gemini-2.5-flash-preview-04-17 translation of a Chinese article. Beware of potential errors.We know that in RoPE, the formula for frequency is $\theta_i = b^{-2i/d}$, and the default value for the base $b$ is 10000. One of the mainstream approaches for Long Context now is to first pretrain with short texts using $b=10000$, and then fine-tune with long texts while increasing $b$. The rationale behind this is the NTK-RoPE introduced in 《Path to Transformer Upgrade: 10. RoPE is a β-ary Encoding》, which itself has good length extrapolation properties. Using a larger $b$ for fine-tuning, compared to fine-tuning without modification, results in a smaller initial loss and faster convergence. This process gives the impression that increasing $b$ is solely due to the “short-first, then long” training strategy. If long texts were used for training throughout, would there be no need to increase $b$?
Last week’s paper 《Base of RoPE Bounds Context Length》 attempts to answer this question. Based on an expected property, it studies the lower bound of $b$, thereby suggesting that a larger training length itself should warrant the choice of a larger base, regardless of the training strategy. The entire analysis line of thought is quite insightful, so let’s appreciate it together.
Expected Property#
We won’t go into detailed introductions of RoPE here. It is essentially a block diagonal matrix:
$$ \boldsymbol{\mathcal{R}}_n = \left(\begin{array}{cc:cc:cc:cc} \cos n\theta_0 & -\sin n\theta_0 & 0 & 0 & \cdots & \cdots & 0 & 0 \\ \sin n\theta_0 & \cos n\theta_0 & 0 & 0 & \cdots & \cdots & 0 & 0 \\ \hdashline 0 & 0 & \cos n\theta_1 & -\sin n\theta_1 & \cdots & \cdots & 0 & 0 \\ 0 & 0 & \sin n\theta_1 & \cos n\theta_1 & \cdots & \cdots & 0 & 0 \\ \hdashline \vdots & \vdots & \vdots & \vdots & \ddots & \ddots & \vdots & \vdots \\ \vdots & \vdots & \vdots & \vdots & \ddots & \ddots & \vdots & \vdots \\ \hdashline 0 & 0 & 0 & 0 & \cdots & \cdots & \cos n\theta_{d/2-1} & -\sin n\theta_{d/2-1} \\ 0 & 0 & 0 & 0 & \cdots & \cdots & \sin n\theta_{d/2-1} & \cos n\theta_{d/2-1} \\ \end{array}\right) $$Then using the identity
$$ (\boldsymbol{\mathcal{R}}_m \boldsymbol{q})^{\top}(\boldsymbol{\mathcal{R}}_n \boldsymbol{k}) = \boldsymbol{q}^{\top} \boldsymbol{\mathcal{R}}_m^{\top}\boldsymbol{\mathcal{R}}_n \boldsymbol{k} = \boldsymbol{q}^{\top} \boldsymbol{\mathcal{R}}_{n-m} \boldsymbol{k} $$absolute position information is injected into $\boldsymbol{q}, \boldsymbol{k}$, automatically achieving the effect of relative positions. Here $\theta_i = b^{-2i/d}$, and the choice of $b$ is the issue discussed in this paper.
Besides injecting position information into the model, we expect RoPE to possess two desirable properties for better performance: 1. Remote Decay: Tokens close in position should, on average, receive more attention; 2. Semantic Aggregation: Tokens similar in meaning should, on average, receive more attention. The first point was discussed in 《Path to Transformer Upgrade: 2. Rotary Position Encoding, a Collection of Strengths》, where RoPE indeed shows some remote decay property.
So next, let’s analyze the second point.
Inequality Relation#
Semantic aggregation means that when $\boldsymbol{k}$ is close to $\boldsymbol{q}$, regardless of their relative distance $n-m$, their attention $\boldsymbol{q}^{\top} \boldsymbol{\mathcal{R}}_{n-m} \boldsymbol{k}$ should be larger on average (at least greater than that between two random tokens). To obtain a quantitative conclusion, let’s further simplify the problem. Assume each component of $\boldsymbol{q}$ is independently and identically distributed, with a mean of $\mu$ and a variance of $\sigma^2$.
Now consider two different types of $\boldsymbol{k}$: one is based on $\boldsymbol{q}$ with the addition of a zero-mean perturbation $\boldsymbol{\varepsilon}$, denoted as $\tilde{\boldsymbol{k}} = \boldsymbol{q} + \boldsymbol{\varepsilon}$, representing a token semantically similar to $\boldsymbol{q}$; the other assumes $\boldsymbol{k}$ is independently and identically distributed as $\boldsymbol{q}$, representing two random tokens. According to the second desirable property, we hope to have
$$ \mathbb{E}_{\boldsymbol{q},\boldsymbol{k},\boldsymbol{\varepsilon}}\big[\boldsymbol{q}^{\top} \boldsymbol{\mathcal{R}}_{n-m} \tilde{\boldsymbol{k}} - \boldsymbol{q}^{\top} \boldsymbol{\mathcal{R}}_{n-m} \boldsymbol{k}\big] \geq 0 $$Note that we repeatedly emphasized “on average,” meaning we only expect an average trend, not strict inequality at every point. Thus, we added the mathematical expectation $\mathbb{E}_{\boldsymbol{q},\boldsymbol{k},\boldsymbol{\varepsilon}}$ to the above expression. Now, based on our assumptions and the definition of RoPE, we can explicitly calculate the expression:
$$ \begin{aligned} &\,\mathbb{E}_{\boldsymbol{q},\boldsymbol{k},\boldsymbol{\varepsilon}}\big[\boldsymbol{q}^{\top} \boldsymbol{\mathcal{R}}_{n-m} (\boldsymbol{q} + \boldsymbol{\varepsilon}) - \boldsymbol{q}^{\top} \boldsymbol{\mathcal{R}}_{n-m} \boldsymbol{k}\big] \\[5pt] =&\, \mathbb{E}_{\boldsymbol{q}}\big[\boldsymbol{q}^{\top} \boldsymbol{\mathcal{R}}_{n-m} \boldsymbol{q}\big] - \mathbb{E}_{\boldsymbol{q},\boldsymbol{k}}\big[\boldsymbol{q}^{\top} \boldsymbol{\mathcal{R}}_{n-m} \boldsymbol{k}\big] \\[5pt] =&\, \mathbb{E}_{\boldsymbol{q}}\big[\boldsymbol{q}^{\top} \boldsymbol{\mathcal{R}}_{n-m} \boldsymbol{q}\big] - \mathbb{E}_{\boldsymbol{q}}[\boldsymbol{q}]^{\top}\boldsymbol{\mathcal{R}}_{n-m} \mathbb{E}_{\boldsymbol{k}}[\boldsymbol{k}] \\[5pt] =&\, \mathbb{E}_{\boldsymbol{q}}\big[\boldsymbol{q}^{\top} \boldsymbol{\mathcal{R}}_{n-m} \boldsymbol{q}\big] - \mu^2\boldsymbol{1}^{\top}\boldsymbol{\mathcal{R}}_{n-m} \boldsymbol{1} \\[5pt] =& \mathbb{E}_{\boldsymbol{q}}\left[\sum_{i=0}^{d/2-1} (q_{2i}^2 + q_{2i+1}^2)\cos (n-m)\theta_i\right] - \sum_{i=0}^{d/2-1} 2\mu^2\cos (n-m)\theta_i \\[5pt] =& \sum_{i=0}^{d/2-1} 2(\mu^2 + \sigma^2)\cos (n-m)\theta_i - \sum_{i=0}^{d/2-1} 2\mu^2\cos (n-m)\theta_i \\[5pt] =& \sum_{i=0}^{d/2-1} 2\sigma^2\cos (n-m)\theta_i \\ \end{aligned} $$If the maximum training length is $L$, then $n-m\leq L-1$. Therefore, the second desirable property can be approximately described by the following inequality:
$$ \sum_{i=0}^{d/2-1} \cos m\theta_i \geq 0,\quad m\in\{0,1,2,\cdots,L-1\} $$Here $L$ is the maximum length, a hyperparameter chosen before training, and $d$ is the model’s head_size. According to the typical LLAMA setup, $d=128$. This means that the only tunable parameter in the above expression is $b$ from $\theta_i = b^{-2i/d}$. In 《Path to Transformer Upgrade: 1. Tracing the Origin of Sinusoidal Position Encoding》, we briefly explored this function. Its overall trend is decaying; a larger $b$ means a slower decay rate, and a larger corresponding continuous non-negative interval. Thus, there exists a minimum $b$ such that the above inequality holds for all $m$, specifically:
$$ b^* = \inf\left\{\,\,b\,\,\,\left|\,\,\,f_b(m)\triangleq\sum_{i=0}^{d/2-1} \cos m b^{-2i/d} \geq 0,\,\, m\in\{0,1,2,\cdots,L-1\}\right.\right\} $$Numerical Solution#
Since $f_b(m)$ involves the summation of multiple trigonometric functions, and $\theta_i$ is non-linear with respect to $i$, it’s hard to imagine an analytical solution for the above problem. Therefore, we must resort to numerical methods. However, $f_b(m)$ oscillates more frequently and irregularly as $m$ increases, making even numerical solution non-trivial.
The author initially thought that if $b_0$ ensures $f_{b_0}(m)\geq 0$ holds for all $m$, then $\forall b \geq b_0$, $f_b(m)\geq 0$ would also hold, allowing for a binary search. However, this assumption is incorrect, so binary search fails. After thinking for a while, there were still no significant optimization ideas. During this time, the author consulted the original paper’s authors, who used an inverse function approach. That is, given $b$, it is relatively simple to find the maximum $L$ for which $f_b(m)\geq 0$ holds for all $m \in \{0, \dots, L-1\}$. This way, many $(b, L)$ pairs can be obtained. Theoretically, by enumerating enough $b$ values, one can find the minimum $b$ for any given $L$. However, there is a precision issue here. In the original paper, the maximum $L$ calculated was up to $10^6$, requiring $b$ to be enumerated up to at least $10^8$. If the enumeration step is small, the computation cost is very high. If the step is large, many solutions might be missed.
Finally, the author decided to use “Jax + GPU” for a brute-force search to obtain higher precision results. The general process is:
Initialize $b=1000L$ (within $10^6$, $b=1000L$ makes $f_b(m)\geq 0$ hold for all $m$).
Iterate $k=1,2,3,4,5$, performing the following operations:
2.1) Divide $[0,b]$ into $10^k$ equal parts. Iterate through the division points and check if $f_b(m)\geq 0$ holds for all $m$.
2.2) Take the smallest division point that makes $f_b(m)\geq 0$ hold for all $m$, and update $b$.
- Return the final $b$.
The final results are generally tighter than those in the original paper.
| L | 1k | 2k | 4k | 8k | 16k | 32k | 64k | 128k | 256k | 512k | 1M |
|---|---|---|---|---|---|---|---|---|---|---|---|
| $b^*(\text{Original Paper})$ | 4.3e3 | 1.6e4 | 2.7e4 | 8.4e4 | 3.1e5 | 6.4e5 | 2.1e6 | 7.8e6 | 3.6e7 | 6.4e7 | 5.1e8 |
| $b^*(\text{This Article})$ | 4.3e3 | 1.2e4 | 2.7e4 | 8.4e4 | 2.3e5 | 6.3e5 | 2.1e6 | 4.9e6 | 2.4e7 | 5.8e7 | 6.5e7 |
Reference code:
| |
Asymptotic Estimation#
Besides numerical solutions, we can also obtain an analytical estimate through asymptotic analysis. This estimate is smaller than the numerical results, essentially being the solution as $d\to\infty$, but it also leads to the conclusion that “$b$ should increase as $L$ increases”.
The idea of asymptotic estimation is to replace the summation with an integral:
$$ f_b(m) = \sum_{i=0}^{d/2-1} \cos m b^{-2i/d}\approx \int_0^1 \cos m b^{-s} ds \xlongequal{\text{let }t = mb^{-s}} \int_{mb^{-1}}^m \frac{\cos t}{t \ln b}dt $$where we define
$$ \text{Ci}(x) = -\int_x^{\infty} \frac{\cos t}{t} dt $$This is a well-studied trigonometric integral (refer to Trigonometric integral). Using this notation, we can write
$$ f_b(m) \approx \frac{\text{Ci}(m) - \text{Ci}(mb^{-1})}{\ln b} $$The graph of $\text{Ci}(x)$ looks like this:
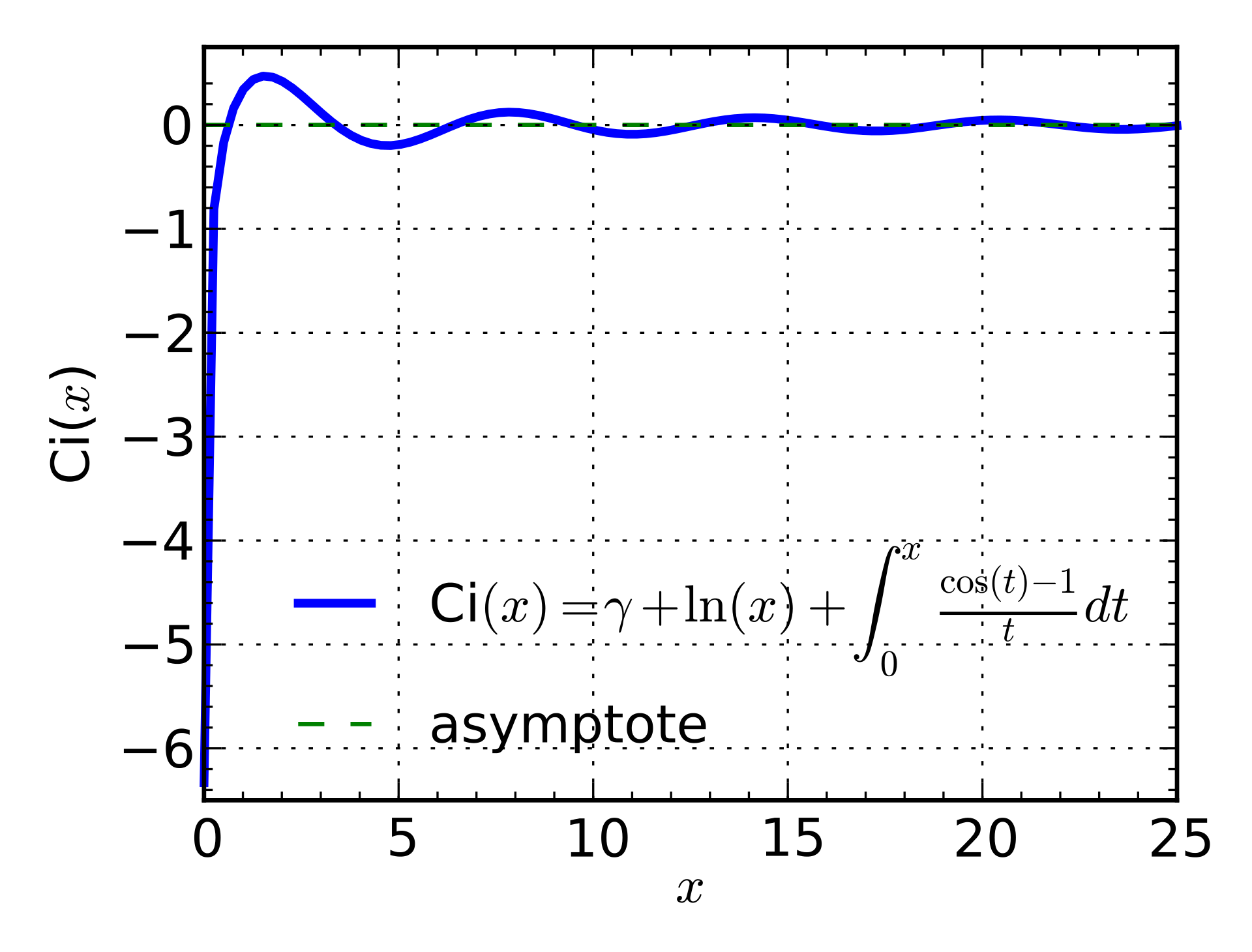
Its first zero is $x_0=0.6165\cdots$. For $m\geq 1$, we can see that $|\text{Ci}(m)|\leq 1/2$, so $\text{Ci}(m)$ is a relatively small term and can be ignored for asymptotic estimation. The problem then approximately becomes $\text{Ci}(mb^{-1})\leq 0$ holding for $m=1,2,\cdots,L$. We only need to ensure that the corresponding $mb^{-1}$ values all fall within the interval $[0,x_0]$. This implies $Lb^{-1}\leq x_0$, which means
$$ b \geq L / x_0 \approx 2L $$Or simply $b^* = \mathcal{O}(L)$. As expected, this result is smaller than the precise numerical results because it corresponds to $d\to\infty$. The superposition of infinitely many trigonometric functions makes the function graph less oscillatory and seemingly smoother (compared to finite $d$), thus, for a fixed $b$, the continuous non-negative interval of $f_b(m)$ is longer, or conversely, for a fixed $L$, the $b$ that keeps $f_b(m)$ non-negative for $m=0,1,2,\cdots,L-1$ is smaller.
Related Considerations#
In 《Path to Transformer Upgrade: 10. RoPE is a β-ary Encoding》, we likened RoPE to a $\beta$-ary representation, where $\beta = b^{2/d}$. Then $b - 1= \beta^{d/2} - 1$ is precisely the maximum number that a $d/2$-digit $\beta$-ary encoding can represent. To represent the position encodings $0,1,2,\cdots,L-1$, which are $L$ distinct positions, we need at least $b \geq L$. This simple analogy once again yields the conclusion that “$b$ should increase as $L$ increases”, and its result is closer to the asymptotic analysis result from the previous section.
On the other hand, Meta’s recently released LLAMA3, with a training length of 8192, chose a surprisingly large RoPE base of 500000 (5e5). This is nearly an order of magnitude larger than the numerical result (8.4e4) from earlier. From any perspective, the author believes this value is on the larger side, possibly reserved by LLAMA3 for even greater text lengths. Regardless, choosing a larger RoPE base for greater text lengths seems to have become a consensus among many training practitioners.
In fact, both numerical results and asymptotic estimates are just reference values. In practice, for a given $L$, a relatively large range of $b$ values should yield similar effects. So the specific numerical values are not as important. The key is that the original paper, starting from the perspective of semantic aggregation and through a series of derivations, clarified the conclusion that “$b$ should increase as $L$ increases” and its principle. This is what the author considers the core contribution of the original paper.
Furthermore, the starting point and conclusions regarding semantic aggregation can also be used to explain Position Interpolation (PI). We just said that for the same $b$, the continuous non-negative interval of $f_b(m)$ is fixed. To ensure that $0,1,2,\cdots,L-1$ all fall within the non-negative interval, $b$ needs to be increased accordingly as $L$ increases. Conversely, we can also avoid increasing $b$ and instead reduce the interval between adjacent positions (i.e., change position IDs to $0,1/k,2/k,\cdots$). Then, within the same size non-negative interval, $k$ times the number of positions can be represented. This is Position Interpolation from the perspective of semantic aggregation.
Partial Rotation#
RoPE was proposed in 2021. At that time, there was only one Chinese blog post. Later, it gained recognition and was experimented on by the EleutherAI organization, and then gradually promoted to the academic community. EleutherAI experiments at the time found that applying RoPE only to a subset of dimensions yielded slightly better results. Related content can be found here, here, and here. Later, this operation was used in their GPT-NeoX.
Of course, partial rotation is not yet a mainstream choice for current LLMs, but this doesn’t prevent us from studying it. Perhaps it hasn’t become mainstream simply because we don’t understand it well enough. Why might partial rotation be better? The author finds that the conclusion of this paper can partially explain it. Taking the case of rotating only half the dimensions as an example, it is mathematically equivalent to choosing $\theta_i$ as follows:
$$ \theta_i = \left\{\begin{aligned}&b^{-4i/d},& i < d/4 \\ &0,&i \geq d/4\end{aligned}\right. $$In this case, we have
$$ \sum_{i=0}^{d/2-1} \cos m\theta_i = \sum_{i=0}^{d/4-1} \cos m b^{-4i/d} + \sum_{i=d/4}^{d/2-1} \cos m \cdot 0 = \sum_{i=0}^{d/4-1} \cos m b^{-4i/d} + d/4 $$The condition for semantic aggregation becomes $\sum_{i=0}^{d/4-1} \cos m b^{-4i/d} + d/4 \geq 0$. If we consider the inequality form $\sum_{i=0}^{d/2-1} (1+\cos m\theta_i)\geq 0$ as the desirable property (which is equivalent to the previous one for $m>0$), then for partial rotation:
$$ \sum_{i=0}^{d/2-1} (1+\cos m\theta_i) = \sum_{i=0}^{d/4-1} (1+\cos mb^{-4i/d}) + \sum_{i=d/4}^{d/2-1} (1+\cos m \cdot 0) = \sum_{i=0}^{d/4-1} (1+\cos mb^{-4i/d}) + d/4 $$Since $1+\cos(\cdot) \geq 0$, the first sum is non-negative. The second part $d/4$ is also positive. Thus, the expected inequality $\sum_{i=0}^{d/2-1} (1+\cos m\theta_i)\geq 0$ automatically holds regardless of $m, b$. This means that from the perspective of this paper, partial rotation has better semantic aggregation ability while imbuing position information, which might be more beneficial for the model’s performance. Simultaneously, partial rotation might also be more beneficial for the model’s long text capability because the inequality always holds. Thus, according to this paper’s viewpoint, there’s no need to modify $b$ regardless of whether training is done on short or long texts.
It is worth mentioning that DeepSeek’s proposed MLA also applies partial rotation. Although in the original derivation of MLA, partial rotation was more of a compromise to integrate RoPE, combined with previous partial rotation experimental results, perhaps partial rotation contributes partly to MLA’s excellent performance.
Summary (formatted)#
This article briefly introduced the paper 《Base of RoPE Bounds Context Length》. Starting from the expected property of semantic aggregation, it discussed the lower bound for RoPE’s base, thereby pointing out that a larger training length should require a larger base, not just as a compromise choice to reduce initial loss using NTK-RoPE in conjunction with the “short-first, then long” training strategy.
| |