will be divided into multiple loops, with each loop processing say 4M of data. The figure shows one loop cycle of allreduce, where (a0+a1+a2+a3) is 4M in length. This loop cycle is divided into reduce scatter on the left and allgather on the right. In each step, each rank sends/receives 1/n of this data block, i.e., 1M length, like a0. So nchunksPerLoop = nRanks, indicating how many data blocks one loop cycle is divided into, with one data block called a chunk. Because it executes reduce scatter and allgather twice through the ring process, the pattern is called ncclPatternRingTwice, and nstepsPerLoop = 2*(info->comm->nRanks-1), indicating how many steps need to be executed in one loop cycle, with reduce scatter executing nRank - 1 steps and allgather executing nRanks - 1 steps.
launch kernel#
Then execute ncclBarrierEnqueue, where the core is copying the first ncclColl of the first channel to comm->args through setupLaunch, then launching the kernel through ncclLaunchCooperativeKernelMultiDevice.
ncclResult_t ncclBarrierEnqueue(struct ncclComm* comm) {
struct cudaLaunchParams* params = comm->myParams;
if (params->gridDim.x == 0) return ncclSuccess;
NCCLCHECK(setupLaunch(comm, params));
// Use internal NCCL stream for CGMD/GROUP launch if required or if the user stream is NULL
...
if (comm->launchMode == ncclComm::GROUP) {
int isLast = 0;
NCCLCHECK(ncclCpuBarrierIn(comm, &isLast));
if (isLast) {
// I'm the last. Launch all operations.
NCCLCHECK(ncclLaunchCooperativeKernelMultiDevice(comm->intraParams, comm->intraCudaDevs, comm->intraRanks, *comm->intraCGMode));
NCCLCHECK(ncclCpuBarrierLast(comm));
}
}
return ncclSuccess;
}
ring allreduce kernel#
Let’s look directly at the allreduce kernel. How it gets called can be referenced in section nine, which we won’t repeat here.
template<int UNROLL, class FUNC, typename T>
__device__ void ncclAllReduceRingKernel(struct CollectiveArgs* args) {
const int tid = threadIdx.x;
const int nthreads = args->coll.nThreads-WARP_SIZE;
const int bid = args->coll.bid;
const int nChannels = args->coll.nChannels;
struct ncclDevComm* comm = args->comm;
struct ncclChannel* channel = comm->channels+blockIdx.x;
struct ncclRing* ring = &channel->ring;
const int stepSize = comm->buffSizes[NCCL_PROTO_SIMPLE] / (sizeof(T)*NCCL_STEPS);
const int chunkSize = stepSize * ALLREDUCE_CHUNKSTEPS;
const int nranks = comm->nRanks;
const ssize_t loopSize = nChannels*(ssize_t)chunkSize;
const ssize_t size = args->coll.count;
// Compute pointers
const T * __restrict__ thisInput = (const T*)args->sendbuff;
T * __restrict__ thisOutput = (T*)args->recvbuff;
ncclPrimitives<UNROLL, ALLREDUCE_CHUNKSTEPS/ALLREDUCE_SLICESTEPS, ALLREDUCE_SLICESTEPS, T, 1, 1, 1, FUNC>
prims(tid, nthreads, &ring->prev, &ring->next, thisOutput, stepSize, channel, comm);
...
}
Similar to send/recv kernel, the allreduce kernel also has a dedicated warp for sync to reduce latency.
Then we’ll see several concepts: step, slice and chunk. The buffer is divided into NCCL_STEPS slots, where one slot is one step, so stepSize equals bufferSize / (sizeof(T) * NCCL_STEPS). As mentioned in figure 2, a rank sends/receives 1M data at a time - this 1M data is one chunk. Communication primitive ncclPrimitives APIs like directSend transfer one chunk of data at a time. A chunk has multiple steps, specifically ALLREDUCE_CHUNKSTEPS, so chunkSize equals stepSize * ALLREDUCE_CHUNKSTEPS. Within directSend, chunks are divided into multiple slices, where a slice also consists of multiple steps. In primitives, the actual granularity of data communication and synchronization is slice.
A kernel has nChannels blocks in total, so in one loop iteration a rank processes loopSize = nChannels * chunkSize length of data. sendbuff is the input data provided by user, recvbuff is the output data provided by user. Then initialize ncclPrimitives, where SLICESPERCHUNK indicates how many slices per chunk, slicesteps indicates how many steps per slice. NRECV indicates from how many places to receive data, NSEND indicates to how many places to send data. For ring allreduce, both NRECV and NSEND are 1. DIRECT indicates whether direct send/receive is supported, which will be explained later. In the constructor, recvPeers indicates where to receive from with length NRECV, which is the previous rank in the ring, sendPeers similarly.
template <int UNROLL, int SLICESPERCHUNK, int SLICESTEPS, typename T, int NRECV, int NSEND, int DIRECT, class FUNC>
class ncclPrimitives {
...
public:
__device__ __forceinline__
ncclPrimitives(const int tid, const int nthreads, int* recvPeers, int* sendPeers, T* directBuff, int stepSize, struct ncclChannel* channel, struct ncclDevComm* comm)
: comm(comm), tid(tid), nthreads(nthreads), wid(tid%WARP_SIZE), stepSize(stepSize) {
...
}
...
}
template<int UNROLL, class FUNC, typename T>
__device__ void ncclAllReduceRingKernel(struct CollectiveArgs* args) {
...
for (ssize_t gridOffset = 0; gridOffset < size; gridOffset += nranks*loopSize) {
ssize_t realChunkSize = min(chunkSize, DIVUP(size-gridOffset,nranks*nChannels));
ALIGN_SIZE(realChunkSize, nthreads*sizeof(uint64_t)/sizeof(T));
ssize_t chunkOffset = gridOffset + bid*nranks*realChunkSize;
/// begin AllReduce steps ///
ssize_t offset;
int nelem;
int chunk;
// step 0: push data to next GPU
chunk = ring->devUserRanks[nranks-1];
offset = chunkOffset + chunk * realChunkSize;
nelem = min(realChunkSize, size-offset);
prims.send(thisInput+offset, nelem);
...
}
Taking figure 2’s example, one block processes 1M data like a0 at a time, so 4 ranks can process 4M in total (a0+a1+a2+a3). The second block starts from a5, therefore all blocks of 4 ranks can process nranks*loopSize length of data in one loop iteration, so gridOffset increases by this amount each time.
Then start executing the first step of reduce scatter, sending data from user input thisInput to the next rank’s buffer. devUserRanks stores all ranks in the current ring sequentially starting from current rank. Different from figure 2, the first send is the data of the last rank in current ring - for example rank0 sends a3. We’ll follow the actual code from here. Then execute prims.send to send a3 to the next rank’s buffer.
template<int UNROLL, class FUNC, typename T>
__device__ void ncclAllReduceRingKernel(struct CollectiveArgs* args) {
...
for (ssize_t gridOffset = 0; gridOffset < size; gridOffset += nranks*loopSize) {
...
// k-2 steps: reduce and copy to next GPU
for (int j=2; j<nranks; ++j) {
chunk = ring->devUserRanks[nranks-j];
offset = chunkOffset + chunk * realChunkSize;
nelem = min(realChunkSize, size-offset);
prims.recvReduceSend(thisInput+offset, nelem);
}
// step k-1: reduce this buffer and data, which will produce the final
// result that we store in this data and push to the next GPU
chunk = ring->devUserRanks[0];
offset = chunkOffset + chunk * realChunkSize;
nelem = min(realChunkSize, size-offset);
prims.directRecvReduceCopySend(thisInput+offset, thisOutput+offset, offset, nelem);
...
}
}
Then continue executing nranks - 2 steps of reduce scatter process. Each time use recvReduceSend to reduce the received data in own buffer with data in thisInput, like summation, then send the result to next rank’s buffer. Taking rank0 as example, finally rank0 uses directRecvReduceCopySend to reduce a0 with data sent from prev rank, then sends to next rank’s buffer and thisOutput. At this point reduce scatter is complete - each rank has obtained a complete piece of data, for example rank0 has complete data corresponding to a0, and has copied its corresponding complete data to next rank’s buffer and user API input recvbuff.
template<int UNROLL, class FUNC, typename T>
__device__ void ncclAllReduceRingKernel(struct CollectiveArgs* args) {
...
for (ssize_t gridOffset = 0; gridOffset < size; gridOffset += nranks*loopSize) {
...
// k-2 steps: copy to next GPU
for (int j=1; j<nranks-1; ++j) {
chunk = ring->devUserRanks[nranks-j];
offset = chunkOffset + chunk * realChunkSize;
nelem = min(realChunkSize, size-offset);
prims.directRecvCopySend(thisOutput+offset, offset, nelem);
}
// Make final copy from buffer to dest.
chunk = ring->devUserRanks[1];
offset = chunkOffset + chunk * realChunkSize;
nelem = min(realChunkSize, size-offset);
// Final wait/copy.
prims.directRecv(thisOutput+offset, offset, nelem);
}
}
Then start executing allgather, first executing nranks - 2 steps of directRecvCopySend, sending nelem length data from current buffer to next rank’s buffer and user API input recvbuff. The nranks - 1 step uses directRecv to send nelem length data from current buffer to user API input recvbuff, no need to send to next rank anymore.
This completes the execution of ring allreduce kernel. Next let’s look at the ncclPrimitives APIs used in ring allreduce kernel.
ncclPrimitives#
Section nine introduced how ncclPrimitives sends/receives data and synchronizes, but send/recv scenarios only used directSend and directRecv. Here we’ll mainly introduce the roles of various ncclPrimitives APIs in ring allreduce scenarios.
ncclPrimitives APIs all use GenericOp, whose core function is to create srcs and dsts arrays based on parameters, then reduce the srcs array and copy the reduction result to each output in dsts.
template <int DIRECTRECV, int DIRECTSEND, int RECV, int SEND, int SRC, int DST>
inline __device__ void
GenericOp(const T* srcPtr, T* dstPtr, int nelem, ssize_t directOffset) {
int offset = 0;
int sliceSize = stepSize*SLICESTEPS;
int dataSize = max(DIVUP(nelem, 16*SLICESPERCHUNK)*16, sliceSize/32);
const T* srcs[RECV*NRECV+SRC];
srcs[0] = SRC ? srcPtr : directRecvPtr<DIRECTRECV>(0, directOffset);
if (RECV) {
if (SRC) srcs[1] = recvPtr(0);
for (int i=1; i<NRECV && i<nrecv; i++) srcs[SRC+i] = recvPtr(i);
}
T* dsts[SEND*NSEND+DST];
dsts[0] = DST ? dstPtr : directSendPtr<DIRECTSEND>(0, directOffset);
if (SEND) {
if (DST) dsts[1] = directSendPtr<DIRECTSEND>(0, directOffset);
for (int i=1; i<NSEND && i<nsend; i++) dsts[DST+i] = directSendPtr<DIRECTSEND>(i, directOffset);
}
...
}
In template parameters, RECV indicates whether receive is needed, SEND indicates whether send is needed, SRC indicates whether srcs array has parameter srcPtr. If SRC is non-zero, first element in srcs array is srcPtr and second is previous rank’s buffer. If SRC is 0, srcs only has one element - the previous GPU’s buffer. DST works similarly.
DIRECTSEND and DIRECTRECV have no difference in this scenario, we’ll ignore for now and explain shortly.
api#
send
__device__ __forceinline__ void
send(const T* src, int nelem) {
GenericOp<0, 0, 0, 1, 1, 0>(src, NULL, nelem, 0);
}
For send interface, SEND and SRC are 1, so srcs array only has src, dsts array only has next rank’s buffer. Therefore send’s function is to send nelem length data from src to next rank’s buffer.
recvReduceSend
__device__ __forceinline__ void
recvReduceSend(const T* src, int nelem) {
GenericOp<0, 0, 1, 1, 1, 0>(src, NULL, nelem, 0);
}
Both SRC and RECV are 1, so srcs array contains src and previous rank’s buffer. SEND is 1 but DST is 0, so dsts array only has next rank’s buffer. Therefore recvReduceSend’s function is to reduce nelem length data from src with data sent from prev rank, then send to next rank’s buffer.
directRecvReduceCopySend
__device__ __forceinline__ void
directRecvReduceCopySend(const T* src, T* dst, ssize_t directOffset, int nelem) {
// Direct is only for the send part
GenericOp<0, 1, 1, 1, 1, 1>(src, dst, nelem, directOffset);
}
Both SRC and RECV are 1, so srcs array contains src and current rank’s buffer. Both SEND and DST are 1, so dsts array contains dst and next rank’s buffer. Therefore directRecvReduceCopySend’s function is to reduce nelem length data from src with data sent to current buffer from prev rank, then send to next rank’s buffer and dst.
directRecvCopySend
__device__ __forceinline__ void
directRecvCopySend(T* dst, ssize_t directOffset, int nelem) {
GenericOp<1, 1, 1, 1, 0, 1>(NULL, dst, nelem, directOffset);
}
Since SRC is 0 and others are 1, srcs array only has current rank’s buffer, dsts array contains dst and next rank’s buffer. Therefore directRecvCopySend’s function is to copy received data from current rank buffer to dst and next rank’s buffer.
directRecv
__device__ __forceinline__ void
directRecv(T* dst, ssize_t directOffset, int nelem) {
GenericOp<1, 0, 1, 0, 0, 1>(NULL, dst, nelem, directOffset);
}
Since RECV is 1 and SRC is 0, srcs only has current rank’s buffer. DST is 1 so dsts array contains dst. Therefore directRecv’s function is to copy received data from current rank’s buffer to dst.
direct#
Let’s explain the previously mentioned role of “direct”. For example, when rank0 executes send and rank1 executes recv, rank0 copies data from src to rank1’s buffer, and rank1 copies data from buffer to dst. However, with directSend, it might bypass rank1’s buffer and send directly to dst. Let’s review the transport establishment to understand why it’s only a possibility and how rank0 knows where dst is.
struct ncclSendMem {
union {
struct {
uint64_t head;
char pad1[CACHE_LINE_SIZE-sizeof(uint64_t)];
void* ptrExchange;
char pad2[CACHE_LINE_SIZE-sizeof(void*)];
};
char pad3[MEM_ALIGN];
};
char buff[1]; // Actually larger than that
};
The send side has a variable called ptrExchange.
static ncclResult_t p2pSendConnect(struct ncclConnect* connectInfo, int nranks, int rank, struct ncclConnector* send) {
...
send->conn.ptrExchange = &resources->devMem->ptrExchange;
}
ncclResult_t p2pRecvConnect(struct ncclConnect* connectInfo, int nranks, int rank, struct ncclConnector* recv) {
...
if (info->direct) {
remDevMem = (struct ncclSendMem*)(info->directPtr);
if (info->read == 0) {
recv->conn.direct |= NCCL_DIRECT_GPU;
recv->conn.ptrExchange = &remDevMem->ptrExchange;
}
}
...
}
During the connection process between send and recv sides, the recv side saves the send side’s ptrExchange.
__device__ __forceinline__ void loadSendConn(struct ncclConnInfo* conn, int i) {
sendBuff[i] = (T*)conn->buffs[NCCL_PROTO_SIMPLE];
...
if (DIRECT && (conn->direct & NCCL_DIRECT_GPU)) {
void* volatile* ptr = conn->ptrExchange;
while ((sendDirectBuff[i] = (T*)(*ptr)) == NULL);
barrier();
if (tid == 0) *ptr = NULL;
}
...
}
__device__ __forceinline__ void loadRecvConn(struct ncclConnInfo* conn, int i, T* directBuff) {
recvBuff[i] = (const T*)conn->buffs[NCCL_PROTO_SIMPLE];
...
if (DIRECT && (conn->direct & NCCL_DIRECT_GPU)) {
recvDirectBuff[i] = directBuff;
if (tid == 0) *conn->ptrExchange = directBuff;
}
...
}
Then when ncclPrimitives loads the conn, the recv side writes directBuff (i.e., dst) to ptrExchange, so the send side knows where dst is.
We can also see the limitations: direct is only supported when info->direct == 1 and info->read == 0, meaning it must be within the same process and using p2p write. In our scenario, we used p2p read, so direct was ignored.
Multi-machine
The actual communication process for multi-machine is consistent with the multi-machine send/recv in section ten. Let’s focus on the differences.
Initialization#
Assuming the ring searched by ncclTopoCompute for a single machine is:
NET/0 GPU/0 GPU/1 GPU/2 GPU/3 GPU/4 GPU/5 GPU/6 GPU/7 NET/0
Compared to a single-machine ring, it becomes a chain with network cards added at both ends. The chain building process just adds inter-machine connections, which we won’t elaborate on.
ncclSaveKernel#
ncclResult_t ncclSaveKernel(struct ncclInfo* info) {
...
struct ncclColl coll;
struct ncclProxyArgs proxyArgs;
memset(&proxyArgs, 0, sizeof(struct ncclProxyArgs));
NCCLCHECK(computeColl(info, &coll, &proxyArgs));
...
for (int bid=0; bid<nChannels*nSubChannels; bid++) {
...
// Proxy
proxyArgs.channel = channel;
// Adjust pattern for CollNet based on channel index
if (nSubChannels == 2) {
info->pattern = (channelId < info->comm->nChannels/nSubChannels) ? ncclPatternCollTreeUp : ncclPatternCollTreeDown;
}
if (info->coll == ncclCollSendRecv) {
info->comm->myParams->gridDim.x = std::max<unsigned>(info->comm->myParams->gridDim.x, channelId+1);
NCCLCHECK(ncclProxySaveP2p(info, channel));
} else {
NCCLCHECK(ncclProxySaveColl(&proxyArgs, info->pattern, info->root, info->comm->nRanks));
}
...
}
info->comm->opCount++;
return ncclSuccess;
}
The only differences in ncclSaveKernel are computeColl and ncclProxySaveColl.
computeColl#
static ncclResult_t computeColl(struct ncclInfo* info /* input */, struct ncclColl* coll, struct ncclProxyArgs* proxyArgs /* output */) {
...
int stepSize = info->comm->buffSizes[info->protocol]/NCCL_STEPS;
int chunkSteps = (info->protocol == NCCL_PROTO_SIMPLE && info->algorithm == NCCL_ALGO_RING) ? info->chunkSteps : 1;
int sliceSteps = (info->protocol == NCCL_PROTO_SIMPLE && info->algorithm == NCCL_ALGO_RING) ? info->sliceSteps : 1;
int chunkSize = stepSize*chunkSteps;
...
// Compute nSteps for proxies
int chunkEffectiveSize = chunkSize;
if (info->protocol == NCCL_PROTO_LL) chunkEffectiveSize /= 2;
if (info->protocol == NCCL_PROTO_LL128) chunkEffectiveSize = (chunkSize / NCCL_LL128_LINEELEMS) * NCCL_LL128_DATAELEMS;
int nLoops = (int)(DIVUP(info->nBytes, (((size_t)(info->nChannels))*info->nchunksPerLoop*chunkEffectiveSize)));
proxyArgs->nsteps = info->nstepsPerLoop * nLoops * chunkSteps;
proxyArgs->sliceSteps = sliceSteps;
proxyArgs->chunkSteps = chunkSteps;
proxyArgs->protocol = info->protocol;
proxyArgs->opCount = info->comm->opCount;
proxyArgs->dtype = info->datatype;
proxyArgs->redOp = info->op;
...
return ncclSuccess;
}
nLoops represents the total number of loops. As shown in figure 2, a chunk is a0 with size chunkEffectiveSize. One execution can process nchunksPerLoop*chunkEffectiveSize of data (i.e., a0+a1+a2+a3). There are nChannels in total, so multiply the data processed in one execution by nChannels, then divide by nBytes to calculate how many loops need to be executed.
Then calculate nsteps, representing the total number of steps. A step is a slot in the buff. Since processing one chunk sends data nstepsPerLoop times, and one chunk has chunkSteps steps, with nLoops cycles in total, nsteps equals nstepsPerLoop * nLoops * chunkSteps.
So proxy knows how many times to send data through this information in proxyArgs.
ncclProxySaveColl#
Then add each channel’s proxyArgs to the comm’s args linked list
ncclResult_t ncclProxySaveColl(struct ncclProxyArgs* args, int pattern, int root, int nranks) {
if (pattern == ncclPatternRing || pattern == ncclPatternRingTwice || pattern == ncclPatternPipelineFrom || pattern == ncclPatternPipelineTo) {
struct ncclRing* ring = &args->channel->ring;
if (NeedProxy(RECV, pattern, root, ring, nranks)) NCCLCHECK(SaveProxy<proxyRecv>(ring->prev, args));
if (NeedProxy(SEND, pattern, root, ring, nranks)) NCCLCHECK(SaveProxy<proxySend>(ring->next, args));
}
...
}
NeedProxy always returns true, then executes SaveProxy
template <int type>
static ncclResult_t SaveProxy(int peer, struct ncclProxyArgs* args) {
if (peer < 0) return ncclSuccess;
struct ncclPeer* peerComm = args->channel->peers+peer;
struct ncclConnector* connector = type == proxyRecv ? &peerComm->recv : &peerComm->send;
if (connector->transportComm == NULL) {
WARN("[%d] Error no transport for %s peer %d on channel %d\n", connector->comm->rank,
type == proxyRecv ? "recv" : "send", peer, args->channel->id);
return ncclInternalError;
}
if (connector->transportComm->proxy == NULL) return ncclSuccess;
struct ncclProxyArgs* op;
NCCLCHECK(allocateArgs(connector->comm, &op));
memcpy(op, args, sizeof(struct ncclProxyArgs));
op->connector = connector;
op->progress = connector->transportComm->proxy;
op->state = ncclProxyOpReady;
ProxyAppend(connector, op);
return ncclSuccess;
}
Since only rank7’s send is netTransport during connection establishment, only rank7’s send will execute ProxyAppend, and similarly only rank0’s recv will execute ProxyAppend.
Data Sending#
We won’t elaborate on ProxyAppend again - it just adds args to the linked list in comm. After launching the kernel, it will wake up the proxy thread. The proxy traverses this list and executes corresponding operations, taking send as an example.
ncclResult_t netSendProxy(struct ncclProxyArgs* args) {
struct netSendResources* resources = (struct netSendResources*) (args->connector->transportResources);
if (args->state == ncclProxyOpReady) {
// Round to next multiple of sliceSteps
resources->step = ROUNDUP(resources->step, args->chunkSteps);
args->head = resources->step;
args->tail = resources->step;
args->end = args->head + args->nsteps;
args->state = ncclProxyOpProgress;
}
if (args->state == ncclProxyOpProgress) {
int p = args->protocol;
int stepSize = args->connector->comm->buffSizes[p] / NCCL_STEPS;
char* localBuff = args->connector->conn.buffs[p];
void* mhandle = *(resources->mhandlesProto[p]);
args->idle = 1;
if (args->head < args->end) {
int buffSlot = args->tail%NCCL_STEPS;
if (args->tail < args->end && args->tail < args->head + NCCL_STEPS) {
volatile int* sizesFifo = resources->recvMem->sizesFifo;
volatile uint64_t* recvTail = &resources->recvMem->tail;
...
else if (args->tail < *recvTail) {
// Send through network
if (sizesFifo[buffSlot] != -1) {
NCCLCHECK(ncclNetIsend(resources->netSendComm, localBuff+buffSlot*stepSize, sizesFifo[buffSlot], mhandle, args->requests+buffSlot));
if (args->requests[buffSlot] != NULL) {
sizesFifo[buffSlot] = -1;
// Make sure size is reset to zero before we update the head.
__sync_synchronize();
args->tail += args->sliceSteps;
args->idle = 0;
}
}
}
}
if (args->head < args->tail) {
int done;
int buffSlot = args->head%NCCL_STEPS;
NCCLCHECK(ncclNetTest(args->requests[buffSlot], &done, NULL));
if (done) {
args->head += args->sliceSteps;
resources->sendMem->head = args->head;
args->idle = 0;
}
}
}
if (args->head == args->end) {
resources->step = args->end;
args->idle = 0;
args->state = ncclProxyOpNone;
}
}
return ncclSuccess;
}
We can see that end is calculated through nsteps, so proxy knows how many slots the entire algorithm flow needs. Since primitives actually sends sliceSteps slots at a time, the movement of head and tail is always sliceSteps.